 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALMo: Interactive Aim-Limit-Defined, Multi-Objective System for Personalized High-Dose-Rate Brachytherapy Treatment Planning and Visualization for Cervical Cancer
Feb 14, 2026In complex clinical decision-making, clinicians must often track a variety of competing metrics defined by aim (ideal) and limit (strict) thresholds. Sifting through these high-dimensional tradeoffs to infer the optimal patient-specific strategy is cognitively demanding and historically prone to variability. In this paper, we address this challenge within the context of High-Dose-Rate (HDR) brachytherapy for cervical cancer, where planning requires strictly managing radiation hot spots while balancing tumor coverage against organ sparing. We present ALMo (Aim-Limit-defined Multi-Objective system), an interactive decision support system designed to infer and operationalize clinician intent. ALMo employs a novel optimization framework that minimizes manual input through automated parameter setup and enables flexible control over toxicity risks. Crucially, the system allows clinicians to navigate the Pareto surface of dosimetric tradeoffs by directly manipulating intuitive aim and limit values. In a retrospective evaluation of 25 clinical cases, ALMo generated treatment plans that consistently met or exceeded manual planning quality, with 65% of cases demonstrating dosimetric improvements. Furthermore, the system significantly enhanced efficiency, reducing average planning time to approximately 17 minutes, compared to the conventional 30-60 minutes. While validated in brachytherapy, ALMo demonstrates a generalized framework for streamlining interaction in multi-criteria clinical decision-making.
MoSH: Modeling Multi-Objective Tradeoffs with Soft and Hard Bounds
Dec 09, 2024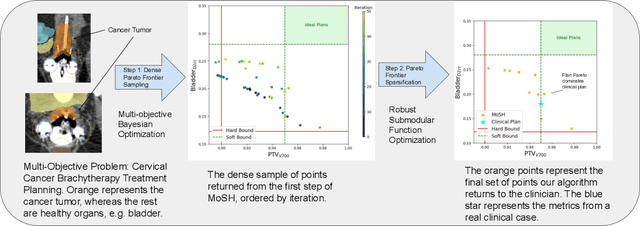
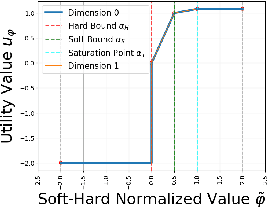
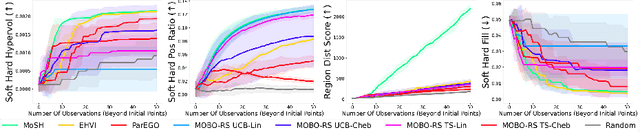
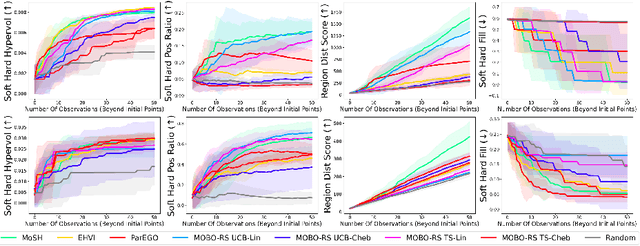
Countless science and engineering applications in multi-objective optimization (MOO) necessitate that decision-makers (DMs) select a Pareto-optimal solution which aligns with their preferences. Evaluating individual solutions is often expensive, necessitating cost-sensitive optimization techniques. Due to competing objectives, the space of trade-offs is also expansive -- thus, examining the full Pareto frontier may prove overwhelming to a DM. Such real-world settings generally have loosely-defined and context-specific desirable regions for each objective function that can aid in constraining the search over the Pareto frontier. We introduce a novel conceptual framework that operationalizes these priors using soft-hard functions, SHFs, which allow for the DM to intuitively impose soft and hard bounds on each objective -- which has been lacking in previous MOO frameworks. Leveraging a novel minimax formulation for Pareto frontier sampling, we propose a two-step process for obtaining a compact set of Pareto-optimal points which respect the user-defined soft and hard bounds: (1) densely sample the Pareto frontier using Bayesian optimization, and (2) sparsify the selected set to surface to the user, using robust submodular function optimization. We prove that (2) obtains the optimal compact Pareto-optimal set of points from (1). We further show that many practical problems fit within the SHF framework and provide extensive empirical validation on diverse domains, including brachytherapy, engineering design, and large language model personalization. Specifically, for brachytherapy, our approach returns a compact set of points with over 3% greater SHF-defined utility than the next best approach. Among the other diverse experiments, our approach consistently leads in utility, allowing the DM to reach >99% of their maximum possible desired utility within validation of 5 points.
Private Multi-Winner Voting for Machine Learning
Nov 23, 2022



Private multi-winner voting is the task of revealing $k$-hot binary vectors satisfying a bounded differential privacy (DP) guarantee. This task has been understudied in machine learning literature despite its prevalence in many domains such as healthcare. We propose three new DP multi-winner mechanisms: Binary, $\tau$, and Powerset voting. Binary voting operates independently per label through composition. $\tau$ voting bounds votes optimally in their $\ell_2$ norm for tight data-independent guarantees. Powerset voting operates over the entire binary vector by viewing the possible outcomes as a power set. Our theoretical and empirical analysis shows that Binary voting can be a competitive mechanism on many tasks unless there are strong correlations between labels, in which case Powerset voting outperforms it. We use our mechanisms to enable privacy-preserving multi-label learning in the central setting by extending the canonical single-label technique: PATE. We find that our techniques outperform current state-of-the-art approaches on large, real-world healthcare data and standard multi-label benchmarks. We further enable multi-label confidential and private collaborative (CaPC) learning and show that model performance can be significantly improved in the multi-site setting.
On the Fundamental Limits of Formally Proving Robustness in Proof-of-Learning
Aug 06, 2022



Proof-of-learning (PoL) proposes a model owner use machine learning training checkpoints to establish a proof of having expended the necessary compute for training. The authors of PoL forego cryptographic approaches and trade rigorous security guarantees for scalability to deep learning by being applicable to stochastic gradient descent and adaptive variants. This lack of formal analysis leaves the possibility that an attacker may be able to spoof a proof for a model they did not train. We contribute a formal analysis of why the PoL protocol cannot be formally (dis)proven to be robust against spoofing adversaries. To do so, we disentangle the two roles of proof verification in PoL: (a) efficiently determining if a proof is a valid gradient descent trajectory, and (b) establishing precedence by making it more expensive to craft a proof after training completes (i.e., spoofing). We show that efficient verification results in a tradeoff between accepting legitimate proofs and rejecting invalid proofs because deep learning necessarily involves noise. Without a precise analytical model for how this noise affects training, we cannot formally guarantee if a PoL verification algorithm is robust. Then, we demonstrate that establishing precedence robustly also reduces to an open problem in learning theory: spoofing a PoL post hoc training is akin to finding different trajectories with the same endpoint in non-convex learning. Yet, we do not rigorously know if priori knowledge of the final model weights helps discover such trajectories. We conclude that, until the aforementioned open problems are addressed, relying more heavily on cryptography is likely needed to formulate a new class of PoL protocols with formal robustness guarantees. In particular, this will help with establishing precedence. As a by-product of insights from our analysis, we also demonstrate two novel attacks against PoL.
Is Fairness Only Metric Deep? Evaluating and Addressing Subgroup Gaps in Deep Metric Learning
Mar 23, 2022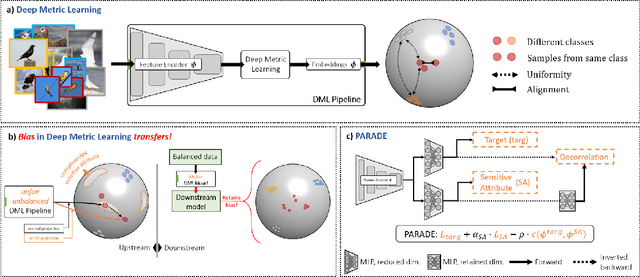
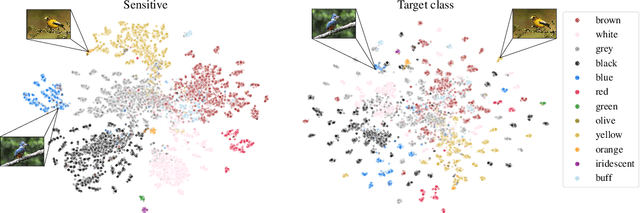
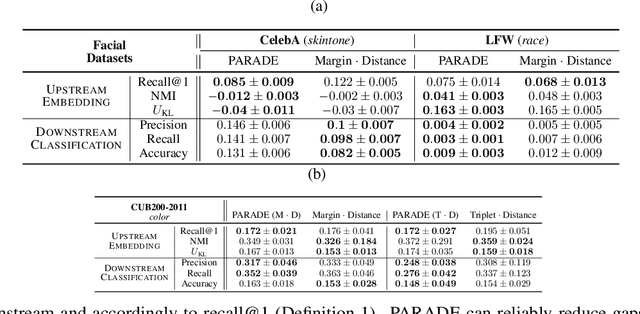
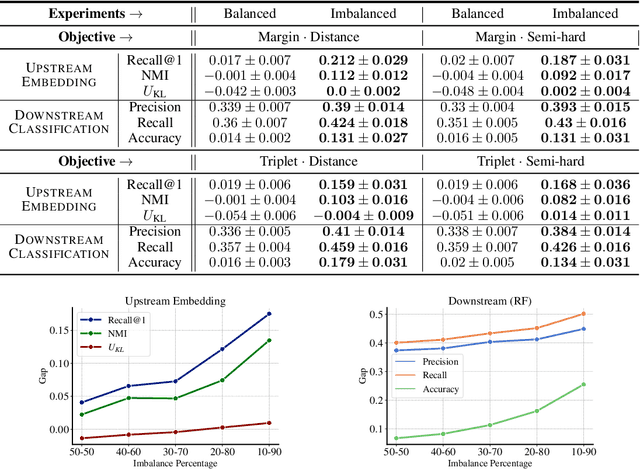
Deep metric learning (DML) enables learning with less supervision through its emphasis on the similarity structure of representations. There has been much work on improving generalization of DML in settings like zero-shot retrieval, but little is known about its implications for fairness. In this paper, we are the first to evaluate state-of-the-art DML methods trained on imbalanced data, and to show the negative impact these representations have on minority subgroup performance when used for downstream tasks. In this work, we first define fairness in DML through an analysis of three properties of the representation space -- inter-class alignment, intra-class alignment, and uniformity -- and propose finDML, the fairness in non-balanced DML benchmark to characterize representation fairness. Utilizing finDML, we find bias in DML representations to propagate to common downstream classification tasks. Surprisingly, this bias is propagated even when training data in the downstream task is re-balanced. To address this problem, we present Partial Attribute De-correlation (PARADE) to de-correlate feature representations from sensitive attributes and reduce performance gaps between subgroups in both embedding space and downstream metrics.
Improving the Fairness of Chest X-ray Classifiers
Mar 23, 2022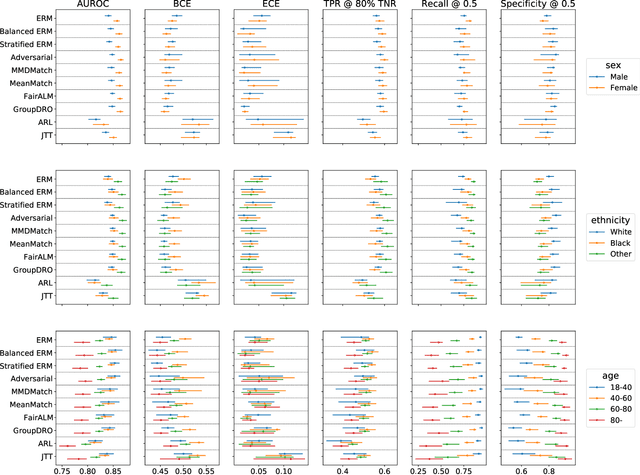
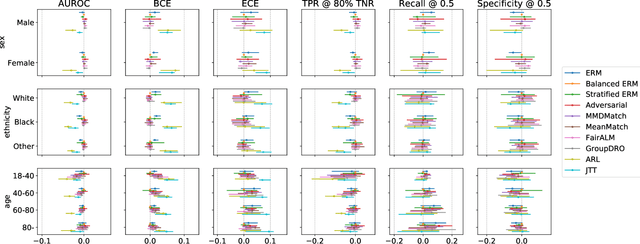
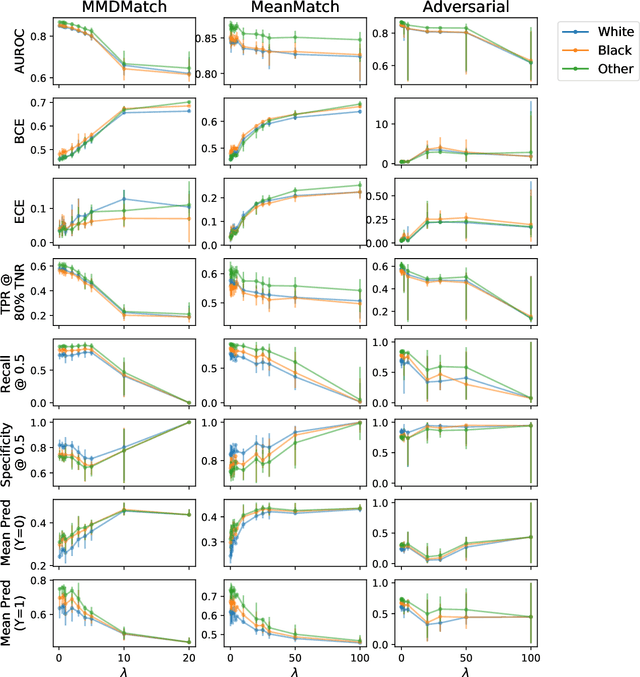
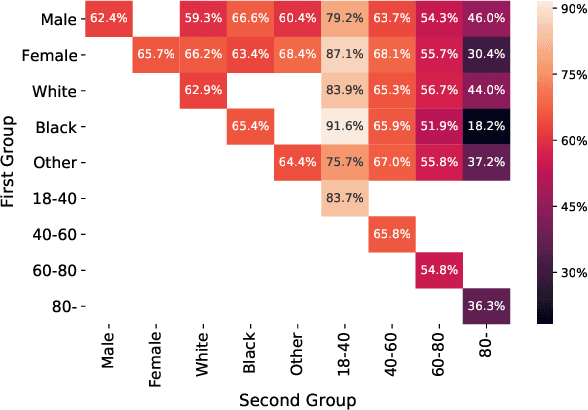
Deep learning models have reached or surpassed human-level performance in the field of medical imaging, especially in disease diagnosis using chest x-rays. However, prior work has found that such classifiers can exhibit biases in the form of gaps in predictive performance across protected groups. In this paper, we question whether striving to achieve zero disparities in predictive performance (i.e. group fairness) is the appropriate fairness definition in the clinical setting, over minimax fairness, which focuses on maximizing the performance of the worst-case group. We benchmark the performance of nine methods in improving classifier fairness across these two definitions. We find, consistent with prior work on non-clinical data, that methods which strive to achieve better worst-group performance do not outperform simple data balancing. We also find that methods which achieve group fairness do so by worsening performance for all groups. In light of these results, we discuss the utility of fairness definitions in the clinical setting, advocating for an investigation of the bias-inducing mechanisms in the underlying data generating process whenever possible.
Reading Race: AI Recognises Patient's Racial Identity In Medical Images
Jul 21, 2021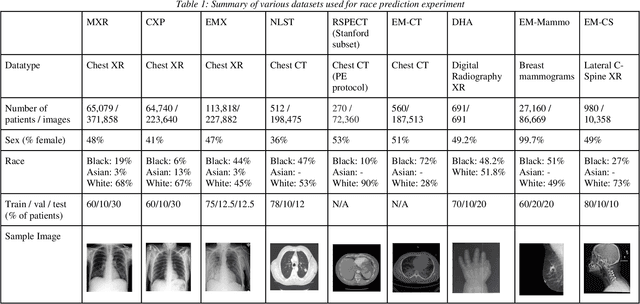
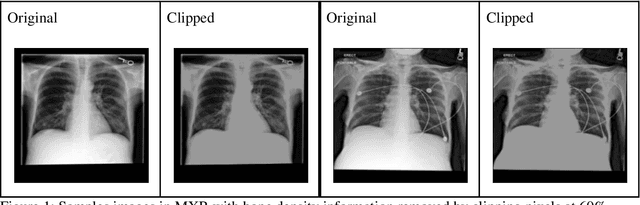
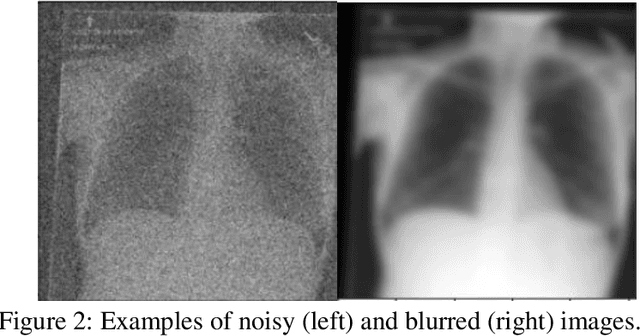
Background: In medical imaging, prior studies have demonstrated disparate AI performance by race, yet there is no known correlation for race on medical imaging that would be obvious to the human expert interpreting the images. Methods: Using private and public datasets we evaluate: A) performance quantification of deep learning models to detect race from medical images, including the ability of these models to generalize to external environments and across multiple imaging modalities, B) assessment of possible confounding anatomic and phenotype population features, such as disease distribution and body habitus as predictors of race, and C) investigation into the underlying mechanism by which AI models can recognize race. Findings: Standard deep learning models can be trained to predict race from medical images with high performance across multiple imaging modalities. Our findings hold under external validation conditions, as well as when models are optimized to perform clinically motivated tasks. We demonstrate this detection is not due to trivial proxies or imaging-related surrogate covariates for race, such as underlying disease distribution. Finally, we show that performance persists over all anatomical regions and frequency spectrum of the images suggesting that mitigation efforts will be challenging and demand further study. Interpretation: We emphasize that model ability to predict self-reported race is itself not the issue of importance. However, our findings that AI can trivially predict self-reported race -- even from corrupted, cropped, and noised medical images -- in a setting where clinical experts cannot, creates an enormous risk for all model deployments in medical imaging: if an AI model secretly used its knowledge of self-reported race to misclassify all Black patients, radiologists would not be able to tell using the same data the model has access to.
An Empirical Framework for Domain Generalization in Clinical Settings
Apr 15, 2021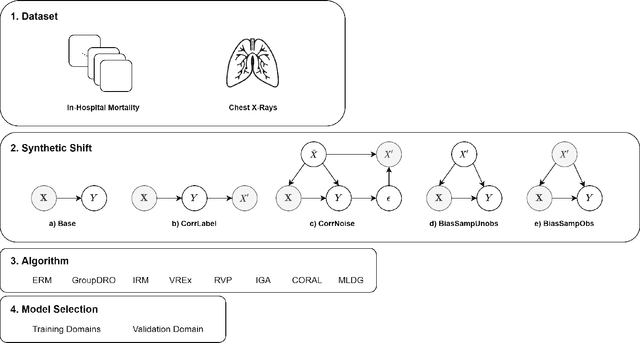

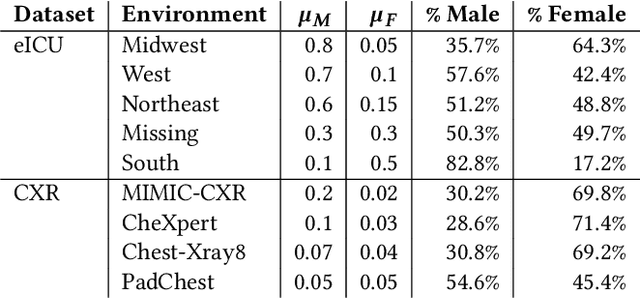
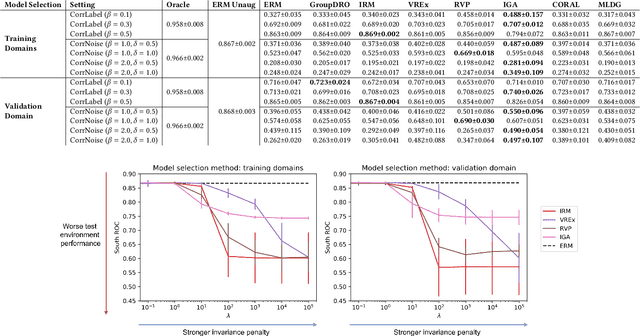
Clinical machine learning models experience significantly degraded performance in datasets not seen during training, e.g., new hospitals or populations. Recent developments in domain generalization offer a promising solution to this problem by creating models that learn invariances across environments. In this work, we benchmark the performance of eight domain generalization methods on multi-site clinical time series and medical imaging data. We introduce a framework to induce synthetic but realistic domain shifts and sampling bias to stress-test these methods over existing non-healthcare benchmarks. We find that current domain generalization methods do not consistently achieve significant gains in out-of-distribution performance over empirical risk minimization on real-world medical imaging data, in line with prior work on general imaging datasets. However, a subset of realistic induced-shift scenarios in clinical time series data do exhibit limited performance gains. We characterize these scenarios in detail, and recommend best practices for domain generalization in the clinical setting.
Proof-of-Learning: Definitions and Practice
Mar 09, 2021
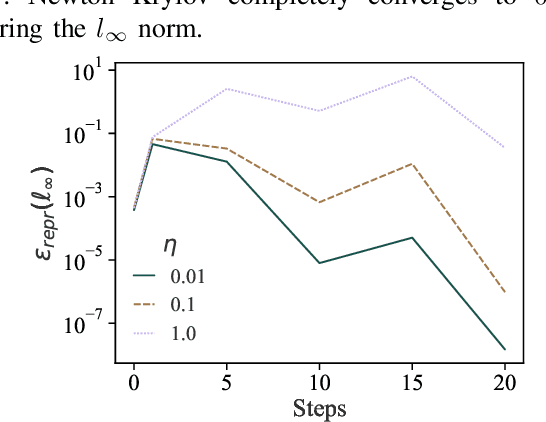
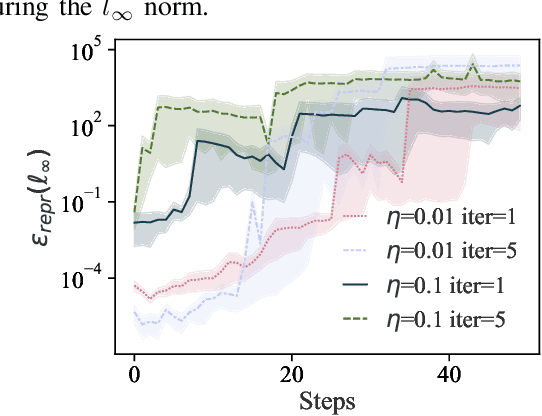
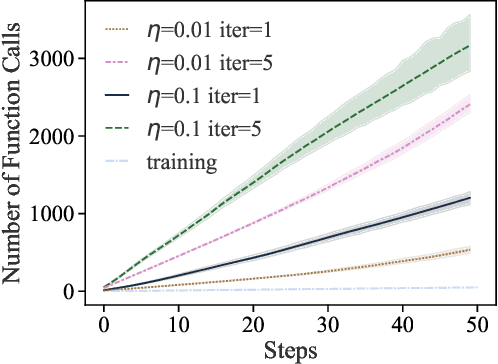
Training machine learning (ML) models typically involves expensive iterative optimization. Once the model's final parameters are released, there is currently no mechanism for the entity which trained the model to prove that these parameters were indeed the result of this optimization procedure. Such a mechanism would support security of ML applications in several ways. For instance, it would simplify ownership resolution when multiple parties contest ownership of a specific model. It would also facilitate the distributed training across untrusted workers where Byzantine workers might otherwise mount a denial-of-service by returning incorrect model updates. In this paper, we remediate this problem by introducing the concept of proof-of-learning in ML. Inspired by research on both proof-of-work and verified computations, we observe how a seminal training algorithm, stochastic gradient descent, accumulates secret information due to its stochasticity. This produces a natural construction for a proof-of-learning which demonstrates that a party has expended the compute require to obtain a set of model parameters correctly. In particular, our analyses and experiments show that an adversary seeking to illegitimately manufacture a proof-of-learning needs to perform *at least* as much work than is needed for gradient descent itself. We also instantiate a concrete proof-of-learning mechanism in both of the scenarios described above. In model ownership resolution, it protects the intellectual property of models released publicly. In distributed training, it preserves availability of the training procedure. Our empirical evaluation validates that our proof-of-learning mechanism is robust to variance induced by the hardware (ML accelerators) and software stacks.
CaPC Learning: Confidential and Private Collaborative Learning
Feb 09, 2021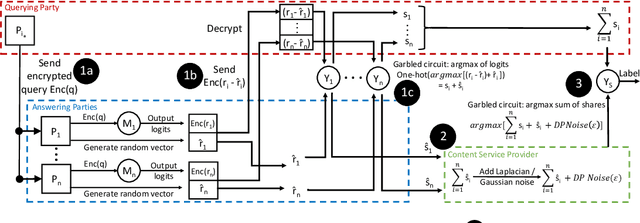

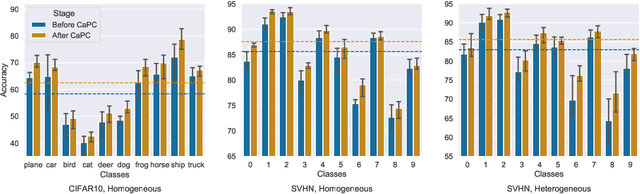
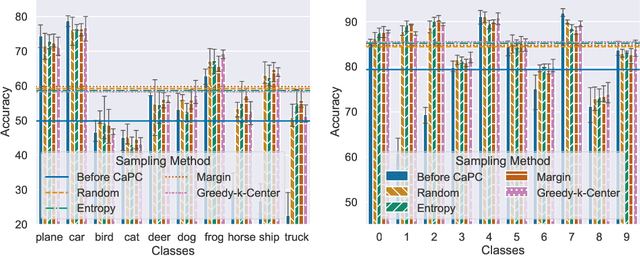
Machine learning benefits from large training datasets, which may not always be possible to collect by any single entity, especially when using privacy-sensitive data. In many contexts, such as healthcare and finance, separate parties may wish to collaborate and learn from each other's data but are prevented from doing so due to privacy regulations. Some regulations prevent explicit sharing of data between parties by joining datasets in a central location (confidentiality). Others also limit implicit sharing of data, e.g., through model predictions (privacy). There is currently no method that enables machine learning in such a setting, where both confidentiality and privacy need to be preserved, to prevent both explicit and implicit sharing of data. Federated learning only provides confidentiality, not privacy, since gradients shared still contain private information. Differentially private learning assumes unreasonably large datasets. Furthermore, both of these learning paradigms produce a central model whose architecture was previously agreed upon by all parties rather than enabling collaborative learning where each party learns and improves their own local model. We introduce Confidential and Private Collaborative (CaPC) learning, the first method provably achieving both confidentiality and privacy in a collaborative setting. We leverage secure multi-party computation (MPC), homomorphic encryption (HE), and other techniques in combination with privately aggregated teacher models. We demonstrate how CaPC allows participants to collaborate without having to explicitly join their training sets or train a central model. Each party is able to improve the accuracy and fairness of their model, even in settings where each party has a model that performs well on their own dataset or when datasets are not IID and model architectures are heterogeneous across parties.