 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading Race: AI Recognises Patient's Racial Identity In Medical Images
Jul 21, 2021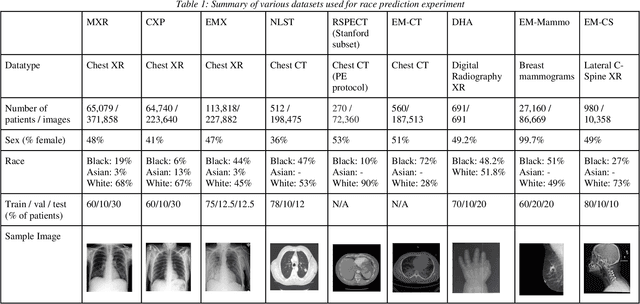
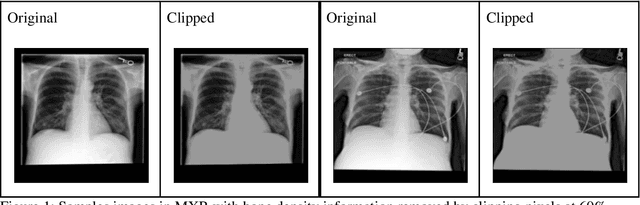
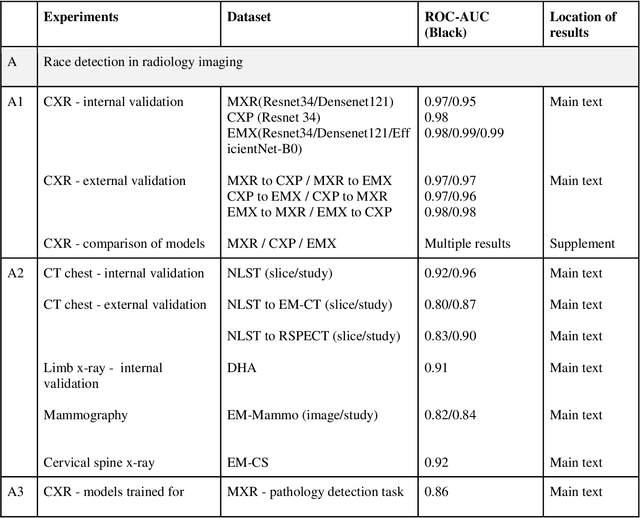
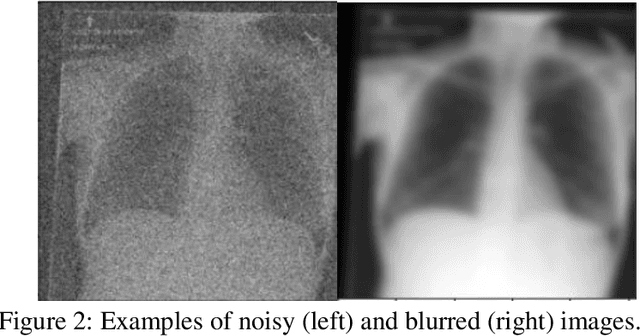
Background: In medical imaging, prior studies have demonstrated disparate AI performance by race, yet there is no known correlation for race on medical imaging that would be obvious to the human expert interpreting the images. Methods: Using private and public datasets we evaluate: A) performance quantification of deep learning models to detect race from medical images, including the ability of these models to generalize to external environments and across multiple imaging modalities, B) assessment of possible confounding anatomic and phenotype population features, such as disease distribution and body habitus as predictors of race, and C) investigation into the underlying mechanism by which AI models can recognize race. Findings: Standard deep learning models can be trained to predict race from medical images with high performance across multiple imaging modalities. Our findings hold under external validation conditions, as well as when models are optimized to perform clinically motivated tasks. We demonstrate this detection is not due to trivial proxies or imaging-related surrogate covariates for race, such as underlying disease distribution. Finally, we show that performance persists over all anatomical regions and frequency spectrum of the images suggesting that mitigation efforts will be challenging and demand further study. Interpretation: We emphasize that model ability to predict self-reported race is itself not the issue of importance. However, our findings that AI can trivially predict self-reported race -- even from corrupted, cropped, and noised medical images -- in a setting where clinical experts cannot, creates an enormous risk for all model deployments in medical imaging: if an AI model secretly used its knowledge of self-reported race to misclassify all Black patients, radiologists would not be able to tell using the same data the model has access to.
Hidden Stratification Causes Clinically Meaningful Failures in Machine Learning for Medical Imaging
Sep 27, 2019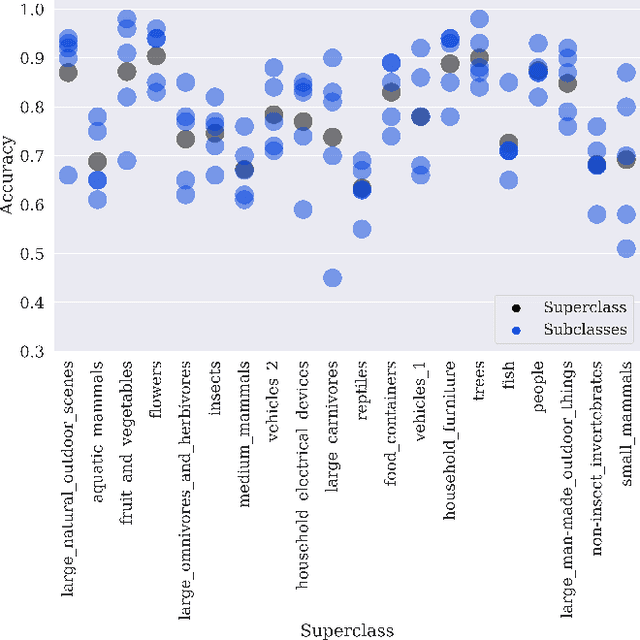

Machine learning models for medical image analysis often suffer from poor performance on important subsets of a population that are not identified during training or testing. For example, overall performance of a cancer detection model may be high, but the model still consistently misses a rare but aggressive cancer subtype. We refer to this problem as hidden stratification, and observe that it results from incompletely describing the meaningful variation in a dataset. While hidden stratification can substantially reduce the clinical efficacy of machine learning models, its effects remain difficult to measure. In this work, we assess the utility of several possible techniques for measuring and describing hidden stratification effects, and characterize these effects both on multiple medical imaging datasets and via synthetic experiments on the well-characterised CIFAR-100 benchmark dataset. We find evidence that hidden stratification can occur in unidentified imaging subsets with low prevalence, low label quality, subtle distinguishing features, or spurious correlates, and that it can result in relative performance differences of over 20% on clinically important subsets. Finally, we explore the clinical implications of our findings, and suggest that evaluation of hidden stratification should be a critical component of any machine learning deployment in medical imaging.
Exploring large scale public medical image datasets
Jul 30, 2019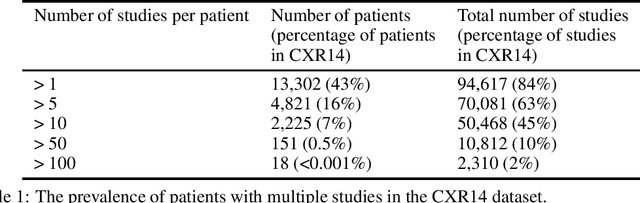

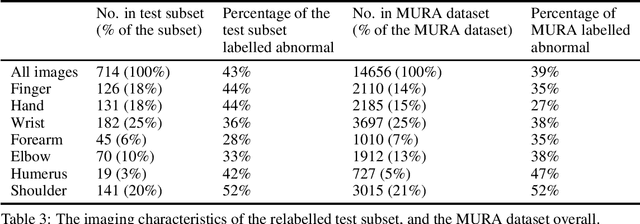
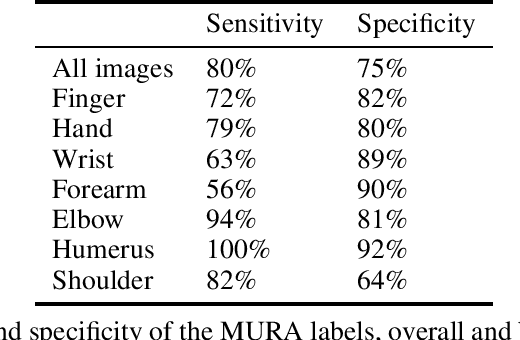
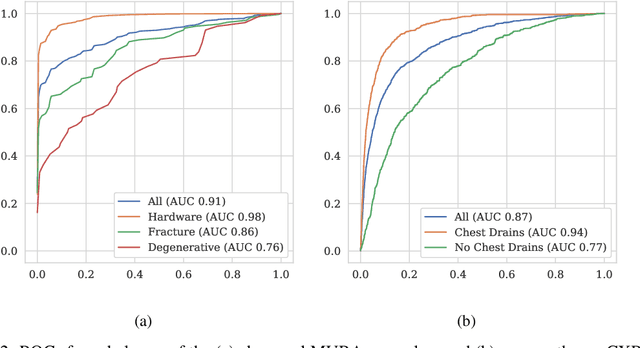
Rationale and Objectives: Medical artificial intelligence systems are dependent on well characterised large scale datasets. Recently released public datasets have been of great interest to the field, but pose specific challenges due to the disconnect they cause between data generation and data usage, potentially limiting the utility of these datasets. Materials and Methods: We visually explore two large public datasets, to determine how accurate the provided labels are and whether other subtle problems exist. The ChestXray14 dataset contains 112,120 frontal chest films, and the MURA dataset contains 40,561 upper limb radiographs. A subset of around 700 images from both datasets was reviewed by a board-certified radiologist, and the quality of the original labels was determined. Results: The ChestXray14 labels did not accurately reflect the visual content of the images, with positive predictive values mostly between 10% and 30% lower than the values presented in the original documentation. There were other significant problems, with examples of hidden stratification and label disambiguation failure. The MURA labels were more accurate, but the original normal/abnormal labels were inaccurate for the subset of cases with degenerative joint disease, with a sensitivity of 60% and a specificity of 82%. Conclusion: Visual inspection of images is a necessary component of understanding large image datasets. We recommend that teams producing public datasets should perform this important quality control procedure and include a thorough description of their findings, along with an explanation of the data generating procedures and labelling rules, in the documentation for their datasets.
Towards generative adversarial networks as a new paradigm for radiology education
Dec 04, 2018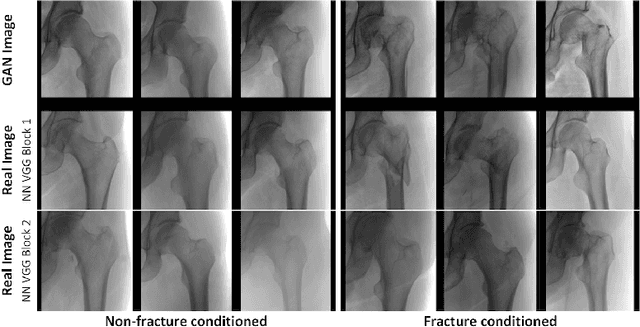
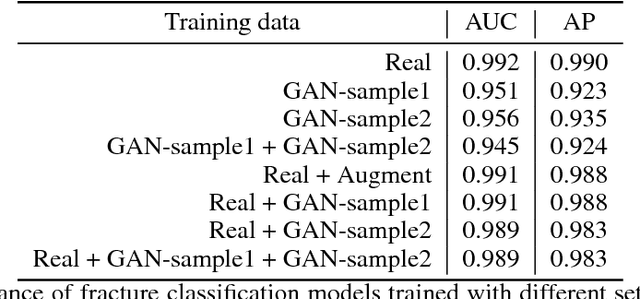


Medical students and radiology trainees typically view thousands of images in order to "train their eye" to detect the subtle visual patterns necessary for diagnosis. Nevertheless, infrastructural and legal constraints often make it difficult to access and quickly query an abundance of images with a user-specified feature set. In this paper, we use a conditional generative adversarial network (GAN) to synthesize $1024\times1024$ pixel pelvic radiographs that can be queried with conditioning on fracture status. We demonstrate that the conditional GAN learns features that distinguish fractures from non-fractures by training a convolutional neural network exclusively on images sampled from the GAN and achieving an AUC of $>0.95$ on a held-out set of real images. We conduct additional analysis of the images sampled from the GAN and describe ongoing work to validate educational efficacy.
Deep Learning Predicts Hip Fracture using Confounding Patient and Healthcare Variables
Nov 08, 2018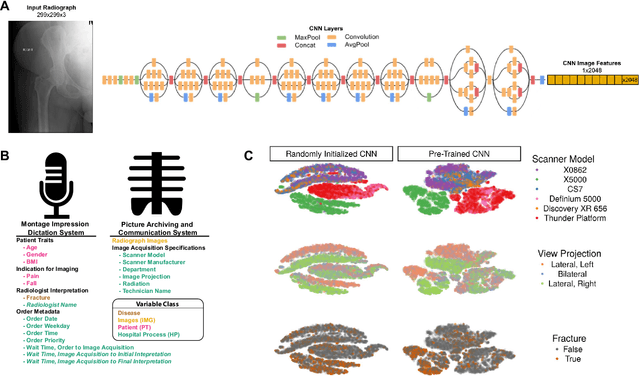
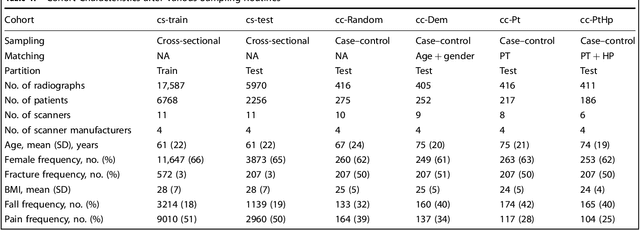
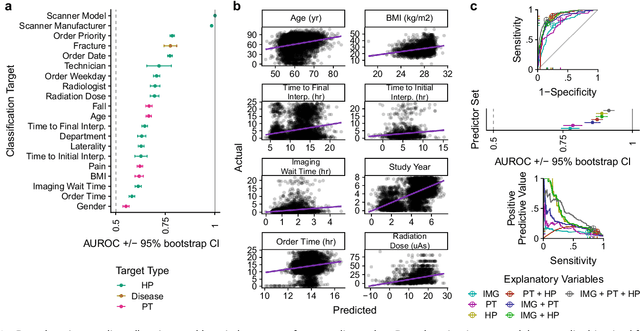
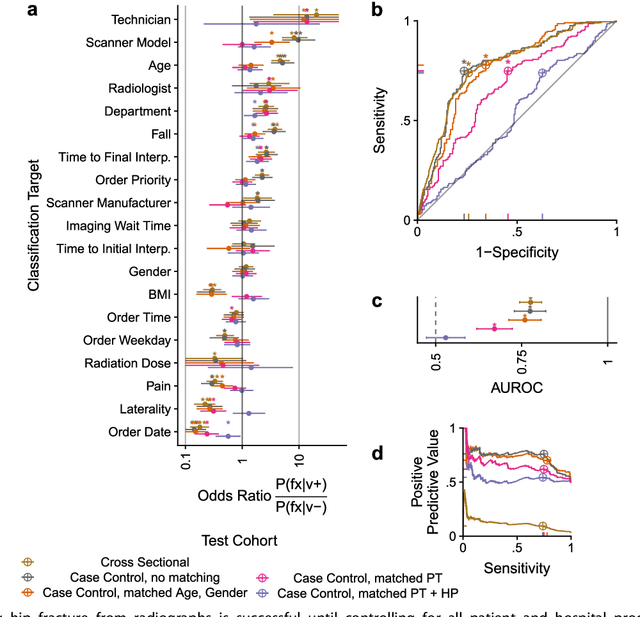
Hip fractures are a leading cause of death and disability among older adults. Hip fractures are also the most commonly missed diagnosis on pelvic radiographs. Computer-Aided Diagnosis (CAD) algorithms have shown promise for helping radiologists detect fractures, but the image features underpinning their predictions are notoriously difficult to understand. In this study, we trained deep learning models on 17,587 radiographs to classify fracture, five patient traits, and 14 hospital process variables. All 20 variables could be predicted from a radiograph (p < 0.05), with the best performances on scanner model (AUC=1.00), scanner brand (AUC=0.98), and whether the order was marked "priority" (AUC=0.79). Fracture was predicted moderately well from the image (AUC=0.78) and better when combining image features with patient data (AUC=0.86, p=2e-9) or patient data plus hospital process features (AUC=0.91, p=1e-21). The model performance on a test set with matched patient variables was significantly lower than a random test set (AUC=0.67, p=0.003); and when the test set was matched on patient and image acquisition variables, the model performed randomly (AUC=0.52, 95% CI 0.46-0.58), indicating that these variables were the main source of the model's predictive ability overall. We also used Naive Bayes to combine evidence from image models with patient and hospital data and found their inclusion improved performance, but that this approach was nevertheless inferior to directly modeling all variables. If CAD algorithms are inexplicably leveraging patient and process variables in their predictions, it is unclear how radiologists should interpret their predictions in the context of other known patient data. Further research is needed to illuminate deep learning decision processes so that computers and clinicians can effectively cooperate.
Producing radiologist-quality reports for interpretable artificial intelligence
Jun 01, 2018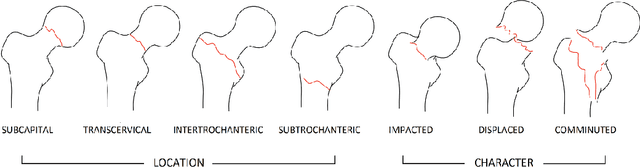
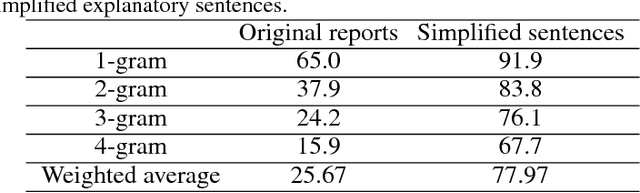
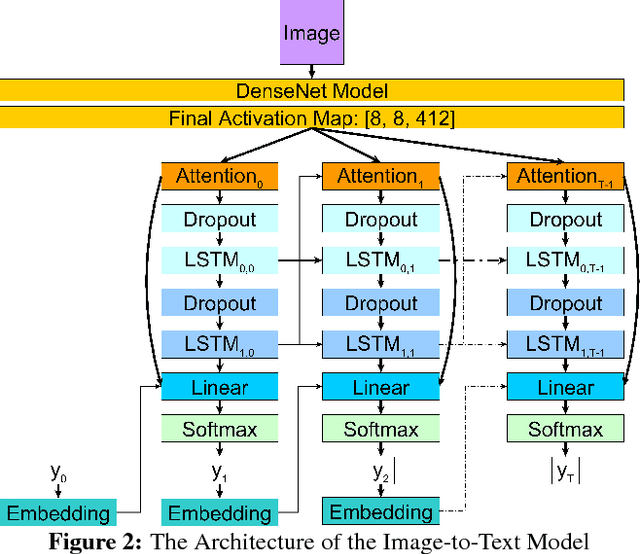

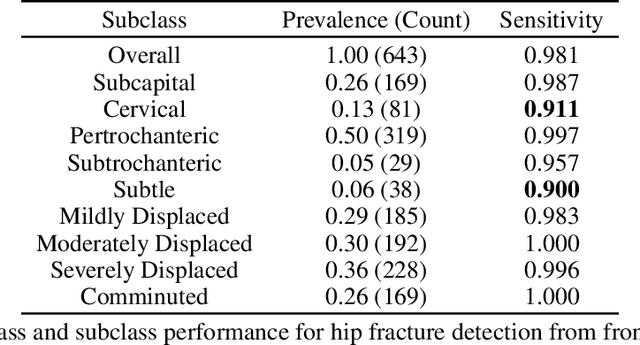
Current approaches to explaining the decisions of deep learning systems for medical tasks have focused on visualising the elements that have contributed to each decision. We argue that such approaches are not enough to "open the black box" of medical decision making systems because they are missing a key component that has been used as a standard communication tool between doctors for centuries: language. We propose a model-agnostic interpretability method that involves training a simple recurrent neural network model to produce descriptive sentences to clarify the decision of deep learning classifiers. We test our method on the task of detecting hip fractures from frontal pelvic x-rays. This process requires minimal additional labelling despite producing text containing elements that the original deep learning classification model was not specifically trained to detect. The experimental results show that: 1) the sentences produced by our method consistently contain the desired information, 2) the generated sentences are preferred by doctors compared to current tools that create saliency maps, and 3) the combination of visualisations and generated text is better than either alone.
Detecting hip fractures with radiologist-level performance using deep neural networks
Nov 17, 2017
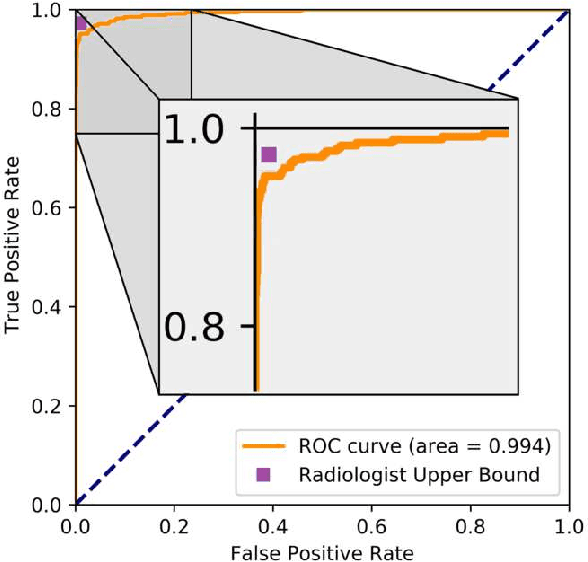


We developed an automated deep learning system to detect hip fractures from frontal pelvic x-rays, an important and common radiological task. Our system was trained on a decade of clinical x-rays (~53,000 studies) and can be applied to clinical data, automatically excluding inappropriate and technically unsatisfactory studies. We demonstrate diagnostic performance equivalent to a human radiologist and an area under the ROC curve of 0.994. Translated to clinical practice, such a system has the potential to increase the efficiency of diagnosis, reduce the need for expensive additional testing, expand access to expert level medical image interpretation, and improve overall patient outcomes.
Automated 5-year Mortality Prediction using Deep Learning and Radiomics Features from Chest Computed Tomography
Jul 01, 2016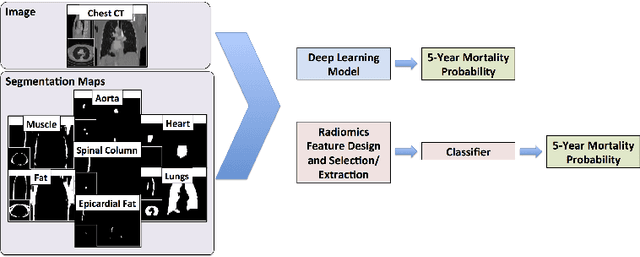
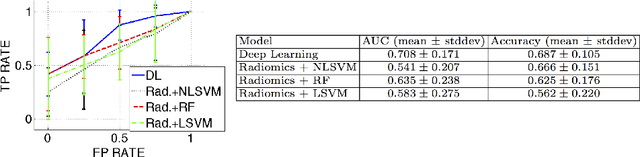
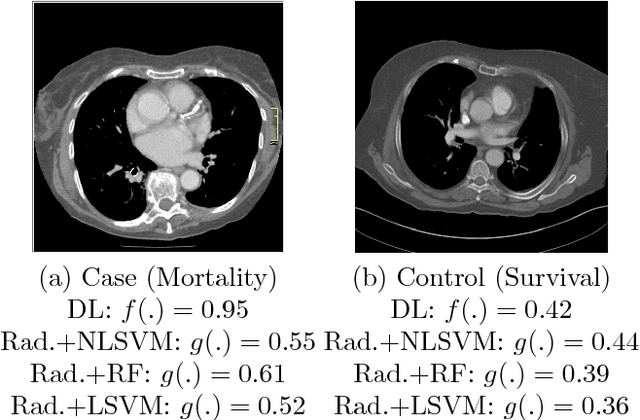
We propose new methods for the prediction of 5-year mortality in elderly individuals using chest computed tomography (CT). The methods consist of a classifier that performs this prediction using a set of features extracted from the CT image and segmentation maps of multiple anatomic structures. We explore two approaches: 1) a unified framework based on deep learning, where features and classifier are automatically learned in a single optimisation process; and 2) a multi-stage framework based on the design and selection/extraction of hand-crafted radiomics features, followed by the classifier learning process. Experimental results, based on a dataset of 48 annotated chest CTs, show that the deep learning model produces a mean 5-year mortality prediction accuracy of 68.5%, while radiomics produces a mean accuracy that varies between 56% to 66% (depending on the feature selection/extraction method and classifier). The successful development of the proposed models has the potential to make a profound impact in preventive and personalised healthcare.