 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-visual Event Localization on Portrait Mode Short Videos
Apr 09, 2025Audio-visual event localization (AVEL) plays a critical role in multimodal scene understanding. While existing datasets for AVEL predominantly comprise landscape-oriented long videos with clean and simple audio context, short videos have become the primary format of online video content due to the the proliferation of smartphones. Short videos are characterized by portrait-oriented framing and layered audio compositions (e.g., overlapping sound effects, voiceovers, and music), which brings unique challenges unaddressed by conventional methods. To this end, we introduce AVE-PM, the first AVEL dataset specifically designed for portrait mode short videos, comprising 25,335 clips that span 86 fine-grained categories with frame-level annotations. Beyond dataset creation, our empirical analysis shows that state-of-the-art AVEL methods suffer an average 18.66% performance drop during cross-mode evaluation. Further analysis reveals two key challenges of different video formats: 1) spatial bias from portrait-oriented framing introduces distinct domain priors, and 2) noisy audio composition compromise the reliability of audio modality. To address these issues, we investigate optimal preprocessing recipes and the impact of background music for AVEL on portrait mode videos. Experiments show that these methods can still benefit from tailored preprocessing and specialized model design, thus achieving improved performance. This work provides both a foundational benchmark and actionable insights for advancing AVEL research in the era of mobile-centric video content. Dataset and code will be released.
SE4Lip: Speech-Lip Encoder for Talking Head Synthesis to Solve Phoneme-Viseme Alignment Ambiguity
Apr 08, 2025Speech-driven talking head synthesis tasks commonly use general acoustic features (such as HuBERT and DeepSpeech) as guided speech features. However, we discovered that these features suffer from phoneme-viseme alignment ambiguity, which refers to the uncertainty and imprecision in matching phonemes (speech) with visemes (lip). To address this issue, we propose the Speech Encoder for Lip (SE4Lip) to encode lip features from speech directly, aligning speech and lip features in the joint embedding space by a cross-modal alignment framework. The STFT spectrogram with the GRU-based model is designed in SE4Lip to preserve the fine-grained speech features. Experimental results show that SE4Lip achieves state-of-the-art performance in both NeRF and 3DGS rendering models. Its lip sync accuracy improves by 13.7% and 14.2% compared to the best baseline and produces results close to the ground truth videos.
Physical Perception Network and an All-weather Multi-modality Benchmark for Adverse Weather Image Fusion
Feb 03, 2024



Multi-modality image fusion (MMIF) integrates the complementary information from different modal images to provide comprehensive and objective interpretation of a scenes. However, existing MMIF methods lack the ability to resist different weather interferences in real-life scenarios, preventing them from being useful in practical applications such as autonomous driving. To bridge this research gap, we proposed an all-weather MMIF model. Regarding deep learning architectures, their network designs are often viewed as a black box, which limits their multitasking capabilities. For deweathering module, we propose a physically-aware clear feature prediction module based on an atmospheric scattering model that can deduce variations in light transmittance from both scene illumination and depth. For fusion module, We utilize a learnable low-rank representation model to decompose images into low-rank and sparse components. This highly interpretable feature separation allows us to better observe and understand images. Furthermore, we have established a benchmark for MMIF research under extreme weather conditions. It encompasses multiple scenes under three types of weather: rain, haze, and snow, with each weather condition further subdivided into various impact levels. Extensive fusion experiments under adverse weather demonstrate that the proposed algorithm has excellent detail recovery and multi-modality feature extraction capabilities.
Bridging the Gap between Multi-focus and Multi-modal: A Focused Integration Framework for Multi-modal Image Fusion
Nov 03, 2023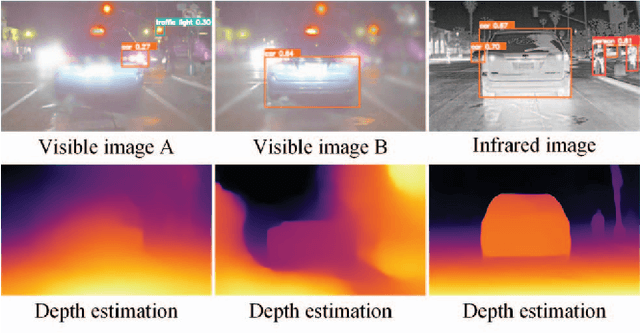
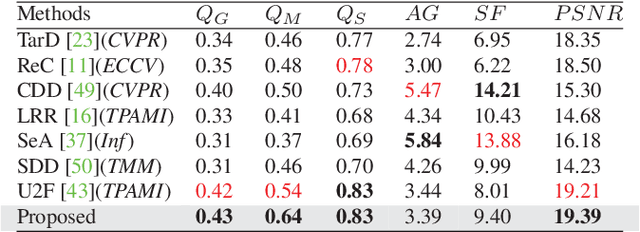
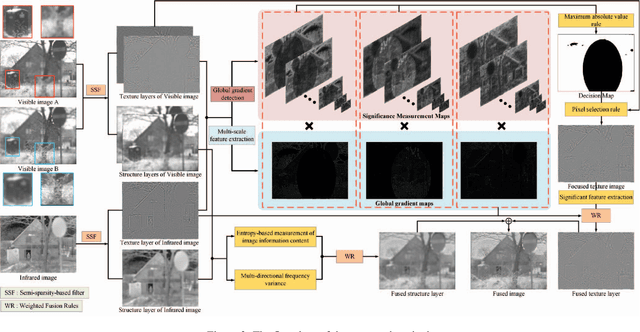
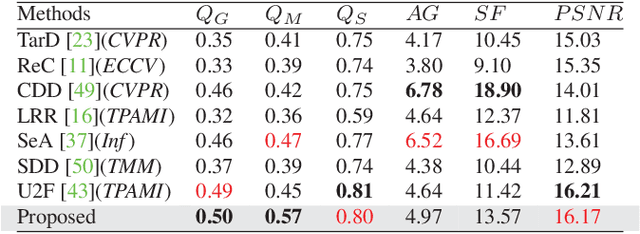
Multi-modal image fusion (MMIF) integrates valuable information from different modality images into a fused one. However, the fusion of multiple visible images with different focal regions and infrared images is a unprecedented challenge in real MMIF applications. This is because of the limited depth of the focus of visible optical lenses, which impedes the simultaneous capture of the focal information within the same scene. To address this issue, in this paper, we propose a MMIF framework for joint focused integration and modalities information extraction. Specifically, a semi-sparsity-based smoothing filter is introduced to decompose the images into structure and texture components. Subsequently, a novel multi-scale operator is proposed to fuse the texture components, capable of detecting significant information by considering the pixel focus attributes and relevant data from various modal images. Additionally, to achieve an effective capture of scene luminance and reasonable contrast maintenance, we consider the distribution of energy information in the structural components in terms of multi-directional frequency variance and information entropy. Extensive experiments on existing MMIF datasets, as well as the object detection and depth estimation tasks, consistently demonstrate that the proposed algorithm can surpass the state-of-the-art methods in visual perception and quantitative evaluation. The code is available at https://github.com/ixilai/MFIF-MMIF.
Semantic Proximity Alignment: Towards Human Perception-consistent Audio Tagging by Aligning with Label Text Description
Sep 28, 2023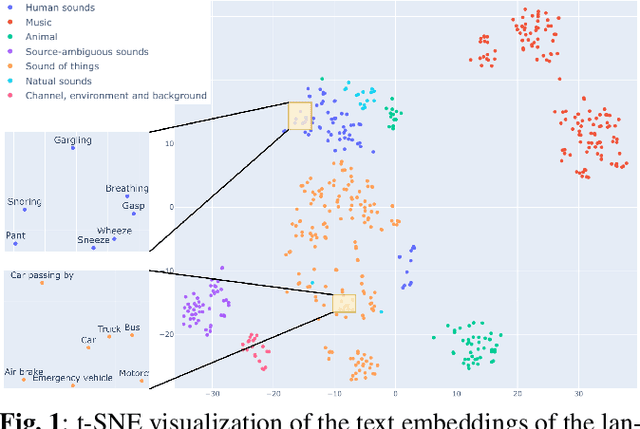
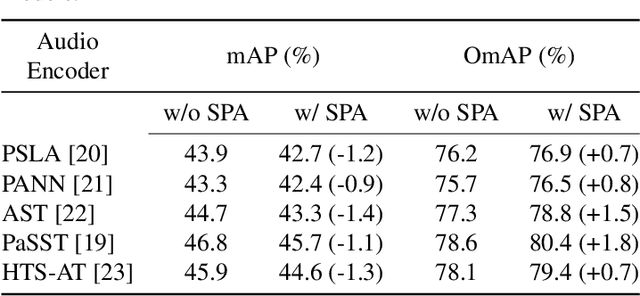
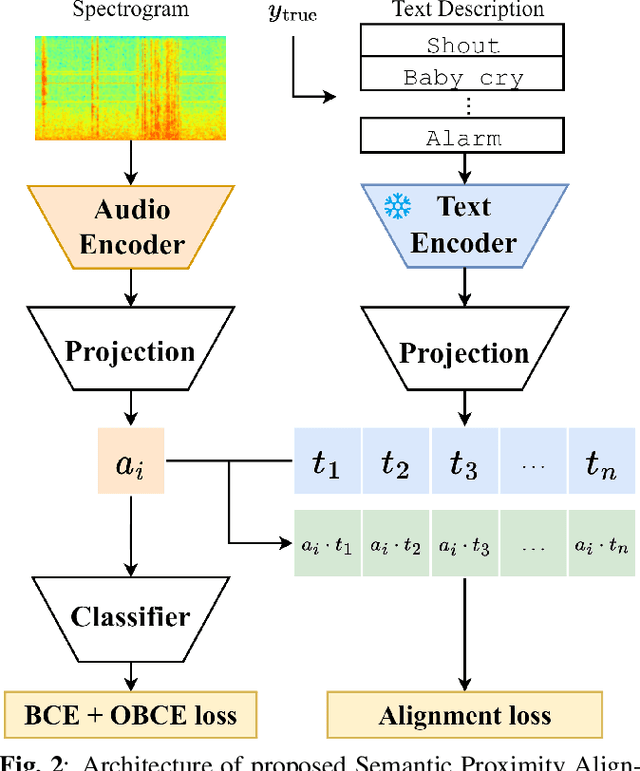
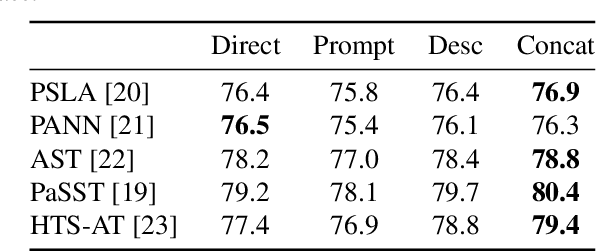
Most audio tagging models are trained with one-hot labels as supervised information. However, one-hot labels treat all sound events equally, ignoring the semantic hierarchy and proximity relationships between sound events. In contrast, the event descriptions contains richer information, describing the distance between different sound events with semantic proximity. In this paper, we explore the impact of training audio tagging models with auxiliary text descriptions of sound events. By aligning the audio features with the text features of corresponding labels, we inject the hierarchy and proximity information of sound events into audio encoders, improving the performance while making the prediction more consistent with human perception. We refer to this approach as Semantic Proximity Alignment (SPA). We use Ontology-aware mean Average Precision (OmAP) as the main evaluation metric for the models. OmAP reweights the false positives based on Audioset ontology distance and is more consistent with human perception compared to mAP. Experimental results show that the audio tagging models trained with SPA achieve higher OmAP compared to models trained with one-hot labels solely (+1.8 OmAP). Human evaluations also demonstrate that the predictions of SPA models are more consistent with human perception.