 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Adaptation Approaches for Nearest Neighbor Language Models
Nov 15, 2022Semi-parametric Nearest Neighbor Language Models ($k$NN-LMs) have produced impressive gains over purely parametric LMs, by leveraging large-scale neighborhood retrieval over external memory datastores. However, there has been little investigation into adapting such models for new domains. This work attempts to fill that gap and suggests the following approaches for adapting $k$NN-LMs -- 1) adapting the underlying LM (using Adapters), 2) expanding neighborhood retrieval over an additional adaptation datastore, and 3) adapting the weights (scores) of retrieved neighbors using a learned Rescorer module. We study each adaptation strategy separately, as well as the combined performance improvement through ablation experiments and an extensive set of evaluations run over seven adaptation domains. Our combined adaptation approach consistently outperforms purely parametric adaptation and zero-shot ($k$NN-LM) baselines that construct datastores from the adaptation data. On average, we see perplexity improvements of 17.1\% and 16\% for these respective baselines, across domains.
Meta-Learning the Difference: Preparing Large Language Models for Efficient Adaptation
Jul 07, 2022Large pretrained language models (PLMs) are often domain- or task-adapted via fine-tuning or prompting. Finetuning requires modifying all of the parameters and having enough data to avoid overfitting while prompting requires no training and few examples but limits performance. Instead, we prepare PLMs for data- and parameter-efficient adaptation by learning to learn the difference between general and adapted PLMs. This difference is expressed in terms of model weights and sublayer structure through our proposed dynamic low-rank reparameterization and learned architecture controller. Experiments on few-shot dialogue completion, low-resource abstractive summarization, and multi-domain language modeling show improvements in adaptation time and performance over direct finetuning or preparation via domain-adaptive pretraining. Ablations show our task-adaptive reparameterization (TARP) and model search (TAMS) components individually improve on other parameter-efficient transfer like adapters and structure-learning methods like learned sparsification.
Long-span language modeling for speech recognition
Nov 11, 2019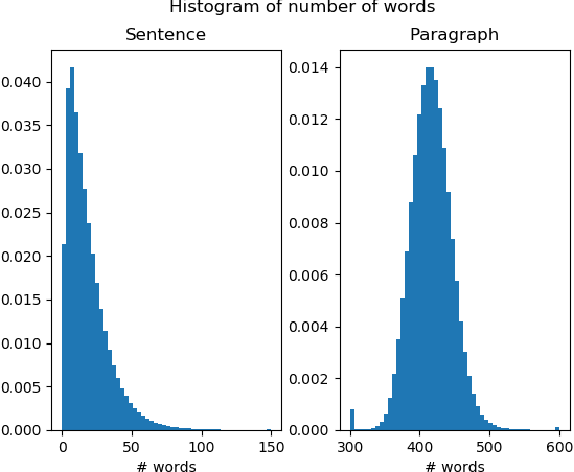
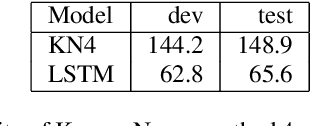
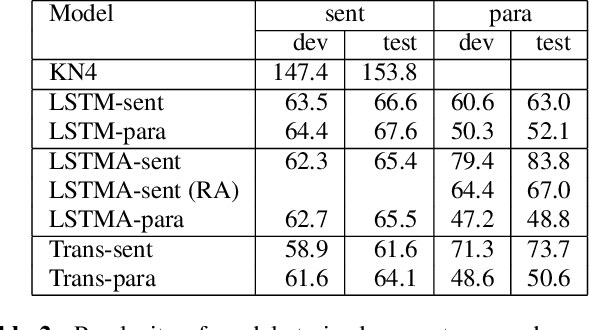
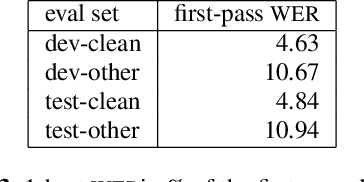
We explore neural language modeling for speech recognition where the context spans multiple sentences. Rather than encode history beyond the current sentence using a cache of words or document-level features, we focus our study on the ability of LSTM and Transformer language models to implicitly learn to carry over context across sentence boundaries. We introduce a new architecture that incorporates an attention mechanism into LSTM to combine the benefits of recurrent and attention architectures. We conduct language modeling and speech recognition experiments on the publicly available LibriSpeech corpus. We show that conventional training on a paragraph-level corpus results in significant reductions in perplexity compared to training on a sentence-level corpus. We also describe speech recognition experiments using long-span language models in second-pass re-ranking, and provide insights into the ability of such models to take advantage of context beyond the current sentence.