 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Room: Narrative Generation through Multi-step Collaboration
Oct 03, 2024Writing compelling fiction is a multifaceted process combining elements such as crafting a plot, developing interesting characters, and using evocative language. While large language models (LLMs) show promise for story writing, they currently rely heavily on intricate prompting, which limits their use. We propose Agents' Room, a generation framework inspired by narrative theory, that decomposes narrative writing into subtasks tackled by specialized agents. To illustrate our method, we introduce Tell Me A Story, a high-quality dataset of complex writing prompts and human-written stories, and a novel evaluation framework designed specifically for assessing long narratives. We show that Agents' Room generates stories that are preferred by expert evaluators over those produced by baseline systems by leveraging collaboration and specialization to decompose the complex story writing task into tractable components. We provide extensive analysis with automated and human-based metrics of the generated output.
Understanding Text Classification Data and Models Using Aggregated Input Salience
Nov 11, 2022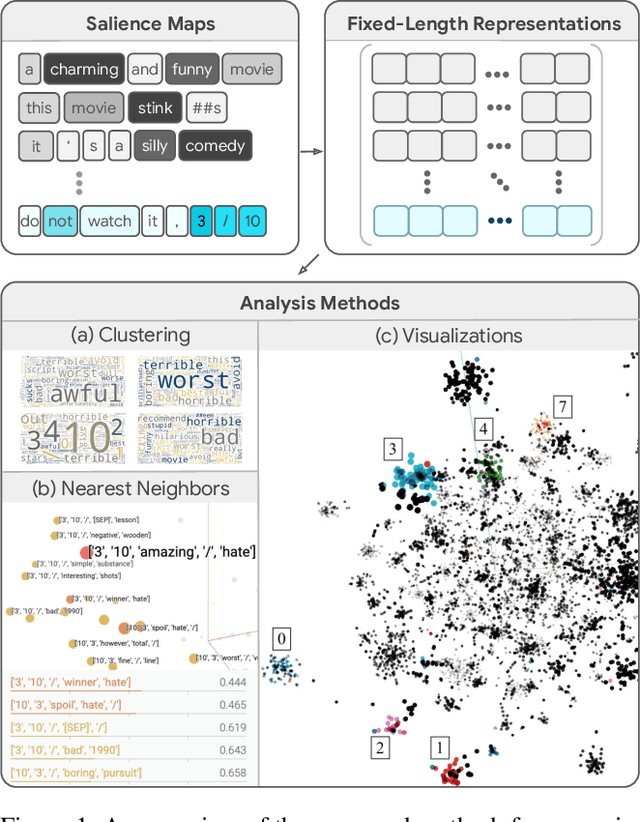
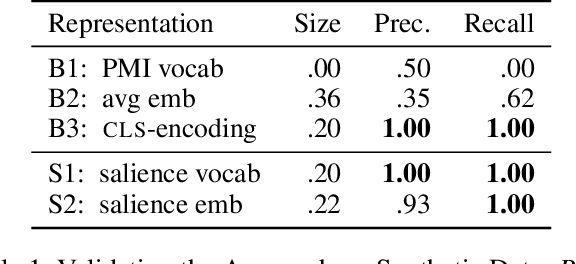

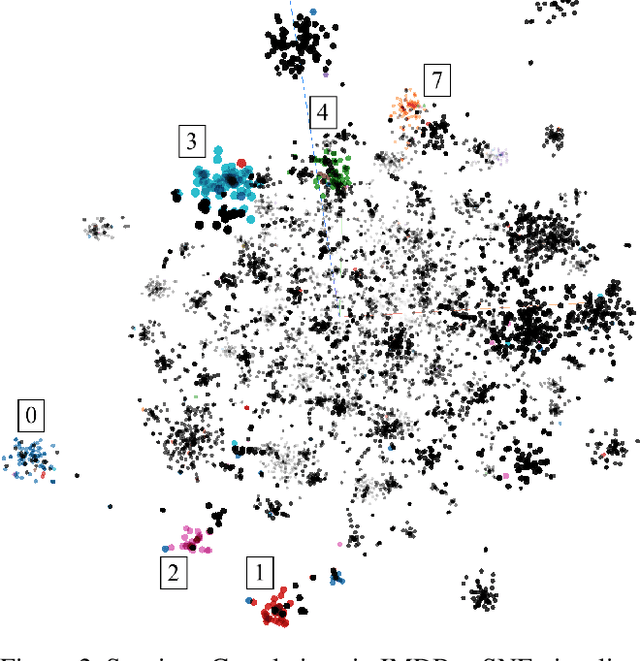
Realizing when a model is right for a wrong reason is not trivial and requires a significant effort by model developers. In some cases, an input salience method, which highlights the most important parts of the input, may reveal problematic reasoning. But scrutinizing highlights over many data instances is tedious and often infeasible. Furthermore, analyzing examples in isolation does not reveal general patterns in the data or in the model's behavior. In this paper we aim to address these issues and go from understanding single examples to understanding entire datasets and models. The methodology we propose is based on aggregated salience maps. Using this methodology we address multiple distinct but common model developer needs by showing how problematic data and model behavior can be identified -- a necessary first step for improving the model.
What Did You Say? Task-Oriented Dialog Datasets Are Not Conversational!?
Mar 07, 2022
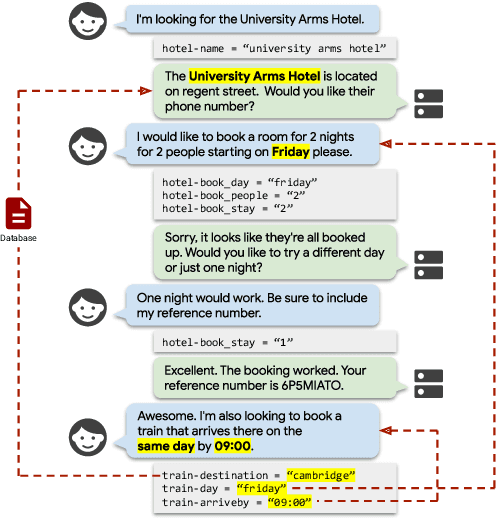
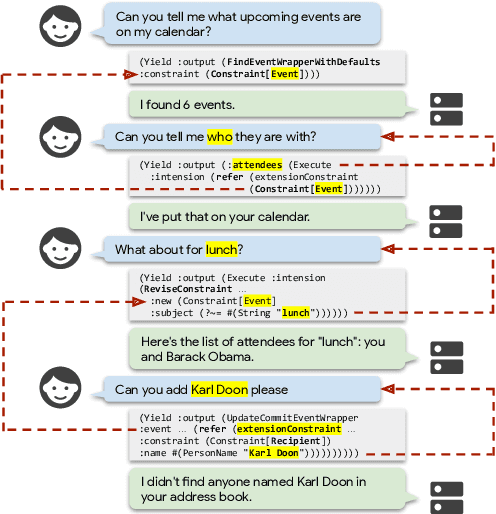

High-quality datasets for task-oriented dialog are crucial for the development of virtual assistants. Yet three of the most relevant large scale dialog datasets suffer from one common flaw: the dialog state update can be tracked, to a great extent, by a model that only considers the current user utterance, ignoring the dialog history. In this work, we outline a taxonomy of conversational and contextual effects, which we use to examine MultiWOZ, SGD and SMCalFlow, among the most recent and widely used task-oriented dialog datasets. We analyze the datasets in a model-independent fashion and corroborate these findings experimentally using a strong text-to-text baseline (T5). We find that less than 4% of MultiWOZ's turns and 10% of SGD's turns are conversational, while SMCalFlow is not conversational at all in its current release: its dialog state tracking task can be reduced to single exchange semantic parsing. We conclude by outlining desiderata for truly conversational dialog datasets.
Neural Code Comprehension: A Learnable Representation of Code Semantics
Jul 31, 2018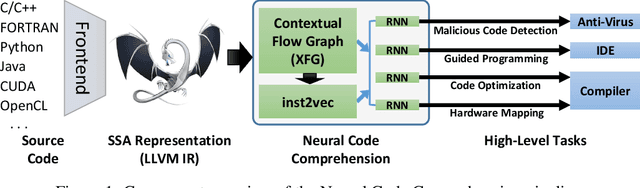

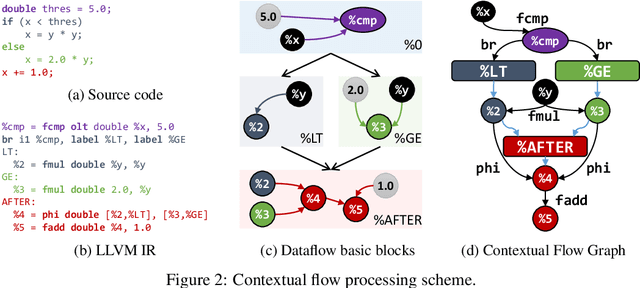

With the recent success of embeddings in natural language processing, research has been conducted into applying similar methods to code analysis. Most works attempt to process the code directly or use a syntactic tree representation, treating it like sentences written in a natural language. However, none of the existing methods are sufficient to comprehend program semantics robustly, due to structural features such as function calls, branching, and interchangeable order of statements. In this paper, we propose a novel processing technique to learn code semantics, and apply it to a variety of program analysis tasks. In particular, we stipulate that a robust distributional hypothesis of code applies to both human- and machine-generated programs. Following this hypothesis, we define an embedding space, inst2vec, based on an Intermediate Representation (IR) of the code that is independent of the source programming language. We provide a novel definition of contextual flow for this IR, leveraging both the underlying data- and control-flow of the program. We then analyze the embeddings qualitatively using analogies and clustering, and evaluate the learned representation on three different high-level tasks. We show that with a single RNN architecture and pre-trained fixed embeddings, inst2vec outperforms specialized approaches for performance prediction (compute device mapping, optimal thread coarsening); and algorithm classification from raw code (104 classes), where we set a new state-of-the-art.