 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Proximity Alignment: Towards Human Perception-consistent Audio Tagging by Aligning with Label Text Description
Paper and Code
Sep 28, 2023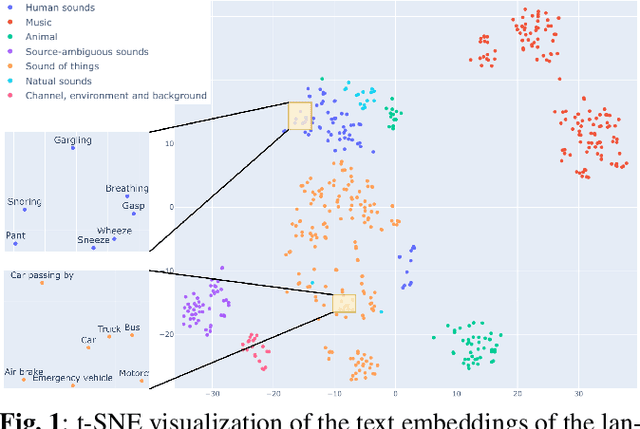
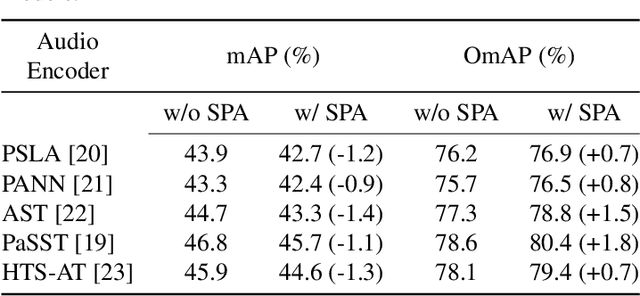
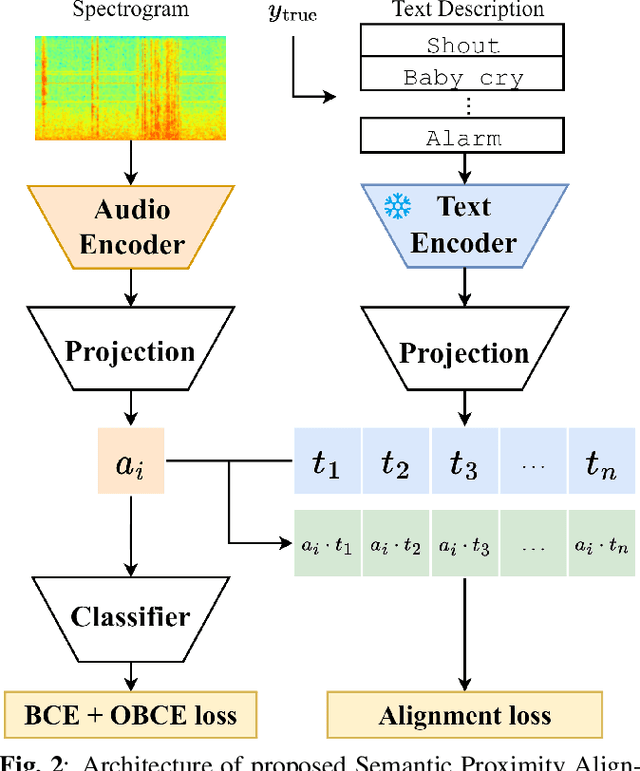
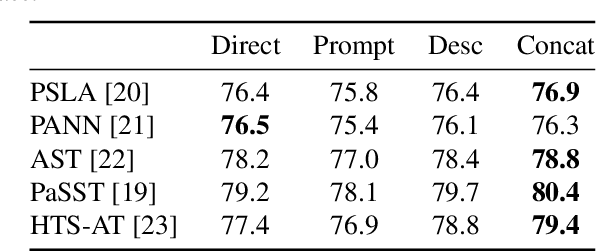
Most audio tagging models are trained with one-hot labels as supervised information. However, one-hot labels treat all sound events equally, ignoring the semantic hierarchy and proximity relationships between sound events. In contrast, the event descriptions contains richer information, describing the distance between different sound events with semantic proximity. In this paper, we explore the impact of training audio tagging models with auxiliary text descriptions of sound events. By aligning the audio features with the text features of corresponding labels, we inject the hierarchy and proximity information of sound events into audio encoders, improving the performance while making the prediction more consistent with human perception. We refer to this approach as Semantic Proximity Alignment (SPA). We use Ontology-aware mean Average Precision (OmAP) as the main evaluation metric for the models. OmAP reweights the false positives based on Audioset ontology distance and is more consistent with human perception compared to mAP. Experimental results show that the audio tagging models trained with SPA achieve higher OmAP compared to models trained with one-hot labels solely (+1.8 OmAP). Human evaluations also demonstrate that the predictions of SPA models are more consistent with human perception.