 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning with Differential Privacy Necessitates an Additional Hyperparameter Search
Oct 05, 2022
Models need to be trained with privacy-preserving learning algorithms to prevent leakage of possibly sensitive information contained in their training data. However, canonical algorithms like differentially private stochastic gradient descent (DP-SGD) do not benefit from model scale in the same way as non-private learning. This manifests itself in the form of unappealing tradeoffs between privacy and utility (accuracy) when using DP-SGD on complex tasks. To remediate this tension, a paradigm is emerging: fine-tuning with differential privacy from a model pretrained on public (i.e., non-sensitive) training data. In this work, we identify an oversight of existing approaches for differentially private fine tuning. They do not tailor the fine-tuning approach to the specifics of learning with privacy. Our main result is to show how carefully selecting the layers being fine-tuned in the pretrained neural network allows us to establish new state-of-the-art tradeoffs between privacy and accuracy. For instance, we achieve 77.9% accuracy for $(\varepsilon, \delta)=(2, 10^{-5})$ on CIFAR-100 for a model pretrained on ImageNet. Our work calls for additional hyperparameter search to configure the differentially private fine-tuning procedure itself.
Dataset Inference for Self-Supervised Models
Sep 16, 2022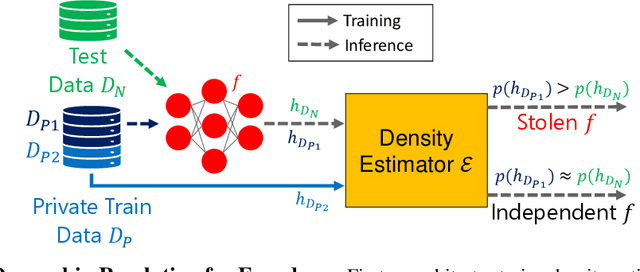
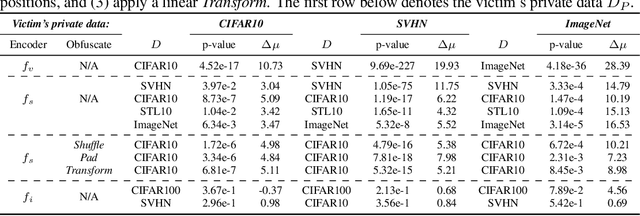
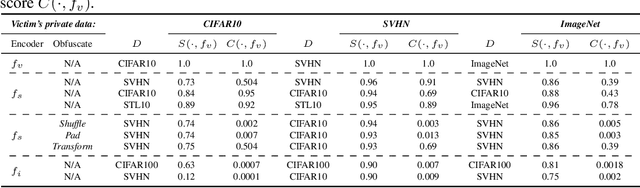
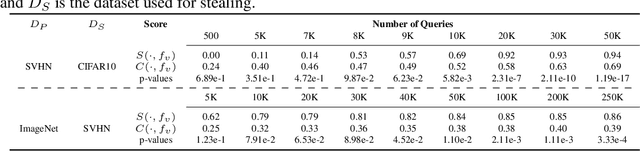
Self-supervised models are increasingly prevalent in machine learning (ML) since they reduce the need for expensively labeled data. Because of their versatility in downstream applications, they are increasingly used as a service exposed via public APIs. At the same time, these encoder models are particularly vulnerable to model stealing attacks due to the high dimensionality of vector representations they output. Yet, encoders remain undefended: existing mitigation strategies for stealing attacks focus on supervised learning. We introduce a new dataset inference defense, which uses the private training set of the victim encoder model to attribute its ownership in the event of stealing. The intuition is that the log-likelihood of an encoder's output representations is higher on the victim's training data than on test data if it is stolen from the victim, but not if it is independently trained. We compute this log-likelihood using density estimation models. As part of our evaluation, we also propose measuring the fidelity of stolen encoders and quantifying the effectiveness of the theft detection without involving downstream tasks; instead, we leverage mutual information and distance measurements. Our extensive empirical results in the vision domain demonstrate that dataset inference is a promising direction for defending self-supervised models against model stealing.