 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Audio Text Encoders are Effective Multi-Modal Rescorers
May 24, 2023



Masked Language Models (MLMs) have proven to be effective for second-pass rescoring in Automatic Speech Recognition (ASR) systems. In this work, we propose Masked Audio Text Encoder (MATE), a multi-modal masked language model rescorer which incorporates acoustic representations into the input space of MLM. We adopt contrastive learning for effectively aligning the modalities by learning shared representations. We show that using a multi-modal rescorer is beneficial for domain generalization of the ASR system when target domain data is unavailable. MATE reduces word error rate (WER) by 4%-16% on in-domain, and 3%-7% on out-of-domain datasets, over the text-only baseline. Additionally, with very limited amount of training data (0.8 hours), MATE achieves a WER reduction of 8%-23% over the first-pass baseline.
Zero-Shot End-to-End Spoken Language Understanding via Cross-Modal Selective Self-Training
May 22, 2023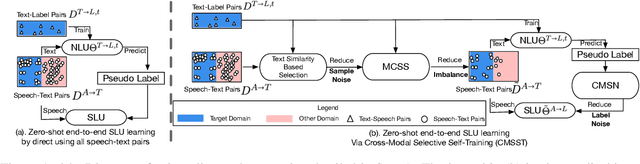
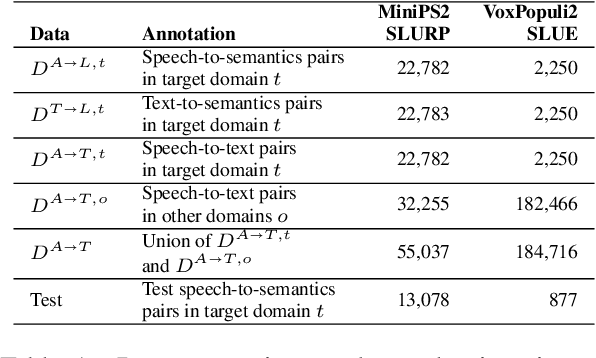
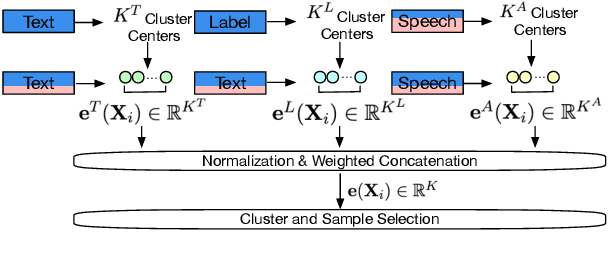
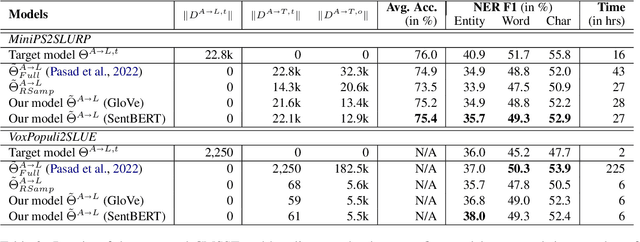
End-to-end (E2E) spoken language understanding (SLU) is constrained by the cost of collecting speech-semantics pairs, especially when label domains change. Hence, we explore \textit{zero-shot} E2E SLU, which learns E2E SLU without speech-semantics pairs, instead using only speech-text and text-semantics pairs. Previous work achieved zero-shot by pseudolabeling all speech-text transcripts with a natural language understanding (NLU) model learned on text-semantics corpora. However, this method requires the domains of speech-text and text-semantics to match, which often mismatch due to separate collections. Furthermore, using the entire speech-text corpus from any domains leads to \textit{imbalance} and \textit{noise} issues. To address these, we propose \textit{cross-modal selective self-training} (CMSST). CMSST tackles imbalance by clustering in a joint space of the three modalities (speech, text, and semantics) and handles label noise with a selection network. We also introduce two benchmarks for zero-shot E2E SLU, covering matched and found speech (mismatched) settings. Experiments show that CMSST improves performance in both two settings, with significantly reduced sample sizes and training time.
Mask The Bias: Improving Domain-Adaptive Generalization of CTC-based ASR with Internal Language Model Estimation
May 05, 2023
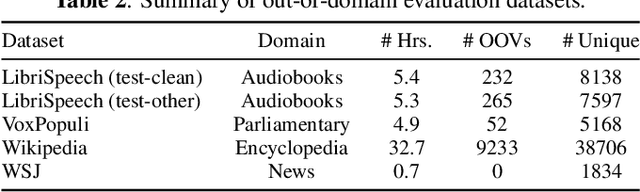
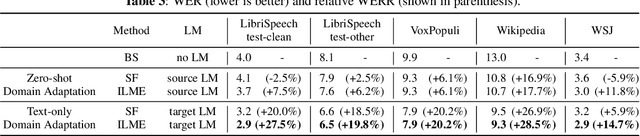
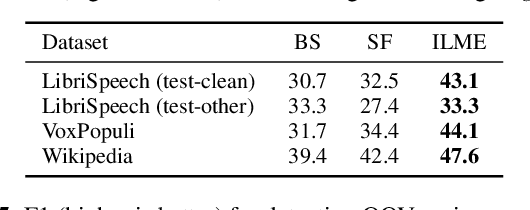
End-to-end ASR models trained on large amount of data tend to be implicitly biased towards language semantics of the training data. Internal language model estimation (ILME) has been proposed to mitigate this bias for autoregressive models such as attention-based encoder-decoder and RNN-T. Typically, ILME is performed by modularizing the acoustic and language components of the model architecture, and eliminating the acoustic input to perform log-linear interpolation with the text-only posterior. However, for CTC-based ASR, it is not as straightforward to decouple the model into such acoustic and language components, as CTC log-posteriors are computed in a non-autoregressive manner. In this work, we propose a novel ILME technique for CTC-based ASR models. Our method iteratively masks the audio timesteps to estimate a pseudo log-likelihood of the internal LM by accumulating log-posteriors for only the masked timesteps. Extensive evaluation across multiple out-of-domain datasets reveals that the proposed approach improves WER by up to 9.8% and OOV F1-score by up to 24.6% relative to Shallow Fusion, when only text data from target domain is available. In the case of zero-shot domain adaptation, with no access to any target domain data, we demonstrate that removing the source domain bias with ILME can still outperform Shallow Fusion to improve WER by up to 9.3% relative.
KG-ECO: Knowledge Graph Enhanced Entity Correction for Query Rewriting
Feb 22, 2023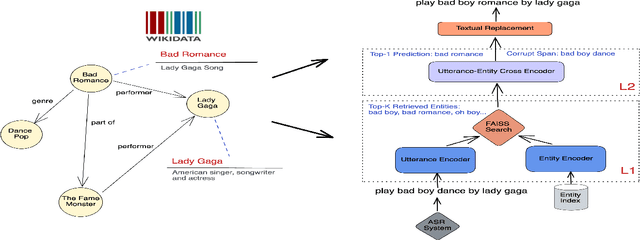

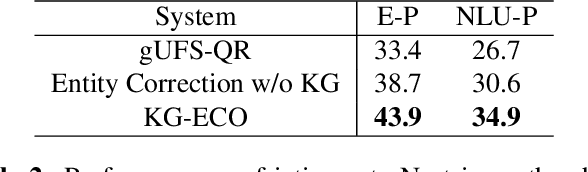
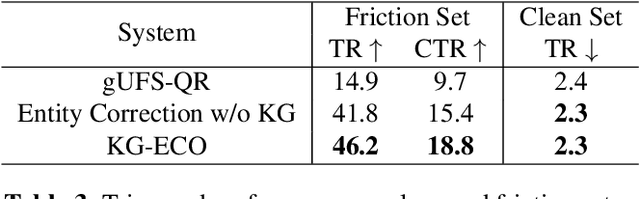
Query Rewriting (QR) plays a critical role in large-scale dialogue systems for reducing frictions. When there is an entity error, it imposes extra challenges for a dialogue system to produce satisfactory responses. In this work, we propose KG-ECO: Knowledge Graph enhanced Entity COrrection for query rewriting, an entity correction system with corrupt entity span detection and entity retrieval/re-ranking functionalities. To boost the model performance, we incorporate Knowledge Graph (KG) to provide entity structural information (neighboring entities encoded by graph neural networks) and textual information (KG entity descriptions encoded by RoBERTa). Experimental results show that our approach yields a clear performance gain over two baselines: utterance level QR and entity correction without utilizing KG information. The proposed system is particularly effective for few-shot learning cases where target entities are rarely seen in training or there is a KG relation between the target entity and other contextual entities in the query.
Balancing Multi-Domain Corpora Learning for Open-Domain Response Generation
May 05, 2022
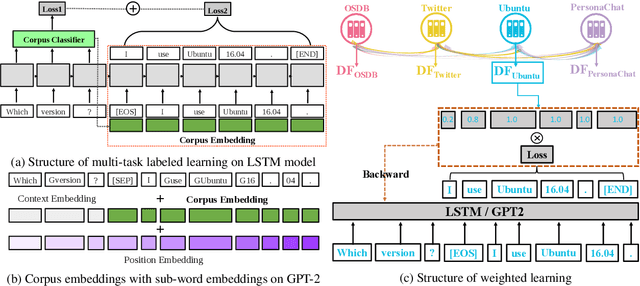
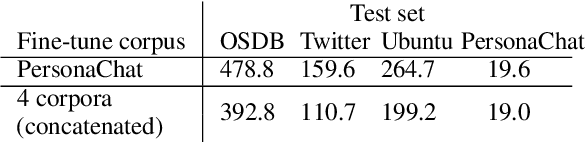
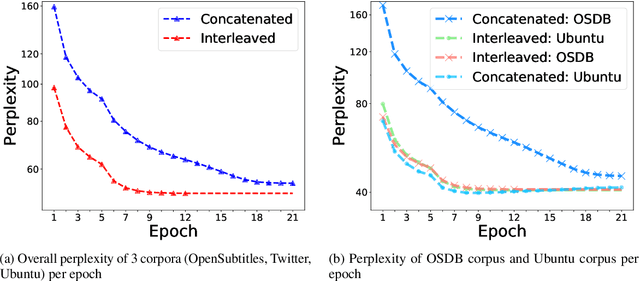
Open-domain conversational systems are assumed to generate equally good responses on multiple domains. Previous work achieved good performance on the single corpus, but training and evaluating on multiple corpora from different domains are less studied. This paper explores methods of generating relevant responses for each of multiple multi-domain corpora. We first examine interleaved learning which intermingles multiple corpora as the baseline. We then investigate two multi-domain learning methods, labeled learning and multi-task labeled learning, which encode each corpus through a unique corpus embedding. Furthermore, we propose Domain-specific Frequency (DF), a novel word-level importance weight that measures the relative importance of a word for a specific corpus compared to other corpora. Based on DF, we propose weighted learning, a method that integrates DF to the loss function. We also adopt DF as a new evaluation metric. Extensive experiments show that our methods gain significant improvements on both automatic and human evaluation. We share our code and data for reproducibility