 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Struggle to Use Representations Learned In-Context
Feb 04, 2026Though large language models (LLMs) have enabled great success across a wide variety of tasks, they still appear to fall short of one of the loftier goals of artificial intelligence research: creating an artificial system that can adapt its behavior to radically new contexts upon deployment. One important step towards this goal is to create systems that can induce rich representations of data that are seen in-context, and then flexibly deploy these representations to accomplish goals. Recently, Park et al. (2024) demonstrated that current LLMs are indeed capable of inducing such representation from context (i.e., in-context representation learning). The present study investigates whether LLMs can use these representations to complete simple downstream tasks. We first assess whether open-weights LLMs can use in-context representations for next-token prediction, and then probe models using a novel task, adaptive world modeling. In both tasks, we find evidence that open-weights LLMs struggle to deploy representations of novel semantics that are defined in-context, even if they encode these semantics in their latent representations. Furthermore, we assess closed-source, state-of-the-art reasoning models on the adaptive world modeling task, demonstrating that even the most performant LLMs cannot reliably leverage novel patterns presented in-context. Overall, this work seeks to inspire novel methods for encouraging models to not only encode information presented in-context, but to do so in a manner that supports flexible deployment of this information.
Machine Unlearning Doesn't Do What You Think: Lessons for Generative AI Policy, Research, and Practice
Dec 09, 2024



We articulate fundamental mismatches between technical methods for machine unlearning in Generative AI, and documented aspirations for broader impact that these methods could have for law and policy. These aspirations are both numerous and varied, motivated by issues that pertain to privacy, copyright, safety, and more. For example, unlearning is often invoked as a solution for removing the effects of targeted information from a generative-AI model's parameters, e.g., a particular individual's personal data or in-copyright expression of Spiderman that was included in the model's training data. Unlearning is also proposed as a way to prevent a model from generating targeted types of information in its outputs, e.g., generations that closely resemble a particular individual's data or reflect the concept of "Spiderman." Both of these goals--the targeted removal of information from a model and the targeted suppression of information from a model's outputs--present various technical and substantive challenges. We provide a framework for thinking rigorously about these challenges, which enables us to be clear about why unlearning is not a general-purpose solution for circumscribing generative-AI model behavior in service of broader positive impact. We aim for conceptual clarity and to encourage more thoughtful communication among machine learning (ML), law, and policy experts who seek to develop and apply technical methods for compliance with policy objectives.
Theoretical and Practical Perspectives on what Influence Functions Do
May 26, 2023


Influence functions (IF) have been seen as a technique for explaining model predictions through the lens of the training data. Their utility is assumed to be in identifying training examples "responsible" for a prediction so that, for example, correcting a prediction is possible by intervening on those examples (removing or editing them) and retraining the model. However, recent empirical studies have shown that the existing methods of estimating IF predict the leave-one-out-and-retrain effect poorly. In order to understand the mismatch between the theoretical promise and the practical results, we analyse five assumptions made by IF methods which are problematic for modern-scale deep neural networks and which concern convexity, numeric stability, training trajectory and parameter divergence. This allows us to clarify what can be expected theoretically from IF. We show that while most assumptions can be addressed successfully, the parameter divergence poses a clear limitation on the predictive power of IF: influence fades over training time even with deterministic training. We illustrate this theoretical result with BERT and ResNet models. Another conclusion from the theoretical analysis is that IF are still useful for model debugging and correcting even though some of the assumptions made in prior work do not hold: using natural language processing and computer vision tasks, we verify that mis-predictions can be successfully corrected by taking only a few fine-tuning steps on influential examples.
Dissecting Recall of Factual Associations in Auto-Regressive Language Models
Apr 28, 2023



Transformer-based language models (LMs) are known to capture factual knowledge in their parameters. While previous work looked into where factual associations are stored, only little is known about how they are retrieved internally during inference. We investigate this question through the lens of information flow. Given a subject-relation query, we study how the model aggregates information about the subject and relation to predict the correct attribute. With interventions on attention edges, we first identify two critical points where information propagates to the prediction: one from the relation positions followed by another from the subject positions. Next, by analyzing the information at these points, we unveil a three-step internal mechanism for attribute extraction. First, the representation at the last-subject position goes through an enrichment process, driven by the early MLP sublayers, to encode many subject-related attributes. Second, information from the relation propagates to the prediction. Third, the prediction representation "queries" the enriched subject to extract the attribute. Perhaps surprisingly, this extraction is typically done via attention heads, which often encode subject-attribute mappings in their parameters. Overall, our findings introduce a comprehensive view of how factual associations are stored and extracted internally in LMs, facilitating future research on knowledge localization and editing.
Make Every Example Count: On Stability and Utility of Self-Influence for Learning from Noisy NLP Datasets
Feb 27, 2023Increasingly larger datasets have become a standard ingredient to advancing the state of the art in NLP. However, data quality might have already become the bottleneck to unlock further gains. Given the diversity and the sizes of modern datasets, standard data filtering is not straight-forward to apply, because of the multifacetedness of the harmful data and elusiveness of filtering rules that would generalize across multiple tasks. We study the fitness of task-agnostic self-influence scores of training examples for data cleaning, analyze their efficacy in capturing naturally occurring outliers, and investigate to what extent self-influence based data cleaning can improve downstream performance in machine translation, question answering and text classification, building up on recent approaches to self-influence calculation and automated curriculum learning.
Understanding Text Classification Data and Models Using Aggregated Input Salience
Nov 11, 2022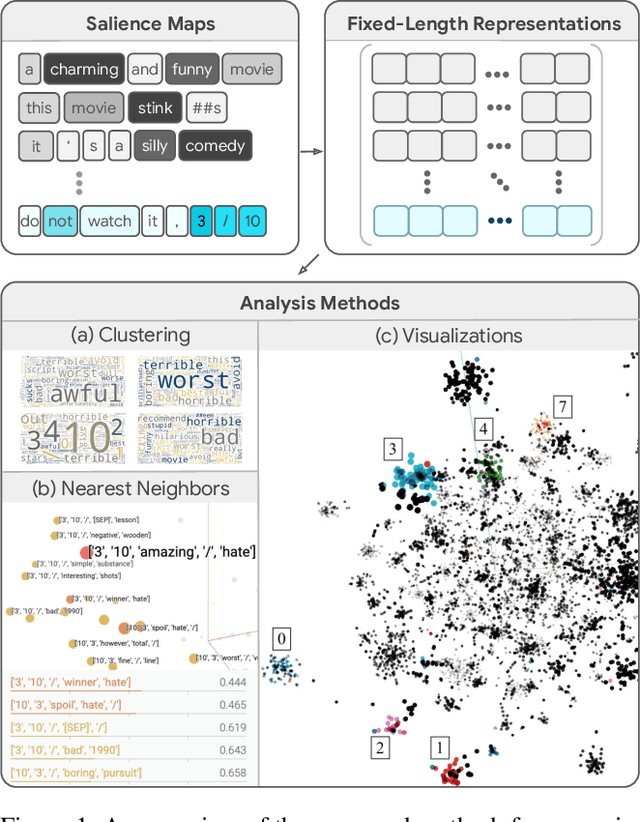
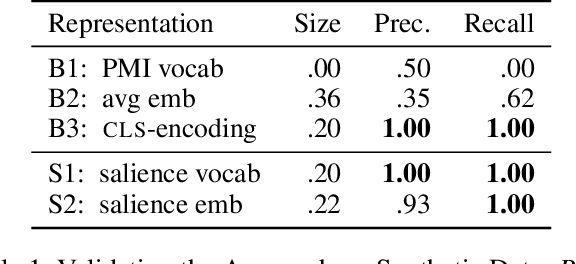

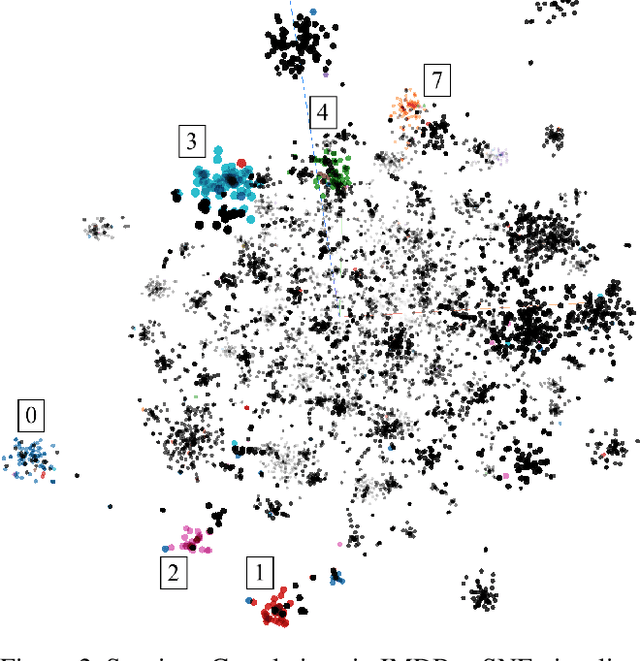
Realizing when a model is right for a wrong reason is not trivial and requires a significant effort by model developers. In some cases, an input salience method, which highlights the most important parts of the input, may reveal problematic reasoning. But scrutinizing highlights over many data instances is tedious and often infeasible. Furthermore, analyzing examples in isolation does not reveal general patterns in the data or in the model's behavior. In this paper we aim to address these issues and go from understanding single examples to understanding entire datasets and models. The methodology we propose is based on aggregated salience maps. Using this methodology we address multiple distinct but common model developer needs by showing how problematic data and model behavior can be identified -- a necessary first step for improving the model.
Diagnosing AI Explanation Methods with Folk Concepts of Behavior
Jan 27, 2022
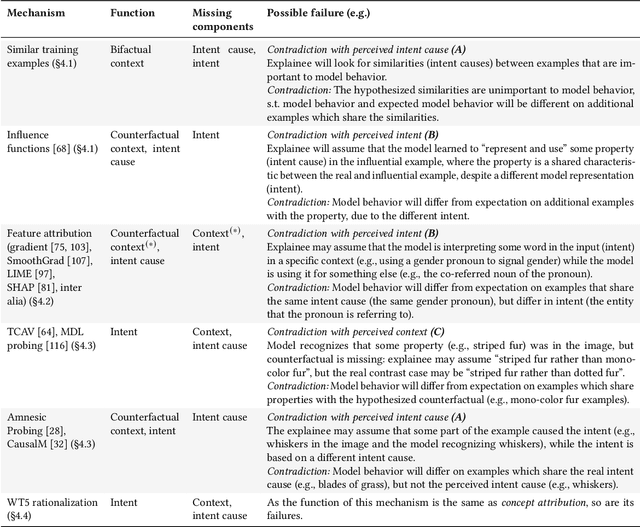
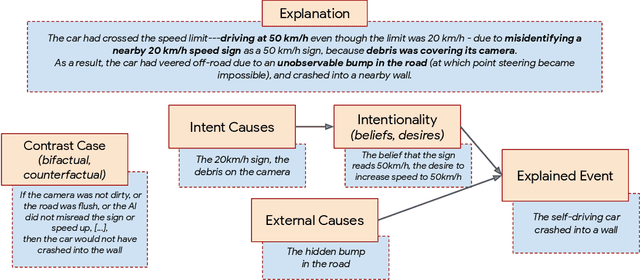

When explaining AI behavior to humans, how is the communicated information being comprehended by the human explainee, and does it match what the explanation attempted to communicate? When can we say that an explanation is explaining something? We aim to provide an answer by leveraging theory of mind literature about the folk concepts that humans use to understand behavior. We establish a framework of social attribution by the human explainee, which describes the function of explanations: the concrete information that humans comprehend from them. Specifically, effective explanations should be coherent (communicate information which generalizes to other contrast cases), complete (communicating an explicit contrast case, objective causes, and subjective causes), and interactive (surfacing and resolving contradictions to the generalization property through iterations). We demonstrate that many XAI mechanisms can be mapped to folk concepts of behavior. This allows us to uncover their modes of failure that prevent current methods from explaining effectively, and what is necessary to enable coherent explanations.
"Will You Find These Shortcuts?" A Protocol for Evaluating the Faithfulness of Input Salience Methods for Text Classification
Nov 14, 2021
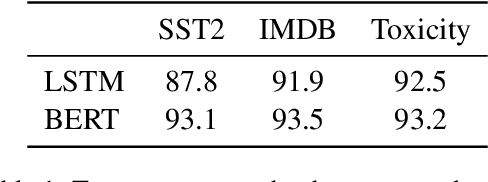


Feature attribution a.k.a. input salience methods which assign an importance score to a feature are abundant but may produce surprisingly different results for the same model on the same input. While differences are expected if disparate definitions of importance are assumed, most methods claim to provide faithful attributions and point at the features most relevant for a model's prediction. Existing work on faithfulness evaluation is not conclusive and does not provide a clear answer as to how different methods are to be compared. Focusing on text classification and the model debugging scenario, our main contribution is a protocol for faithfulness evaluation that makes use of partially synthetic data to obtain ground truth for feature importance ranking. Following the protocol, we do an in-depth analysis of four standard salience method classes on a range of datasets and shortcuts for BERT and LSTM models and demonstrate that some of the most popular method configurations provide poor results even for simplest shortcuts. We recommend following the protocol for each new task and model combination to find the best method for identifying shortcuts.
Controlled Hallucinations: Learning to Generate Faithfully from Noisy Data
Oct 12, 2020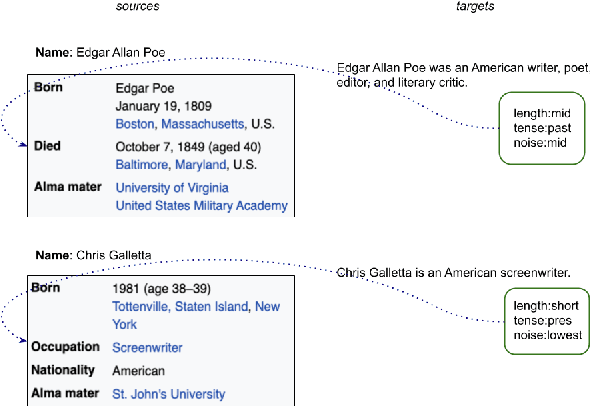


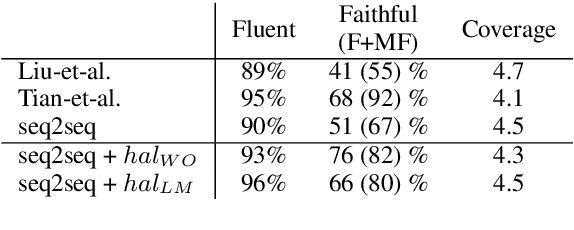
Neural text generation (data- or text-to-text) demonstrates remarkable performance when training data is abundant which for many applications is not the case. To collect a large corpus of parallel data, heuristic rules are often used but they inevitably let noise into the data, such as phrases in the output which cannot be explained by the input. Consequently, models pick up on the noise and may hallucinate--generate fluent but unsupported text. Our contribution is a simple but powerful technique to treat such hallucinations as a controllable aspect of the generated text, without dismissing any input and without modifying the model architecture. On the WikiBio corpus (Lebret et al., 2016), a particularly noisy dataset, we demonstrate the efficacy of the technique both in an automatic and in a human evaluation.
The elephant in the interpretability room: Why use attention as explanation when we have saliency methods?
Oct 12, 2020
There is a recent surge of interest in using attention as explanation of model predictions, with mixed evidence on whether attention can be used as such. While attention conveniently gives us one weight per input token and is easily extracted, it is often unclear toward what goal it is used as explanation. We find that often that goal, whether explicitly stated or not, is to find out what input tokens are the most relevant to a prediction, and that the implied user for the explanation is a model developer. For this goal and user, we argue that input saliency methods are better suited, and that there are no compelling reasons to use attention, despite the coincidence that it provides a weight for each input. With this position paper, we hope to shift some of the recent focus on attention to saliency methods, and for authors to clearly state the goal and user for their explanations.
* Accepted at BlackboxNLP 2020