 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIH-Challenge: A Training Dataset to Improve Instruction Hierarchy on Frontier LLMs
Mar 11, 2026Instruction hierarchy (IH) defines how LLMs prioritize system, developer, user, and tool instructions under conflict, providing a concrete, trust-ordered policy for resolving instruction conflicts. IH is key to defending against jailbreaks, system prompt extractions, and agentic prompt injections. However, robust IH behavior is difficult to train: IH failures can be confounded with instruction-following failures, conflicts can be nuanced, and models can learn shortcuts such as overrefusing. We introduce IH-Challenge, a reinforcement learning training dataset, to address these difficulties. Fine-tuning GPT-5-Mini on IH-Challenge with online adversarial example generation improves IH robustness by +10.0% on average across 16 in-distribution, out-of-distribution, and human red-teaming benchmarks (84.1% to 94.1%), reduces unsafe behavior from 6.6% to 0.7% while improving helpfulness on general safety evaluations, and saturates an internal static agentic prompt injection evaluation, with minimal capability regression. We release the IH-Challenge dataset (https://huggingface.co/datasets/openai/ih-challenge) to support future research on robust instruction hierarchy.
Correlated Noise Mechanisms for Differentially Private Learning
Jun 09, 2025
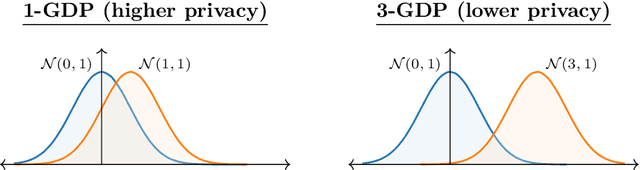

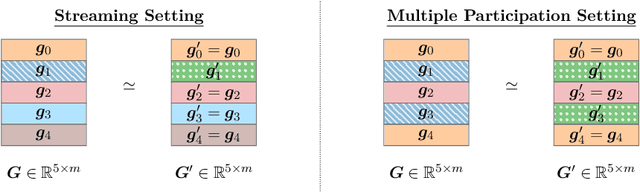
This monograph explores the design and analysis of correlated noise mechanisms for differential privacy (DP), focusing on their application to private training of AI and machine learning models via the core primitive of estimation of weighted prefix sums. While typical DP mechanisms inject independent noise into each step of a stochastic gradient (SGD) learning algorithm in order to protect the privacy of the training data, a growing body of recent research demonstrates that introducing (anti-)correlations in the noise can significantly improve privacy-utility trade-offs by carefully canceling out some of the noise added on earlier steps in subsequent steps. Such correlated noise mechanisms, known variously as matrix mechanisms, factorization mechanisms, and DP-Follow-the-Regularized-Leader (DP-FTRL) when applied to learning algorithms, have also been influential in practice, with industrial deployment at a global scale.
Strong Membership Inference Attacks on Massive Datasets and (Moderately) Large Language Models
May 24, 2025State-of-the-art membership inference attacks (MIAs) typically require training many reference models, making it difficult to scale these attacks to large pre-trained language models (LLMs). As a result, prior research has either relied on weaker attacks that avoid training reference models (e.g., fine-tuning attacks), or on stronger attacks applied to small-scale models and datasets. However, weaker attacks have been shown to be brittle - achieving close-to-arbitrary success - and insights from strong attacks in simplified settings do not translate to today's LLMs. These challenges have prompted an important question: are the limitations observed in prior work due to attack design choices, or are MIAs fundamentally ineffective on LLMs? We address this question by scaling LiRA - one of the strongest MIAs - to GPT-2 architectures ranging from 10M to 1B parameters, training reference models on over 20B tokens from the C4 dataset. Our results advance the understanding of MIAs on LLMs in three key ways: (1) strong MIAs can succeed on pre-trained LLMs; (2) their effectiveness, however, remains limited (e.g., AUC<0.7) in practical settings; and, (3) the relationship between MIA success and related privacy metrics is not as straightforward as prior work has suggested.
Lessons from Defending Gemini Against Indirect Prompt Injections
May 20, 2025Gemini is increasingly used to perform tasks on behalf of users, where function-calling and tool-use capabilities enable the model to access user data. Some tools, however, require access to untrusted data introducing risk. Adversaries can embed malicious instructions in untrusted data which cause the model to deviate from the user's expectations and mishandle their data or permissions. In this report, we set out Google DeepMind's approach to evaluating the adversarial robustness of Gemini models and describe the main lessons learned from the process. We test how Gemini performs against a sophisticated adversary through an adversarial evaluation framework, which deploys a suite of adaptive attack techniques to run continuously against past, current, and future versions of Gemini. We describe how these ongoing evaluations directly help make Gemini more resilient against manipulation.
LLMs unlock new paths to monetizing exploits
May 16, 2025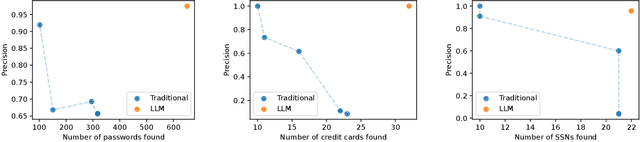
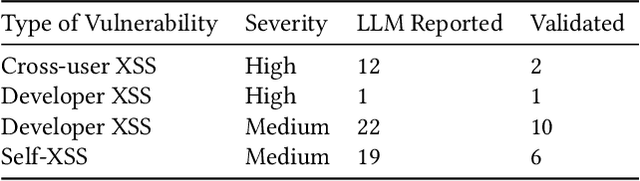
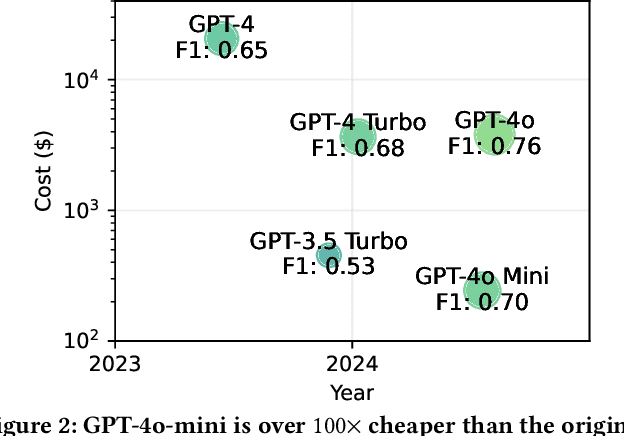

We argue that Large language models (LLMs) will soon alter the economics of cyberattacks. Instead of attacking the most commonly used software and monetizing exploits by targeting the lowest common denominator among victims, LLMs enable adversaries to launch tailored attacks on a user-by-user basis. On the exploitation front, instead of human attackers manually searching for one difficult-to-identify bug in a product with millions of users, LLMs can find thousands of easy-to-identify bugs in products with thousands of users. And on the monetization front, instead of generic ransomware that always performs the same attack (encrypt all your data and request payment to decrypt), an LLM-driven ransomware attack could tailor the ransom demand based on the particular content of each exploited device. We show that these two attacks (and several others) are imminently practical using state-of-the-art LLMs. For example, we show that without any human intervention, an LLM finds highly sensitive personal information in the Enron email dataset (e.g., an executive having an affair with another employee) that could be used for blackmail. While some of our attacks are still too expensive to scale widely today, the incentives to implement these attacks will only increase as LLMs get cheaper. Thus, we argue that LLMs create a need for new defense-in-depth approaches.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Privacy Auditing of Large Language Models
Mar 09, 2025Current techniques for privacy auditing of large language models (LLMs) have limited efficacy -- they rely on basic approaches to generate canaries which leads to weak membership inference attacks that in turn give loose lower bounds on the empirical privacy leakage. We develop canaries that are far more effective than those used in prior work under threat models that cover a range of realistic settings. We demonstrate through extensive experiments on multiple families of fine-tuned LLMs that our approach sets a new standard for detection of privacy leakage. For measuring the memorization rate of non-privately trained LLMs, our designed canaries surpass prior approaches. For example, on the Qwen2.5-0.5B model, our designed canaries achieve $49.6\%$ TPR at $1\%$ FPR, vastly surpassing the prior approach's $4.2\%$ TPR at $1\%$ FPR. Our method can be used to provide a privacy audit of $\varepsilon \approx 1$ for a model trained with theoretical $\varepsilon$ of 4. To the best of our knowledge, this is the first time that a privacy audit of LLM training has achieved nontrivial auditing success in the setting where the attacker cannot train shadow models, insert gradient canaries, or access the model at every iteration.
Privacy Ripple Effects from Adding or Removing Personal Information in Language Model Training
Feb 21, 2025Due to the sensitive nature of personally identifiable information (PII), its owners may have the authority to control its inclusion or request its removal from large-language model (LLM) training. Beyond this, PII may be added or removed from training datasets due to evolving dataset curation techniques, because they were newly scraped for retraining, or because they were included in a new downstream fine-tuning stage. We find that the amount and ease of PII memorization is a dynamic property of a model that evolves throughout training pipelines and depends on commonly altered design choices. We characterize three such novel phenomena: (1) similar-appearing PII seen later in training can elicit memorization of earlier-seen sequences in what we call assisted memorization, and this is a significant factor (in our settings, up to 1/3); (2) adding PII can increase memorization of other PII significantly (in our settings, as much as $\approx\!7.5\times$); and (3) removing PII can lead to other PII being memorized. Model creators should consider these first- and second-order privacy risks when training models to avoid the risk of new PII regurgitation.
Scaling Laws for Differentially Private Language Models
Jan 31, 2025Scaling laws have emerged as important components of large language model (LLM) training as they can predict performance gains through scale, and provide guidance on important hyper-parameter choices that would otherwise be expensive. LLMs also rely on large, high-quality training datasets, like those sourced from (sometimes sensitive) user data. Training models on this sensitive user data requires careful privacy protections like differential privacy (DP). However, the dynamics of DP training are significantly different, and consequently their scaling laws are not yet fully understood. In this work, we establish scaling laws that accurately model the intricacies of DP LLM training, providing a complete picture of the compute-privacy-utility tradeoffs and the optimal training configurations in many settings.
Exploring and Mitigating Adversarial Manipulation of Voting-Based Leaderboards
Jan 13, 2025



It is now common to evaluate Large Language Models (LLMs) by having humans manually vote to evaluate model outputs, in contrast to typical benchmarks that evaluate knowledge or skill at some particular task. Chatbot Arena, the most popular benchmark of this type, ranks models by asking users to select the better response between two randomly selected models (without revealing which model was responsible for the generations). These platforms are widely trusted as a fair and accurate measure of LLM capabilities. In this paper, we show that if bot protection and other defenses are not implemented, these voting-based benchmarks are potentially vulnerable to adversarial manipulation. Specifically, we show that an attacker can alter the leaderboard (to promote their favorite model or demote competitors) at the cost of roughly a thousand votes (verified in a simulated, offline version of Chatbot Arena). Our attack consists of two steps: first, we show how an attacker can determine which model was used to generate a given reply with more than $95\%$ accuracy; and then, the attacker can use this information to consistently vote for (or against) a target model. Working with the Chatbot Arena developers, we identify, propose, and implement mitigations to improve the robustness of Chatbot Arena against adversarial manipulation, which, based on our analysis, substantially increases the cost of such attacks. Some of these defenses were present before our collaboration, such as bot protection with Cloudflare, malicious user detection, and rate limiting. Others, including reCAPTCHA and login are being integrated to strengthen the security in Chatbot Arena.