 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$R$-equivalence on Cubic Surfaces I: Existing Cases with Non-Trivial Universal Equivalence
Mar 19, 2026Let $V$ be a smooth cubic surface over a $p$-adic field $k$ with good reduction. Swinnerton-Dyer (1981) proved that $R$-equivalence is trivial on $V(k)$ except perhaps if $V$ is one of three special types--those whose $R$-equivalence he could not bound by proving the universal (admissible) equivalence is trivial. We consider all surfaces $V$ currently known to have non-trivial universal equivalence. Beyond being intractable to Swinnerton-Dyer's approach, we observe that if these surfaces also had non-trivial $R$-equivalence, they would contradict Colliot-Thélène and Sansuc's conjecture regarding the $k$-rationality of universal torsors for geometrically rational surfaces. By devising new methods to study $R$-equivalence, we prove that for 2-adic surfaces with all-Eckardt reductions (the third special type, which contains every existing case of non-trivial universal equivalence), $R$-equivalence is trivial or of exponent 2. For the explicit cases, we confirm triviality: the diagonal cubic $X^3+Y^3+Z^3+ζ_3 T^3=0$ over $\mathbb{Q}_2(ζ_3)$--answering a long-standing question of Manin's (Cubic Forms, 1972)--and the cubic with universal equivalence of exponent 2 (Kanevsky, 1982). This is the first in a series of works derived from a year of interactions with generative AI models such as AlphaEvolve and Gemini 3 Deep Think, with the latter proving many of our lemmas. We disclose the timeline and nature of their use towards this paper, and describe our broader AI-assisted research program in a companion report (in preparation).
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Long-Form Speech Generation with Spoken Language Models
Dec 24, 2024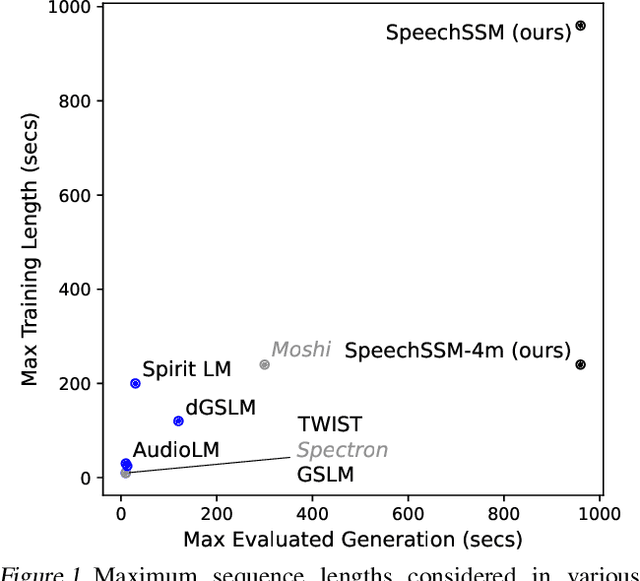
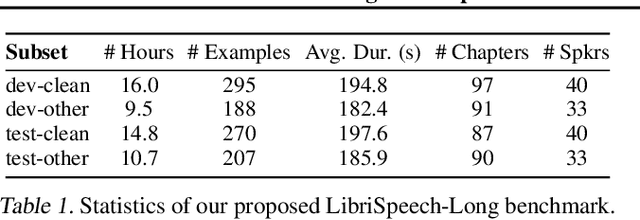

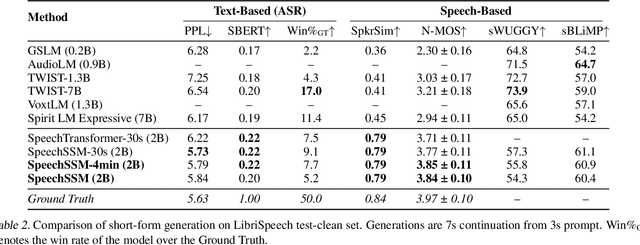
We consider the generative modeling of speech over multiple minutes, a requirement for long-form multimedia generation and audio-native voice assistants. However, current spoken language models struggle to generate plausible speech past tens of seconds, from high temporal resolution of speech tokens causing loss of coherence, to architectural issues with long-sequence training or extrapolation, to memory costs at inference time. With these considerations we propose SpeechSSM, the first speech language model to learn from and sample long-form spoken audio (e.g., 16 minutes of read or extemporaneous speech) in a single decoding session without text intermediates, based on recent advances in linear-time sequence modeling. Furthermore, to address growing challenges in spoken language evaluation, especially in this new long-form setting, we propose: new embedding-based and LLM-judged metrics; quality measurements over length and time; and a new benchmark for long-form speech processing and generation, LibriSpeech-Long. Speech samples and the dataset are released at https://google.github.io/tacotron/publications/speechssm/
Zero-Shot Mono-to-Binaural Speech Synthesis
Dec 11, 2024


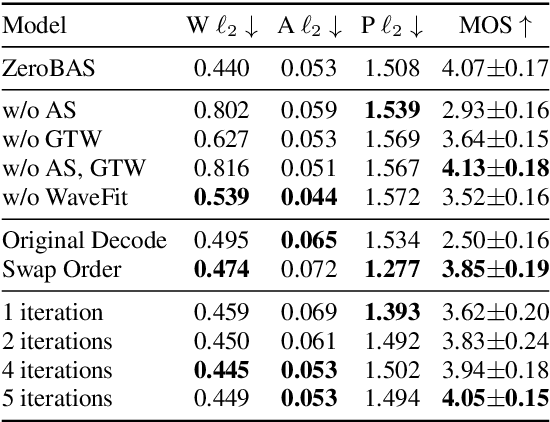
We present ZeroBAS, a neural method to synthesize binaural audio from monaural audio recordings and positional information without training on any binaural data. To our knowledge, this is the first published zero-shot neural approach to mono-to-binaural audio synthesis. Specifically, we show that a parameter-free geometric time warping and amplitude scaling based on source location suffices to get an initial binaural synthesis that can be refined by iteratively applying a pretrained denoising vocoder. Furthermore, we find this leads to generalization across room conditions, which we measure by introducing a new dataset, TUT Mono-to-Binaural, to evaluate state-of-the-art monaural-to-binaural synthesis methods on unseen conditions. Our zero-shot method is perceptually on-par with the performance of supervised methods on the standard mono-to-binaural dataset, and even surpasses them on our out-of-distribution TUT Mono-to-Binaural dataset. Our results highlight the potential of pretrained generative audio models and zero-shot learning to unlock robust binaural audio synthesis.
Very Attentive Tacotron: Robust and Unbounded Length Generalization in Autoregressive Transformer-Based Text-to-Speech
Oct 29, 2024Autoregressive (AR) Transformer-based sequence models are known to have difficulty generalizing to sequences longer than those seen during training. When applied to text-to-speech (TTS), these models tend to drop or repeat words or produce erratic output, especially for longer utterances. In this paper, we introduce enhancements aimed at AR Transformer-based encoder-decoder TTS systems that address these robustness and length generalization issues. Our approach uses an alignment mechanism to provide cross-attention operations with relative location information. The associated alignment position is learned as a latent property of the model via backprop and requires no external alignment information during training. While the approach is tailored to the monotonic nature of TTS input-output alignment, it is still able to benefit from the flexible modeling power of interleaved multi-head self- and cross-attention operations. A system incorporating these improvements, which we call Very Attentive Tacotron, matches the naturalness and expressiveness of a baseline T5-based TTS system, while eliminating problems with repeated or dropped words and enabling generalization to any practical utterance length.
LMs with a Voice: Spoken Language Modeling beyond Speech Tokens
May 24, 2023


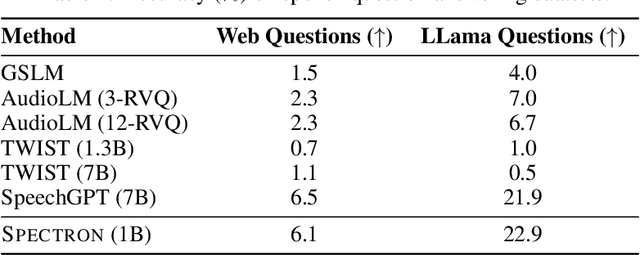
We present SPECTRON, a novel approach to adapting pre-trained language models (LMs) to perform speech continuation. By leveraging pre-trained speech encoders, our model generates both text and speech outputs with the entire system being trained end-to-end operating directly on spectrograms. Training the entire model in the spectrogram domain simplifies our speech continuation system versus existing cascade methods which use discrete speech representations. We further show our method surpasses existing spoken language models both in semantic content and speaker preservation while also benefiting from the knowledge transferred from pre-existing models. Audio samples can be found in our website https://michelleramanovich.github.io/spectron/spectron
Zero-Shot End-to-End Spoken Language Understanding via Cross-Modal Selective Self-Training
May 22, 2023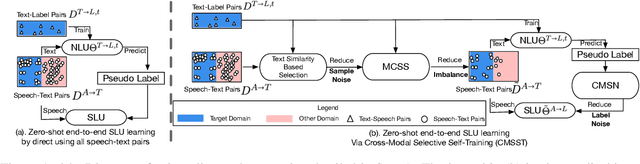
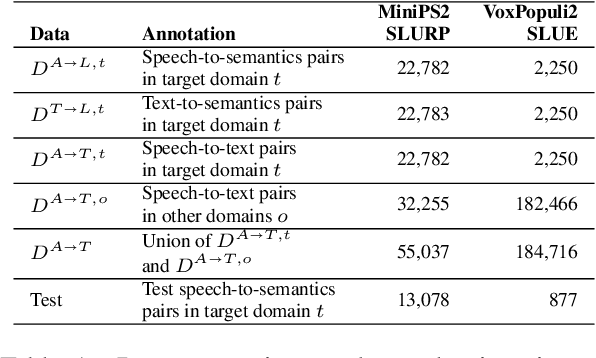
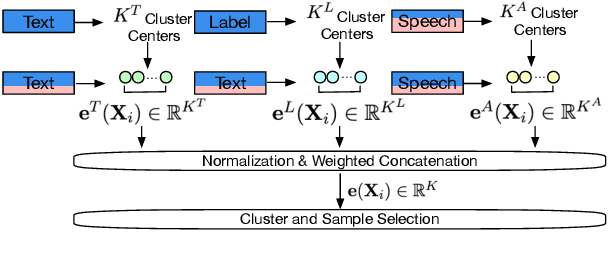
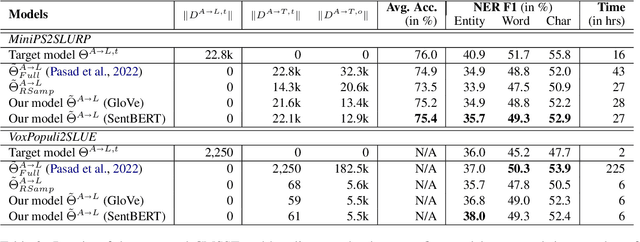
End-to-end (E2E) spoken language understanding (SLU) is constrained by the cost of collecting speech-semantics pairs, especially when label domains change. Hence, we explore \textit{zero-shot} E2E SLU, which learns E2E SLU without speech-semantics pairs, instead using only speech-text and text-semantics pairs. Previous work achieved zero-shot by pseudolabeling all speech-text transcripts with a natural language understanding (NLU) model learned on text-semantics corpora. However, this method requires the domains of speech-text and text-semantics to match, which often mismatch due to separate collections. Furthermore, using the entire speech-text corpus from any domains leads to \textit{imbalance} and \textit{noise} issues. To address these, we propose \textit{cross-modal selective self-training} (CMSST). CMSST tackles imbalance by clustering in a joint space of the three modalities (speech, text, and semantics) and handles label noise with a selection network. We also introduce two benchmarks for zero-shot E2E SLU, covering matched and found speech (mismatched) settings. Experiments show that CMSST improves performance in both two settings, with significantly reduced sample sizes and training time.
Meta-Learning the Difference: Preparing Large Language Models for Efficient Adaptation
Jul 07, 2022Large pretrained language models (PLMs) are often domain- or task-adapted via fine-tuning or prompting. Finetuning requires modifying all of the parameters and having enough data to avoid overfitting while prompting requires no training and few examples but limits performance. Instead, we prepare PLMs for data- and parameter-efficient adaptation by learning to learn the difference between general and adapted PLMs. This difference is expressed in terms of model weights and sublayer structure through our proposed dynamic low-rank reparameterization and learned architecture controller. Experiments on few-shot dialogue completion, low-resource abstractive summarization, and multi-domain language modeling show improvements in adaptation time and performance over direct finetuning or preparation via domain-adaptive pretraining. Ablations show our task-adaptive reparameterization (TARP) and model search (TAMS) components individually improve on other parameter-efficient transfer like adapters and structure-learning methods like learned sparsification.
Align-Refine: Non-Autoregressive Speech Recognition via Iterative Realignment
Oct 24, 2020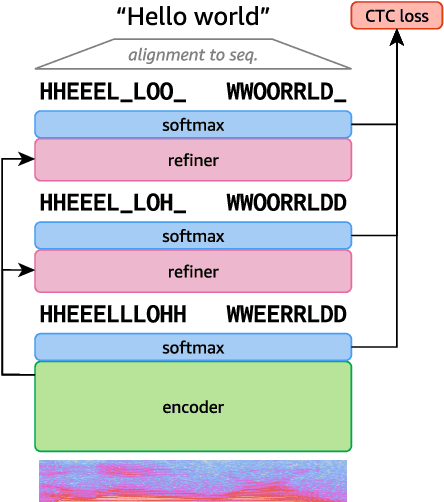
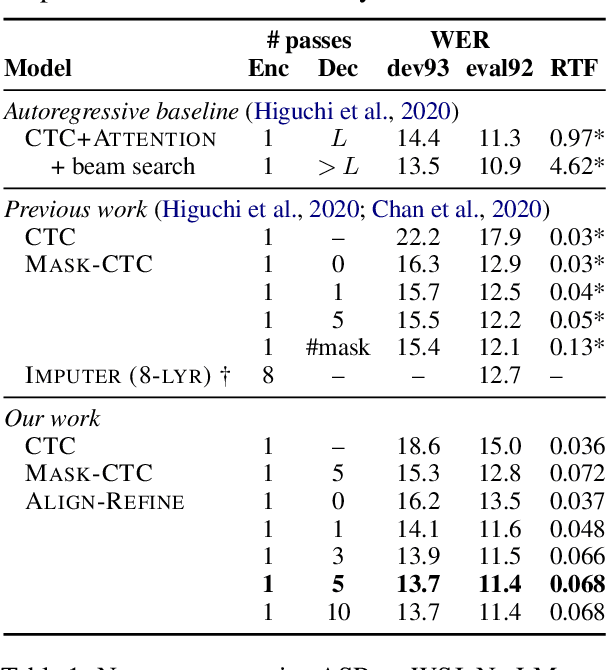
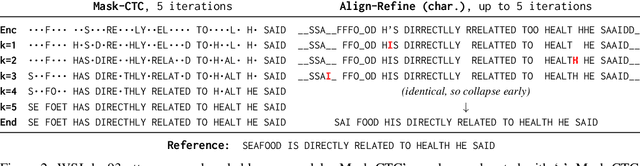
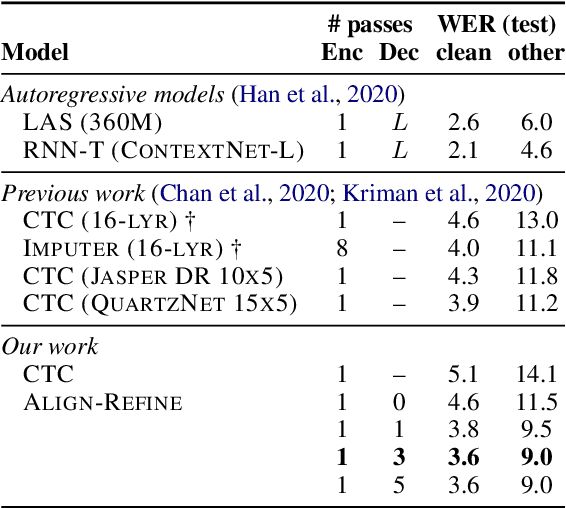
Non-autoregressive models greatly improve decoding speed over typical sequence-to-sequence models, but suffer from degraded performance. Infilling and iterative refinement models make up some of this gap by editing the outputs of a non-autoregressive model, but are constrained in the edits that they can make. We propose iterative realignment, where refinements occur over latent alignments rather than output sequence space. We demonstrate this in speech recognition with Align-Refine, an end-to-end Transformer-based model which refines connectionist temporal classification (CTC) alignments to allow length-changing insertions and deletions. Align-Refine outperforms Imputer and Mask-CTC, matching an autoregressive baseline on WSJ at 1/14th the real-time factor and attaining a LibriSpeech test-other WER of 9.0% without an LM. Our model is strong even in one iteration with a shallower decoder.
Unsupervised Bitext Mining and Translation via Self-trained Contextual Embeddings
Oct 15, 2020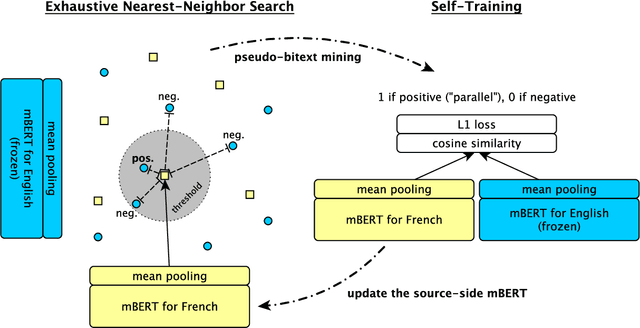
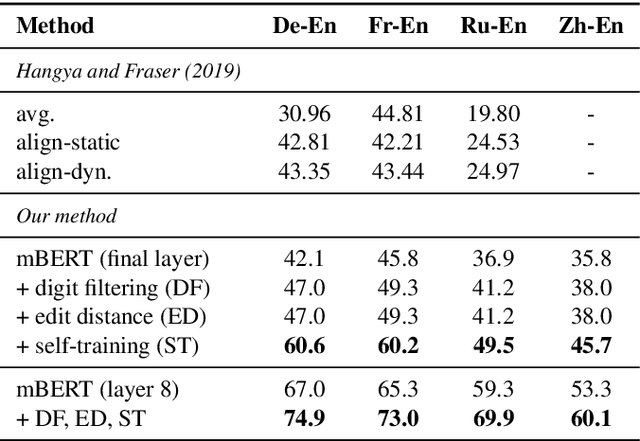

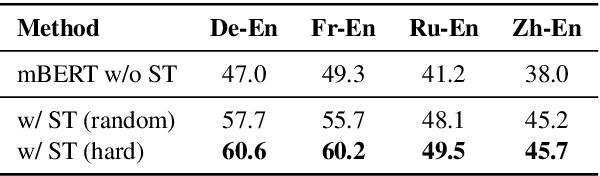
We describe an unsupervised method to create pseudo-parallel corpora for machine translation (MT) from unaligned text. We use multilingual BERT to create source and target sentence embeddings for nearest-neighbor search and adapt the model via self-training. We validate our technique by extracting parallel sentence pairs on the BUCC 2017 bitext mining task and observe up to a 24.5 point increase (absolute) in F1 scores over previous unsupervised methods. We then improve an XLM-based unsupervised neural MT system pre-trained on Wikipedia by supplementing it with pseudo-parallel text mined from the same corpus, boosting unsupervised translation performance by up to 3.5 BLEU on the WMT'14 French-English and WMT'16 German-English tasks and outperforming the previous state-of-the-art. Finally, we enrich the IWSLT'15 English-Vietnamese corpus with pseudo-parallel Wikipedia sentence pairs, yielding a 1.2 BLEU improvement on the low-resource MT task. We demonstrate that unsupervised bitext mining is an effective way of augmenting MT datasets and complements existing techniques like initializing with pre-trained contextual embeddings.