 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorization in Self-Supervised Learning Improves Downstream Generalization
Jan 24, 2024



Self-supervised learning (SSL) has recently received significant attention due to its ability to train high-performance encoders purely on unlabeled data-often scraped from the internet. This data can still be sensitive and empirical evidence suggests that SSL encoders memorize private information of their training data and can disclose them at inference time. Since existing theoretical definitions of memorization from supervised learning rely on labels, they do not transfer to SSL. To address this gap, we propose SSLMem, a framework for defining memorization within SSL. Our definition compares the difference in alignment of representations for data points and their augmented views returned by both encoders that were trained on these data points and encoders that were not. Through comprehensive empirical analysis on diverse encoder architectures and datasets we highlight that even though SSL relies on large datasets and strong augmentations-both known in supervised learning as regularization techniques that reduce overfitting-still significant fractions of training data points experience high memorization. Through our empirical results, we show that this memorization is essential for encoders to achieve higher generalization performance on different downstream tasks.
Robust and Actively Secure Serverless Collaborative Learning
Oct 25, 2023



Collaborative machine learning (ML) is widely used to enable institutions to learn better models from distributed data. While collaborative approaches to learning intuitively protect user data, they remain vulnerable to either the server, the clients, or both, deviating from the protocol. Indeed, because the protocol is asymmetric, a malicious server can abuse its power to reconstruct client data points. Conversely, malicious clients can corrupt learning with malicious updates. Thus, both clients and servers require a guarantee when the other cannot be trusted to fully cooperate. In this work, we propose a peer-to-peer (P2P) learning scheme that is secure against malicious servers and robust to malicious clients. Our core contribution is a generic framework that transforms any (compatible) algorithm for robust aggregation of model updates to the setting where servers and clients can act maliciously. Finally, we demonstrate the computational efficiency of our approach even with 1-million parameter models trained by 100s of peers on standard datasets.
Private Multi-Winner Voting for Machine Learning
Nov 23, 2022



Private multi-winner voting is the task of revealing $k$-hot binary vectors satisfying a bounded differential privacy (DP) guarantee. This task has been understudied in machine learning literature despite its prevalence in many domains such as healthcare. We propose three new DP multi-winner mechanisms: Binary, $\tau$, and Powerset voting. Binary voting operates independently per label through composition. $\tau$ voting bounds votes optimally in their $\ell_2$ norm for tight data-independent guarantees. Powerset voting operates over the entire binary vector by viewing the possible outcomes as a power set. Our theoretical and empirical analysis shows that Binary voting can be a competitive mechanism on many tasks unless there are strong correlations between labels, in which case Powerset voting outperforms it. We use our mechanisms to enable privacy-preserving multi-label learning in the central setting by extending the canonical single-label technique: PATE. We find that our techniques outperform current state-of-the-art approaches on large, real-world healthcare data and standard multi-label benchmarks. We further enable multi-label confidential and private collaborative (CaPC) learning and show that model performance can be significantly improved in the multi-site setting.
Dataset Inference for Self-Supervised Models
Sep 16, 2022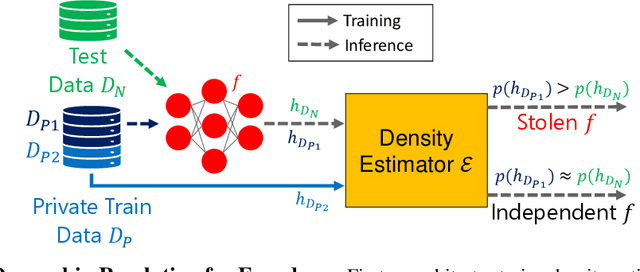
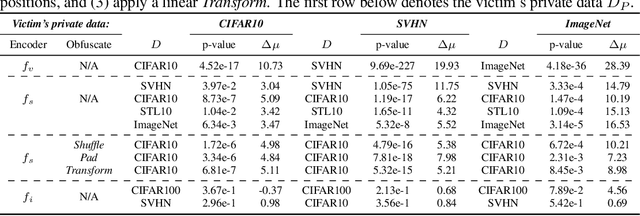
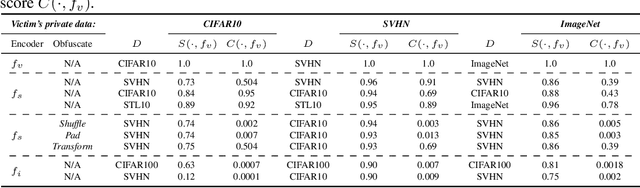
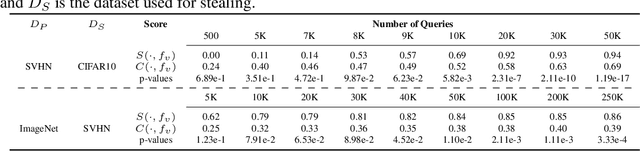
Self-supervised models are increasingly prevalent in machine learning (ML) since they reduce the need for expensively labeled data. Because of their versatility in downstream applications, they are increasingly used as a service exposed via public APIs. At the same time, these encoder models are particularly vulnerable to model stealing attacks due to the high dimensionality of vector representations they output. Yet, encoders remain undefended: existing mitigation strategies for stealing attacks focus on supervised learning. We introduce a new dataset inference defense, which uses the private training set of the victim encoder model to attribute its ownership in the event of stealing. The intuition is that the log-likelihood of an encoder's output representations is higher on the victim's training data than on test data if it is stolen from the victim, but not if it is independently trained. We compute this log-likelihood using density estimation models. As part of our evaluation, we also propose measuring the fidelity of stolen encoders and quantifying the effectiveness of the theft detection without involving downstream tasks; instead, we leverage mutual information and distance measurements. Our extensive empirical results in the vision domain demonstrate that dataset inference is a promising direction for defending self-supervised models against model stealing.
On the Difficulty of Defending Self-Supervised Learning against Model Extraction
May 16, 2022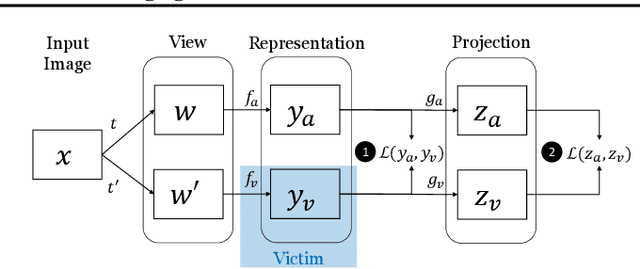
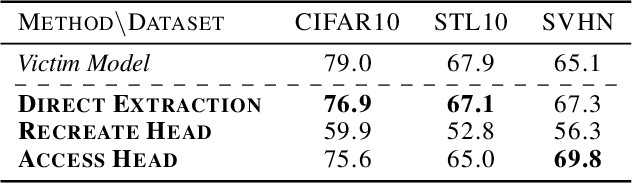
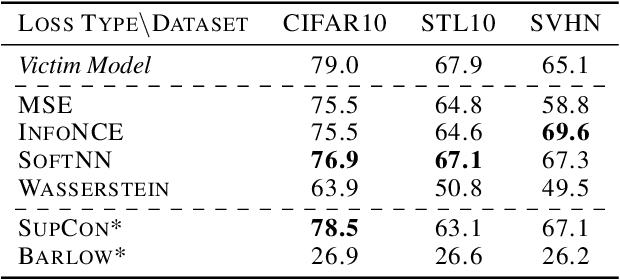
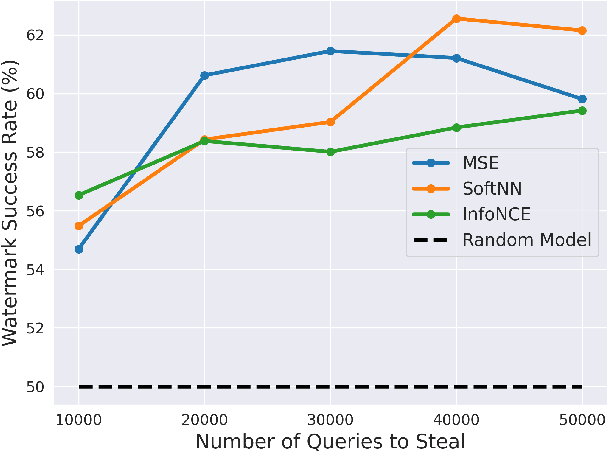
Self-Supervised Learning (SSL) is an increasingly popular ML paradigm that trains models to transform complex inputs into representations without relying on explicit labels. These representations encode similarity structures that enable efficient learning of multiple downstream tasks. Recently, ML-as-a-Service providers have commenced offering trained SSL models over inference APIs, which transform user inputs into useful representations for a fee. However, the high cost involved to train these models and their exposure over APIs both make black-box extraction a realistic security threat. We thus explore model stealing attacks against SSL. Unlike traditional model extraction on classifiers that output labels, the victim models here output representations; these representations are of significantly higher dimensionality compared to the low-dimensional prediction scores output by classifiers. We construct several novel attacks and find that approaches that train directly on a victim's stolen representations are query efficient and enable high accuracy for downstream models. We then show that existing defenses against model extraction are inadequate and not easily retrofitted to the specificities of SSL.
Increasing the Cost of Model Extraction with Calibrated Proof of Work
Jan 23, 2022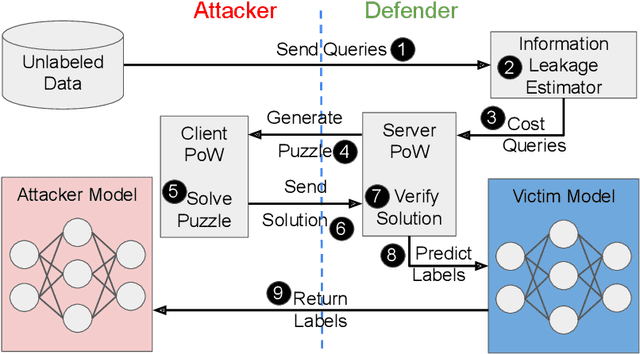

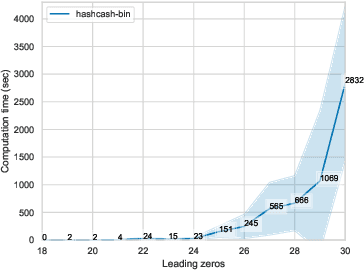
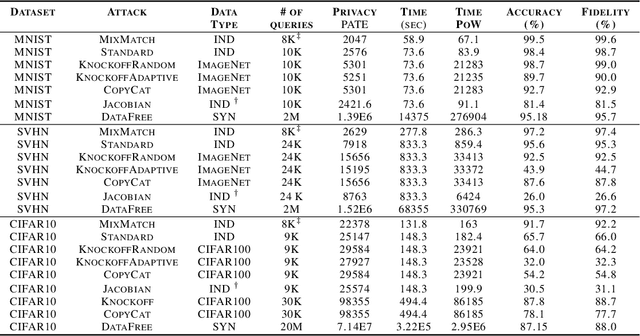
In model extraction attacks, adversaries can steal a machine learning model exposed via a public API by repeatedly querying it and adjusting their own model based on obtained predictions. To prevent model stealing, existing defenses focus on detecting malicious queries, truncating, or distorting outputs, thus necessarily introducing a tradeoff between robustness and model utility for legitimate users. Instead, we propose to impede model extraction by requiring users to complete a proof-of-work before they can read the model's predictions. This deters attackers by greatly increasing (even up to 100x) the computational effort needed to leverage query access for model extraction. Since we calibrate the effort required to complete the proof-of-work to each query, this only introduces a slight overhead for regular users (up to 2x). To achieve this, our calibration applies tools from differential privacy to measure the information revealed by a query. Our method requires no modification of the victim model and can be applied by machine learning practitioners to guard their publicly exposed models against being easily stolen.