 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Guided Channel Perturbation and Pretrained Knowledge Integration for Unified Multi-Modality Image Fusion
Nov 16, 2025Multi-modality image fusion enhances scene perception by combining complementary information. Unified models aim to share parameters across modalities for multi-modality image fusion, but large modality differences often cause gradient conflicts, limiting performance. Some methods introduce modality-specific encoders to enhance feature perception and improve fusion quality. However, this strategy reduces generalisation across different fusion tasks. To overcome this limitation, we propose a unified multi-modality image fusion framework based on channel perturbation and pre-trained knowledge integration (UP-Fusion). To suppress redundant modal information and emphasize key features, we propose the Semantic-Aware Channel Pruning Module (SCPM), which leverages the semantic perception capability of a pre-trained model to filter and enhance multi-modality feature channels. Furthermore, we proposed the Geometric Affine Modulation Module (GAM), which uses original modal features to apply affine transformations on initial fusion features to maintain the feature encoder modal discriminability. Finally, we apply a Text-Guided Channel Perturbation Module (TCPM) during decoding to reshape the channel distribution, reducing the dependence on modality-specific channels. Extensive experiments demonstrate that the proposed algorithm outperforms existing methods on both multi-modality image fusion and downstream tasks.
AWM-Fuse: Multi-Modality Image Fusion for Adverse Weather via Global and Local Text Perception
Aug 23, 2025



Multi-modality image fusion (MMIF) in adverse weather aims to address the loss of visual information caused by weather-related degradations, providing clearer scene representations. Although less studies have attempted to incorporate textual information to improve semantic perception, they often lack effective categorization and thorough analysis of textual content. In response, we propose AWM-Fuse, a novel fusion method for adverse weather conditions, designed to handle multiple degradations through global and local text perception within a unified, shared weight architecture. In particular, a global feature perception module leverages BLIP-produced captions to extract overall scene features and identify primary degradation types, thus promoting generalization across various adverse weather conditions. Complementing this, the local module employs detailed scene descriptions produced by ChatGPT to concentrate on specific degradation effects through concrete textual cues, thereby capturing finer details. Furthermore, textual descriptions are used to constrain the generation of fusion images, effectively steering the network learning process toward better alignment with real semantic labels, thereby promoting the learning of more meaningful visual features. Extensive experiments demonstrate that AWM-Fuse outperforms current state-of-the-art methods in complex weather conditions and downstream tasks. Our code is available at https://github.com/Feecuin/AWM-Fuse.
GDSR: Global-Detail Integration through Dual-Branch Network with Wavelet Losses for Remote Sensing Image Super-Resolution
Jan 07, 2025In recent years, deep neural networks, including Convolutional Neural Networks, Transformers, and State Space Models, have achieved significant progress in Remote Sensing Image (RSI) Super-Resolution (SR). However, existing SR methods typically overlook the complementary relationship between global and local dependencies. These methods either focus on capturing local information or prioritize global information, which results in models that are unable to effectively capture both global and local features simultaneously. Moreover, their computational cost becomes prohibitive when applied to large-scale RSIs. To address these challenges, we introduce the novel application of Receptance Weighted Key Value (RWKV) to RSI-SR, which captures long-range dependencies with linear complexity. To simultaneously model global and local features, we propose the Global-Detail dual-branch structure, GDSR, which performs SR reconstruction by paralleling RWKV and convolutional operations to handle large-scale RSIs. Furthermore, we introduce the Global-Detail Reconstruction Module (GDRM) as an intermediary between the two branches to bridge their complementary roles. In addition, we propose Wavelet Loss, a loss function that effectively captures high-frequency detail information in images, thereby enhancing the visual quality of SR, particularly in terms of detail reconstruction. Extensive experiments on several benchmarks, including AID, AID_CDM, RSSRD-QH, and RSSRD-QH_CDM, demonstrate that GSDR outperforms the state-of-the-art Transformer-based method HAT by an average of 0.05 dB in PSNR, while using only 63% of its parameters and 51% of its FLOPs, achieving an inference speed 2.9 times faster. Furthermore, the Wavelet Loss shows excellent generalization across various architectures, providing a novel perspective for RSI-SR enhancement.
SpeechVerse: A Large-scale Generalizable Audio Language Model
May 14, 2024



Large language models (LLMs) have shown incredible proficiency in performing tasks that require semantic understanding of natural language instructions. Recently, many works have further expanded this capability to perceive multimodal audio and text inputs, but their capabilities are often limited to specific fine-tuned tasks such as automatic speech recognition and translation. We therefore develop SpeechVerse, a robust multi-task training and curriculum learning framework that combines pre-trained speech and text foundation models via a small set of learnable parameters, while keeping the pre-trained models frozen during training. The models are instruction finetuned using continuous latent representations extracted from the speech foundation model to achieve optimal zero-shot performance on a diverse range of speech processing tasks using natural language instructions. We perform extensive benchmarking that includes comparing our model performance against traditional baselines across several datasets and tasks. Furthermore, we evaluate the model's capability for generalized instruction following by testing on out-of-domain datasets, novel prompts, and unseen tasks. Our empirical experiments reveal that our multi-task SpeechVerse model is even superior to conventional task-specific baselines on 9 out of the 11 tasks.
MMA-UNet: A Multi-Modal Asymmetric UNet Architecture for Infrared and Visible Image Fusion
Apr 27, 2024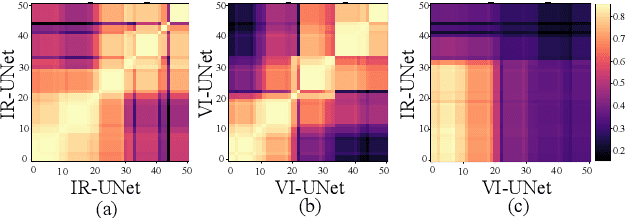
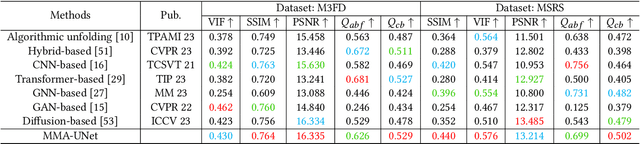
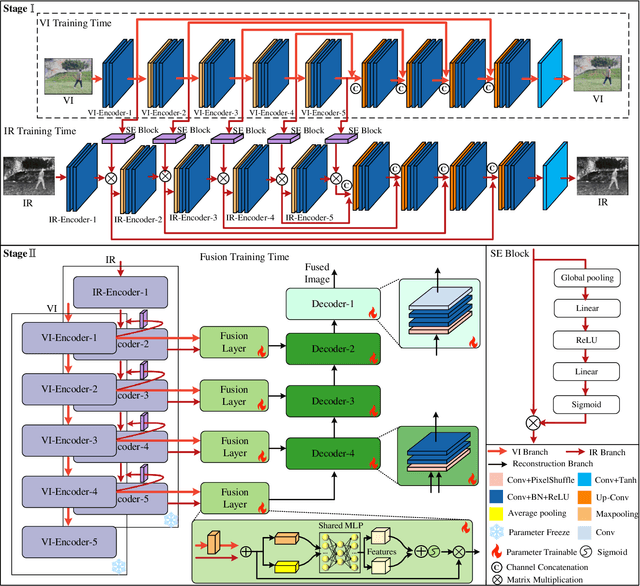
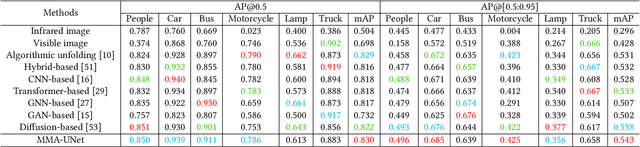
Multi-modal image fusion (MMIF) maps useful information from various modalities into the same representation space, thereby producing an informative fused image. However, the existing fusion algorithms tend to symmetrically fuse the multi-modal images, causing the loss of shallow information or bias towards a single modality in certain regions of the fusion results. In this study, we analyzed the spatial distribution differences of information in different modalities and proved that encoding features within the same network is not conducive to achieving simultaneous deep feature space alignment for multi-modal images. To overcome this issue, a Multi-Modal Asymmetric UNet (MMA-UNet) was proposed. We separately trained specialized feature encoders for different modal and implemented a cross-scale fusion strategy to maintain the features from different modalities within the same representation space, ensuring a balanced information fusion process. Furthermore, extensive fusion and downstream task experiments were conducted to demonstrate the efficiency of MMA-UNet in fusing infrared and visible image information, producing visually natural and semantically rich fusion results. Its performance surpasses that of the state-of-the-art comparison fusion methods.
Decomposition-based and Interference Perception for Infrared and Visible Image Fusion in Complex Scenes
Feb 03, 2024Infrared and visible image fusion has emerged as a prominent research in computer vision. However, little attention has been paid on complex scenes fusion, causing existing techniques to produce sub-optimal results when suffers from real interferences. To fill this gap, we propose a decomposition-based and interference perception image fusion method. Specifically, we classify the pixels of visible image from the degree of scattering of light transmission, based on which we then separate the detail and energy information of the image. This refined decomposition facilitates the proposed model in identifying more interfering pixels that are in complex scenes. To strike a balance between denoising and detail preservation, we propose an adaptive denoising scheme for fusing detail components. Meanwhile, we propose a new weighted fusion rule by considering the distribution of image energy information from the perspective of multiple directions. Extensive experiments in complex scenes fusions cover adverse weathers, noise, blur, overexposure, fire, as well as downstream tasks including semantic segmentation, object detection, salient object detection and depth estimation, consistently indicate the effectiveness and superiority of the proposed method compared with the recent representative methods.
Physical Perception Network and an All-weather Multi-modality Benchmark for Adverse Weather Image Fusion
Feb 03, 2024



Multi-modality image fusion (MMIF) integrates the complementary information from different modal images to provide comprehensive and objective interpretation of a scenes. However, existing MMIF methods lack the ability to resist different weather interferences in real-life scenarios, preventing them from being useful in practical applications such as autonomous driving. To bridge this research gap, we proposed an all-weather MMIF model. Regarding deep learning architectures, their network designs are often viewed as a black box, which limits their multitasking capabilities. For deweathering module, we propose a physically-aware clear feature prediction module based on an atmospheric scattering model that can deduce variations in light transmittance from both scene illumination and depth. For fusion module, We utilize a learnable low-rank representation model to decompose images into low-rank and sparse components. This highly interpretable feature separation allows us to better observe and understand images. Furthermore, we have established a benchmark for MMIF research under extreme weather conditions. It encompasses multiple scenes under three types of weather: rain, haze, and snow, with each weather condition further subdivided into various impact levels. Extensive fusion experiments under adverse weather demonstrate that the proposed algorithm has excellent detail recovery and multi-modality feature extraction capabilities.
SAMF: Small-Area-Aware Multi-focus Image Fusion for Object Detection
Jan 31, 2024



Existing multi-focus image fusion (MFIF) methods often fail to preserve the uncertain transition region and detect small focus areas within large defocused regions accurately. To address this issue, this study proposes a new small-area-aware MFIF algorithm for enhancing object detection capability. First, we enhance the pixel attributes within the small focus and boundary regions, which are subsequently combined with visual saliency detection to obtain the pre-fusion results used to discriminate the distribution of focused pixels. To accurately ensure pixel focus, we consider the source image as a combination of focused, defocused, and uncertain regions and propose a three-region segmentation strategy. Finally, we design an effective pixel selection rule to generate segmentation decision maps and obtain the final fusion results. Experiments demonstrated that the proposed method can accurately detect small and smooth focus areas while improving object detection performance, outperforming existing methods in both subjective and objective evaluations. The source code is available at https://github.com/ixilai/SAMF.
Bridging the Gap between Multi-focus and Multi-modal: A Focused Integration Framework for Multi-modal Image Fusion
Nov 03, 2023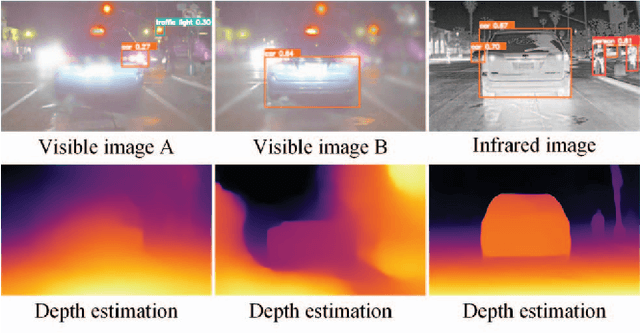
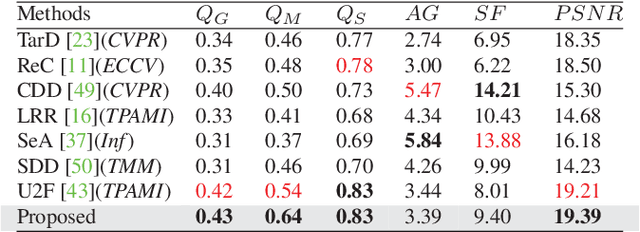
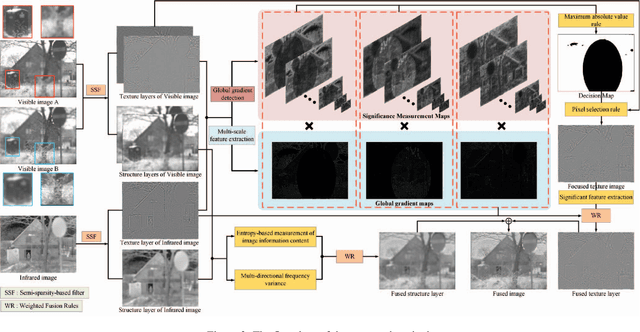
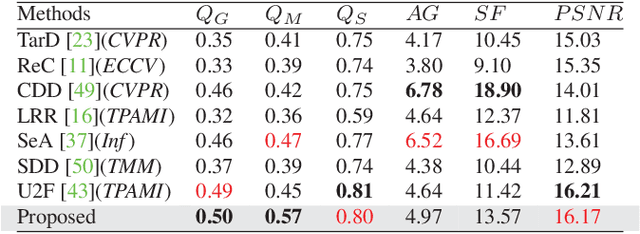
Multi-modal image fusion (MMIF) integrates valuable information from different modality images into a fused one. However, the fusion of multiple visible images with different focal regions and infrared images is a unprecedented challenge in real MMIF applications. This is because of the limited depth of the focus of visible optical lenses, which impedes the simultaneous capture of the focal information within the same scene. To address this issue, in this paper, we propose a MMIF framework for joint focused integration and modalities information extraction. Specifically, a semi-sparsity-based smoothing filter is introduced to decompose the images into structure and texture components. Subsequently, a novel multi-scale operator is proposed to fuse the texture components, capable of detecting significant information by considering the pixel focus attributes and relevant data from various modal images. Additionally, to achieve an effective capture of scene luminance and reasonable contrast maintenance, we consider the distribution of energy information in the structural components in terms of multi-directional frequency variance and information entropy. Extensive experiments on existing MMIF datasets, as well as the object detection and depth estimation tasks, consistently demonstrate that the proposed algorithm can surpass the state-of-the-art methods in visual perception and quantitative evaluation. The code is available at https://github.com/ixilai/MFIF-MMIF.
DCTX-Conformer: Dynamic context carry-over for low latency unified streaming and non-streaming Conformer
Jun 13, 2023Conformer-based end-to-end models have become ubiquitous these days and are commonly used in both streaming and non-streaming automatic speech recognition (ASR). Techniques like dual-mode and dynamic chunk training helped unify streaming and non-streaming systems. However, there remains a performance gap between streaming with a full and limited past context. To address this issue, we propose the integration of a novel dynamic contextual carry-over mechanism in a state-of-the-art (SOTA) unified ASR system. Our proposed dynamic context Conformer (DCTX-Conformer) utilizes a non-overlapping contextual carry-over mechanism that takes into account both the left context of a chunk and one or more preceding context embeddings. We outperform the SOTA by a relative 25.0% word error rate, with a negligible latency impact due to the additional context embeddings.