 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
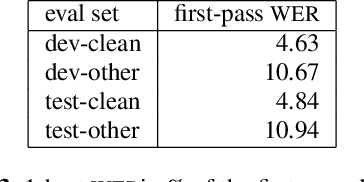
Add to EdgeLSTM-LM with Long-Term History for First-Pass Decoding in Conversational Speech Recognition
Oct 21, 2020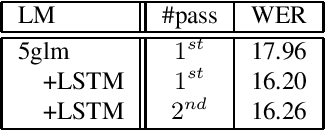
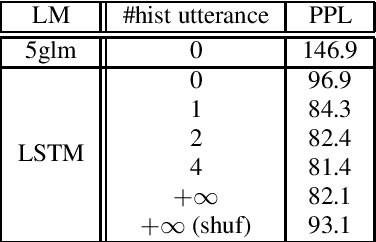

LSTM language models (LSTM-LMs) have been proven to be powerful and yielded significant performance improvements over count based n-gram LMs in modern speech recognition systems. Due to its infinite history states and computational load, most previous studies focus on applying LSTM-LMs in the second-pass for rescoring purpose. Recent work shows that it is feasible and computationally affordable to adopt the LSTM-LMs in the first-pass decoding within a dynamic (or tree based) decoder framework. In this work, the LSTM-LM is composed with a WFST decoder on-the-fly for the first-pass decoding. Furthermore, motivated by the long-term history nature of LSTM-LMs, the use of context beyond the current utterance is explored for the first-pass decoding in conversational speech recognition. The context information is captured by the hidden states of LSTM-LMs across utterance and can be used to guide the first-pass search effectively. The experimental results in our internal meeting transcription system show that significant performance improvements can be obtained by incorporating the contextual information with LSTM-LMs in the first-pass decoding, compared to applying the contextual information in the second-pass rescoring.
Long-span language modeling for speech recognition
Nov 11, 2019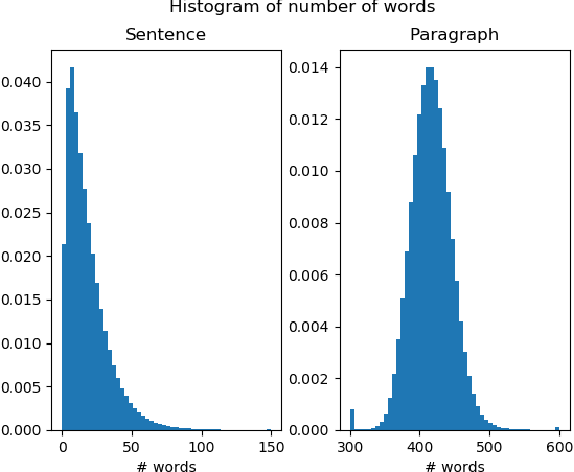
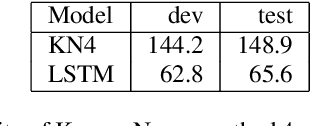
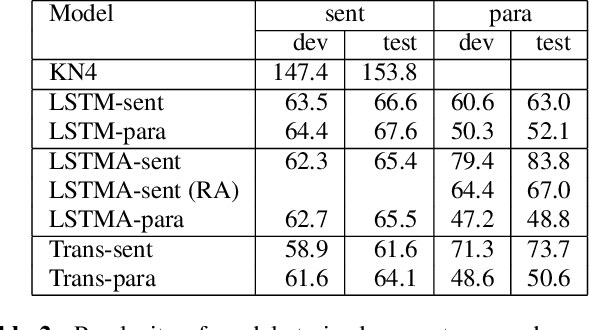
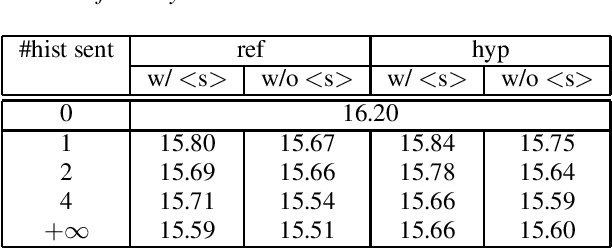
We explore neural language modeling for speech recognition where the context spans multiple sentences. Rather than encode history beyond the current sentence using a cache of words or document-level features, we focus our study on the ability of LSTM and Transformer language models to implicitly learn to carry over context across sentence boundaries. We introduce a new architecture that incorporates an attention mechanism into LSTM to combine the benefits of recurrent and attention architectures. We conduct language modeling and speech recognition experiments on the publicly available LibriSpeech corpus. We show that conventional training on a paragraph-level corpus results in significant reductions in perplexity compared to training on a sentence-level corpus. We also describe speech recognition experiments using long-span language models in second-pass re-ranking, and provide insights into the ability of such models to take advantage of context beyond the current sentence.
Deep Learning Predicts Hip Fracture using Confounding Patient and Healthcare Variables
Nov 08, 2018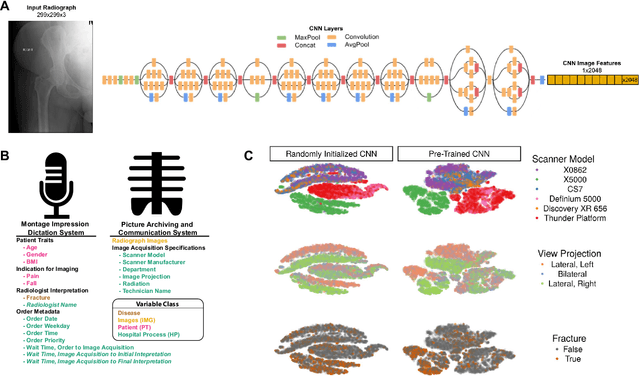
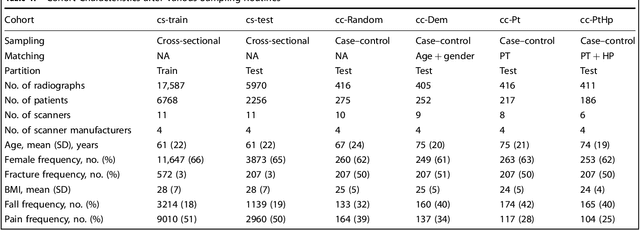
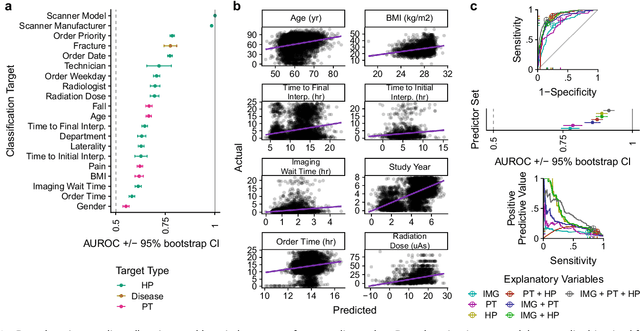
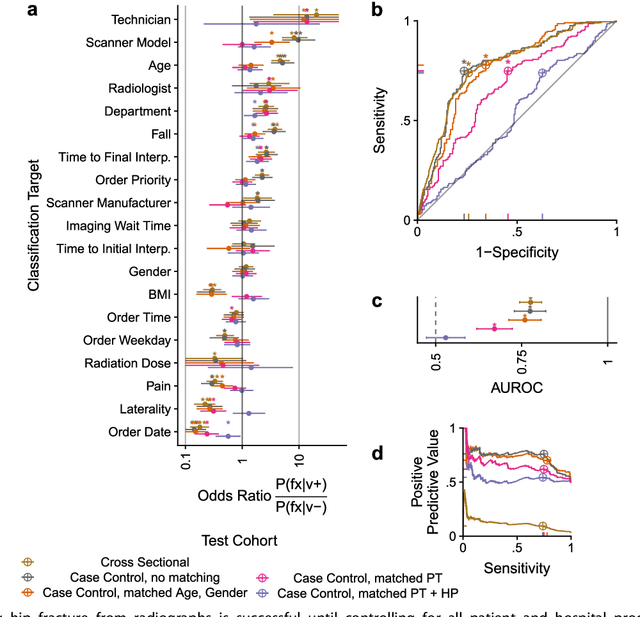
Hip fractures are a leading cause of death and disability among older adults. Hip fractures are also the most commonly missed diagnosis on pelvic radiographs. Computer-Aided Diagnosis (CAD) algorithms have shown promise for helping radiologists detect fractures, but the image features underpinning their predictions are notoriously difficult to understand. In this study, we trained deep learning models on 17,587 radiographs to classify fracture, five patient traits, and 14 hospital process variables. All 20 variables could be predicted from a radiograph (p < 0.05), with the best performances on scanner model (AUC=1.00), scanner brand (AUC=0.98), and whether the order was marked "priority" (AUC=0.79). Fracture was predicted moderately well from the image (AUC=0.78) and better when combining image features with patient data (AUC=0.86, p=2e-9) or patient data plus hospital process features (AUC=0.91, p=1e-21). The model performance on a test set with matched patient variables was significantly lower than a random test set (AUC=0.67, p=0.003); and when the test set was matched on patient and image acquisition variables, the model performed randomly (AUC=0.52, 95% CI 0.46-0.58), indicating that these variables were the main source of the model's predictive ability overall. We also used Naive Bayes to combine evidence from image models with patient and hospital data and found their inclusion improved performance, but that this approach was nevertheless inferior to directly modeling all variables. If CAD algorithms are inexplicably leveraging patient and process variables in their predictions, it is unclear how radiologists should interpret their predictions in the context of other known patient data. Further research is needed to illuminate deep learning decision processes so that computers and clinicians can effectively cooperate.
Producing radiologist-quality reports for interpretable artificial intelligence
Jun 01, 2018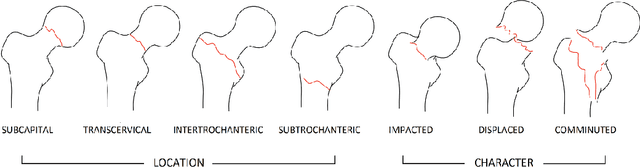
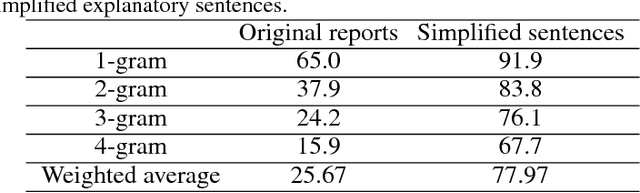
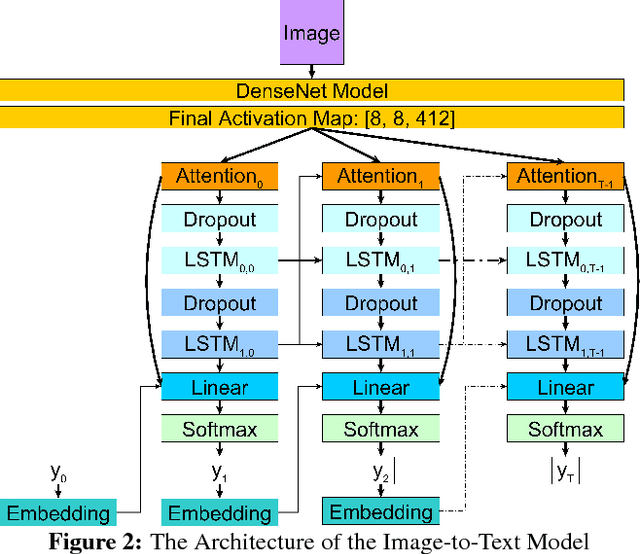

Current approaches to explaining the decisions of deep learning systems for medical tasks have focused on visualising the elements that have contributed to each decision. We argue that such approaches are not enough to "open the black box" of medical decision making systems because they are missing a key component that has been used as a standard communication tool between doctors for centuries: language. We propose a model-agnostic interpretability method that involves training a simple recurrent neural network model to produce descriptive sentences to clarify the decision of deep learning classifiers. We test our method on the task of detecting hip fractures from frontal pelvic x-rays. This process requires minimal additional labelling despite producing text containing elements that the original deep learning classification model was not specifically trained to detect. The experimental results show that: 1) the sentences produced by our method consistently contain the desired information, 2) the generated sentences are preferred by doctors compared to current tools that create saliency maps, and 3) the combination of visualisations and generated text is better than either alone.
Detecting hip fractures with radiologist-level performance using deep neural networks
Nov 17, 2017
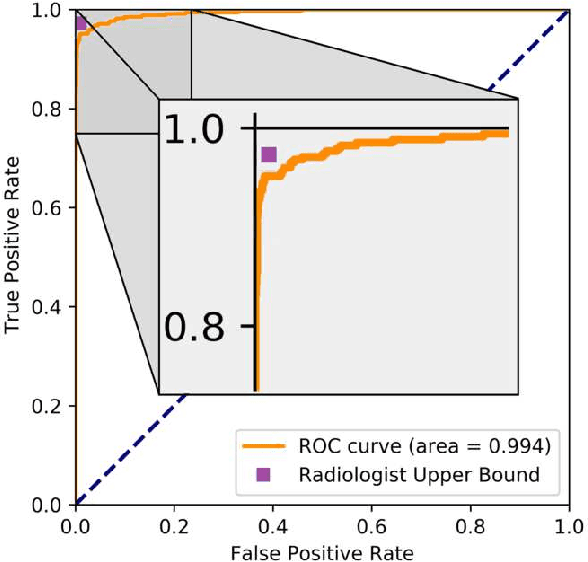


We developed an automated deep learning system to detect hip fractures from frontal pelvic x-rays, an important and common radiological task. Our system was trained on a decade of clinical x-rays (~53,000 studies) and can be applied to clinical data, automatically excluding inappropriate and technically unsatisfactory studies. We demonstrate diagnostic performance equivalent to a human radiologist and an area under the ROC curve of 0.994. Translated to clinical practice, such a system has the potential to increase the efficiency of diagnosis, reduce the need for expensive additional testing, expand access to expert level medical image interpretation, and improve overall patient outcomes.
A Stochastic Finite-State Word-Segmentation Algorithm for Chinese
May 05, 1994
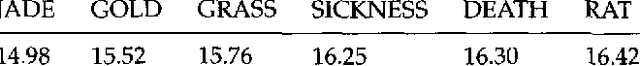
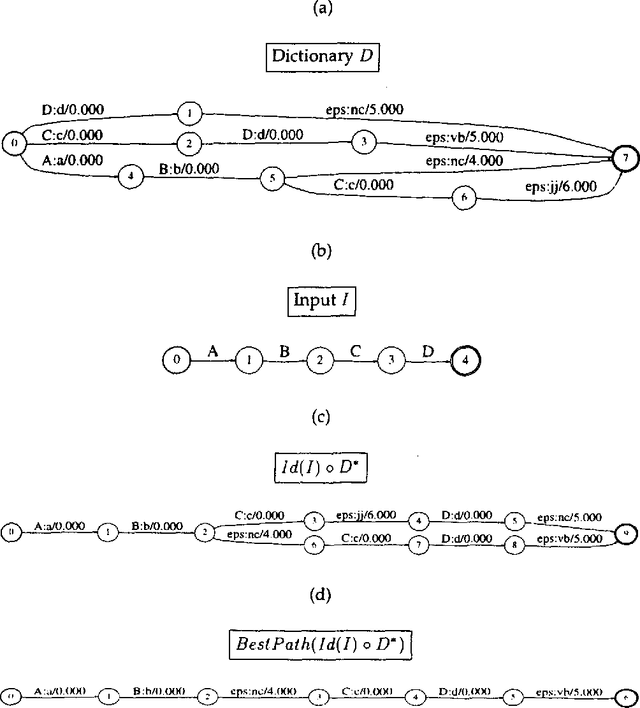
We present a stochastic finite-state model for segmenting Chinese text into dictionary entries and productively derived words, and providing pronunciations for these words; the method incorporates a class-based model in its treatment of personal names. We also evaluate the system's performance, taking into account the fact that people often do not agree on a single segmentation.
* To appear in Proceedings of ACL-94