 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful Chart Summarization with ChaTS-Pi
May 29, 2024Chart-to-summary generation can help explore data, communicate insights, and help the visually impaired people. Multi-modal generative models have been used to produce fluent summaries, but they can suffer from factual and perceptual errors. In this work we present CHATS-CRITIC, a reference-free chart summarization metric for scoring faithfulness. CHATS-CRITIC is composed of an image-to-text model to recover the table from a chart, and a tabular entailment model applied to score the summary sentence by sentence. We find that CHATS-CRITIC evaluates the summary quality according to human ratings better than reference-based metrics, either learned or n-gram based, and can be further used to fix candidate summaries by removing not supported sentences. We then introduce CHATS-PI, a chart-to-summary pipeline that leverages CHATS-CRITIC during inference to fix and rank sampled candidates from any chart-summarization model. We evaluate CHATS-PI and CHATS-CRITIC using human raters, establishing state-of-the-art results on two popular chart-to-summary datasets.
Structsum Generation for Faster Text Comprehension
Jan 12, 2024



We consider the task of generating structured representations of text using large language models (LLMs). We focus on tables and mind maps as representative modalities. Tables are more organized way of representing data, while mind maps provide a visually dynamic and flexible approach, particularly suitable for sparse content. Despite the effectiveness of LLMs on different tasks, we show that current models struggle with generating structured outputs. In response, we present effective prompting strategies for both of these tasks. We introduce a taxonomy of problems around factuality, global and local structure, common to both modalities and propose a set of critiques to tackle these issues resulting in an absolute improvement in accuracy of +37pp (79%) for mind maps and +15pp (78%) for tables. To evaluate semantic coverage of generated structured representations we propose Auto-QA, and we verify the adequacy of Auto-QA using SQuAD dataset. We further evaluate the usefulness of structured representations via a text comprehension user study. The results show a significant reduction in comprehension time compared to text when using table (42.9%) and mind map (31.9%), without loss in accuracy.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
mmT5: Modular Multilingual Pre-Training Solves Source Language Hallucinations
May 23, 2023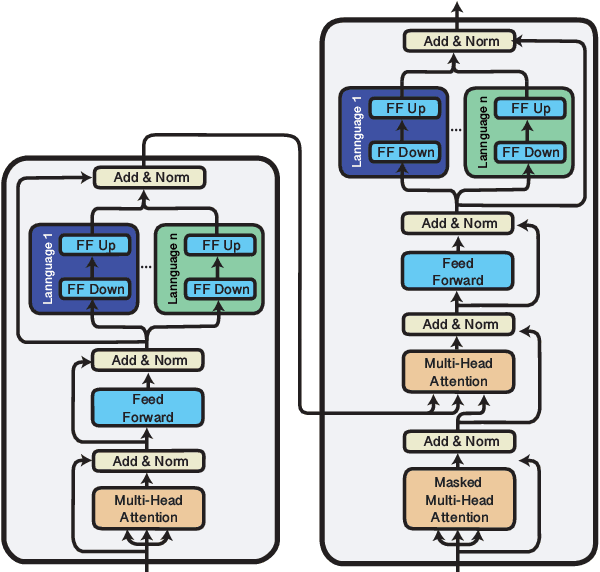



Multilingual sequence-to-sequence models perform poorly with increased language coverage and fail to consistently generate text in the correct target language in few-shot settings. To address these challenges, we propose mmT5, a modular multilingual sequence-to-sequence model. mmT5 utilizes language-specific modules during pre-training, which disentangle language-specific information from language-agnostic information. We identify representation drift during fine-tuning as a key limitation of modular generative models and develop strategies that enable effective zero-shot transfer. Our model outperforms mT5 at the same parameter sizes by a large margin on representative natural language understanding and generation tasks in 40+ languages. Compared to mT5, mmT5 raises the rate of generating text in the correct language under zero-shot settings from 7% to 99%, thereby greatly alleviating the source language hallucination problem.
DePlot: One-shot visual language reasoning by plot-to-table translation
Dec 20, 2022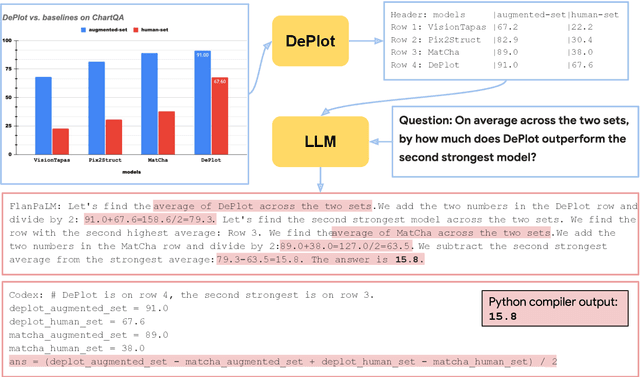
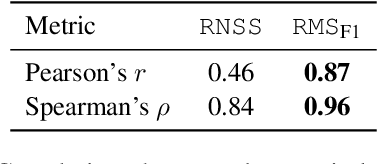
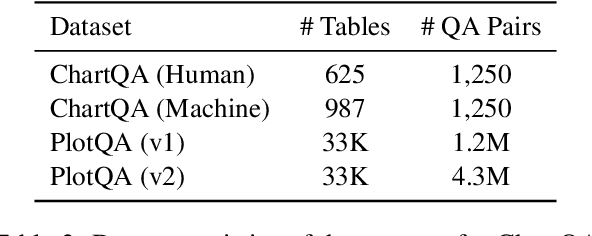
Visual language such as charts and plots is ubiquitous in the human world. Comprehending plots and charts requires strong reasoning skills. Prior state-of-the-art (SOTA) models require at least tens of thousands of training examples and their reasoning capabilities are still much limited, especially on complex human-written queries. This paper presents the first one-shot solution to visual language reasoning. We decompose the challenge of visual language reasoning into two steps: (1) plot-to-text translation, and (2) reasoning over the translated text. The key in this method is a modality conversion module, named as DePlot, which translates the image of a plot or chart to a linearized table. The output of DePlot can then be directly used to prompt a pretrained large language model (LLM), exploiting the few-shot reasoning capabilities of LLMs. To obtain DePlot, we standardize the plot-to-table task by establishing unified task formats and metrics, and train DePlot end-to-end on this task. DePlot can then be used off-the-shelf together with LLMs in a plug-and-play fashion. Compared with a SOTA model finetuned on more than >28k data points, DePlot+LLM with just one-shot prompting achieves a 24.0% improvement over finetuned SOTA on human-written queries from the task of chart QA.
MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering
Dec 19, 2022



Visual language data such as plots, charts, and infographics are ubiquitous in the human world. However, state-of-the-art vision-language models do not perform well on these data. We propose MatCha (Math reasoning and Chart derendering pretraining) to enhance visual language models' capabilities in jointly modeling charts/plots and language data. Specifically, we propose several pretraining tasks that cover plot deconstruction and numerical reasoning which are the key capabilities in visual language modeling. We perform the MatCha pretraining starting from Pix2Struct, a recently proposed image-to-text visual language model. On standard benchmarks such as PlotQA and ChartQA, the MatCha model outperforms state-of-the-art methods by as much as nearly 20%. We also examine how well MatCha pretraining transfers to domains such as screenshots, textbook diagrams, and document figures and observe overall improvement, verifying the usefulness of MatCha pretraining on broader visual language tasks.
Evaluating Byte and Wordpiece Level Models for Massively Multilingual Semantic Parsing
Dec 14, 2022



Token free approaches have been successfully applied to a series of word and span level tasks. In this work, we compare a byte-level (ByT5) and a wordpiece based (mT5) sequence to sequence model on the 51 languages of the MASSIVE multilingual semantic parsing dataset. We examine multiple experimental settings: (i) zero-shot, (ii) full gold data and (iii) zero-shot with synthetic data. By leveraging a state-of-the-art label projection method for machine translated examples, we are able to reduce the gap in exact match accuracy to only 5 points with respect to a model trained on gold data from all the languages. We additionally provide insights on the cross-lingual transfer of ByT5 and show how the model compares with respect to mT5 across all parameter sizes.
Table-To-Text generation and pre-training with TabT5
Oct 17, 2022
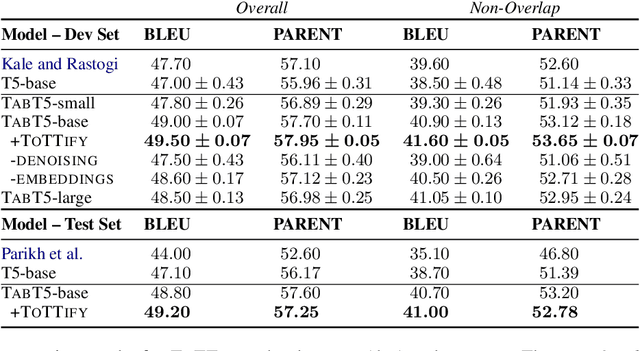
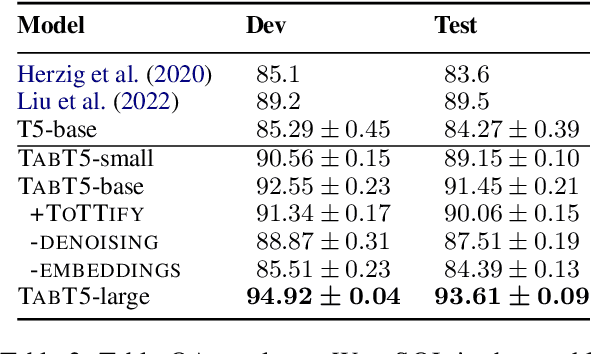
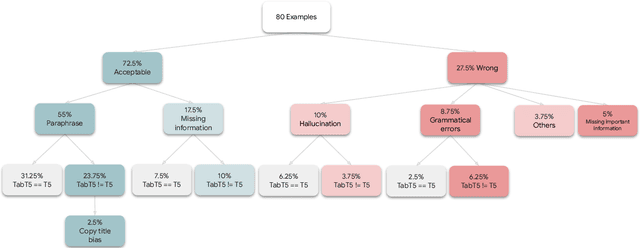
Encoder-only transformer models have been successfully applied to different table understanding tasks, as in TAPAS (Herzig et al., 2020). A major limitation of these architectures is that they are constrained to classification-like tasks such as cell selection or entailment detection. We present TABT5, an encoder-decoder model that generates natural language text based on tables and textual inputs. TABT5 overcomes the encoder-only limitation by incorporating a decoder component and leverages the input structure with table specific embeddings and pre-training. TABT5 achieves new state-of-the-art results on several domains, including spreadsheet formula prediction with a 15% increase in sequence accuracy, QA with a 2.5% increase in sequence accuracy and data-to-text generation with a 2.5% increase in BLEU.
What Did You Say? Task-Oriented Dialog Datasets Are Not Conversational!?
Mar 07, 2022
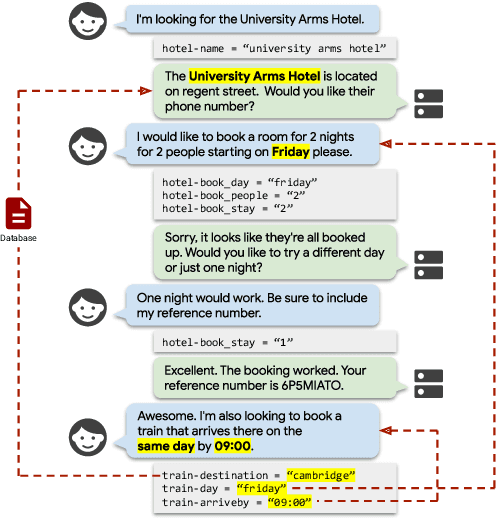
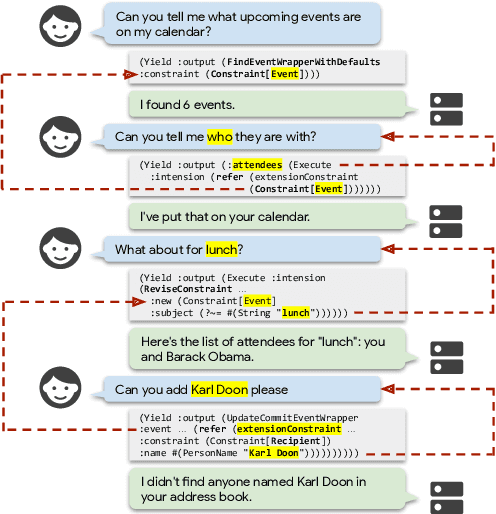

High-quality datasets for task-oriented dialog are crucial for the development of virtual assistants. Yet three of the most relevant large scale dialog datasets suffer from one common flaw: the dialog state update can be tracked, to a great extent, by a model that only considers the current user utterance, ignoring the dialog history. In this work, we outline a taxonomy of conversational and contextual effects, which we use to examine MultiWOZ, SGD and SMCalFlow, among the most recent and widely used task-oriented dialog datasets. We analyze the datasets in a model-independent fashion and corroborate these findings experimentally using a strong text-to-text baseline (T5). We find that less than 4% of MultiWOZ's turns and 10% of SGD's turns are conversational, while SMCalFlow is not conversational at all in its current release: its dialog state tracking task can be reduced to single exchange semantic parsing. We conclude by outlining desiderata for truly conversational dialog datasets.
Structured Context and High-Coverage Grammar for Conversational Question Answering over Knowledge Graphs
Sep 01, 2021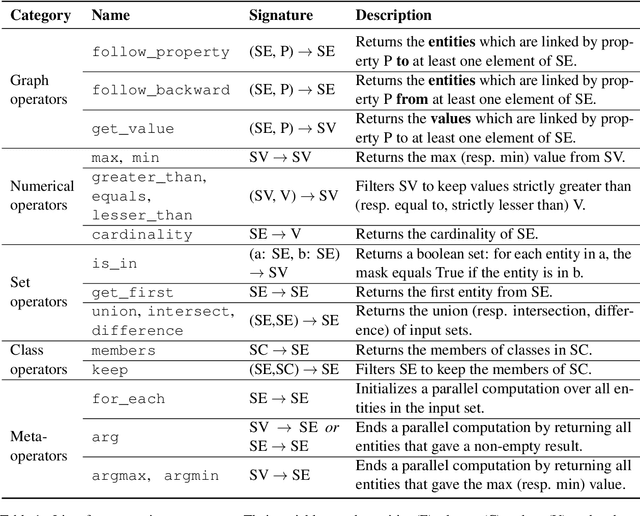
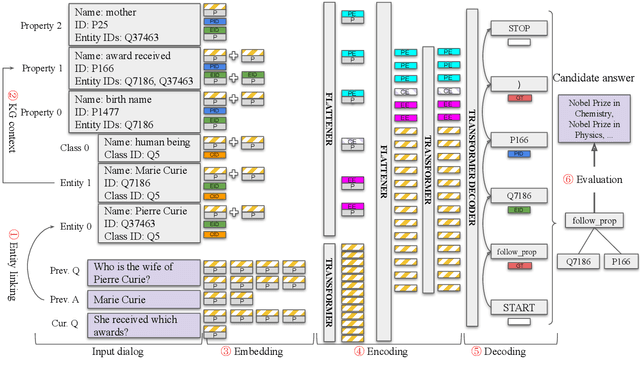
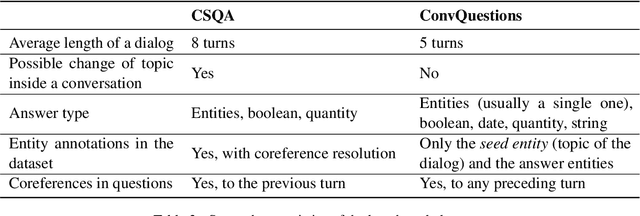
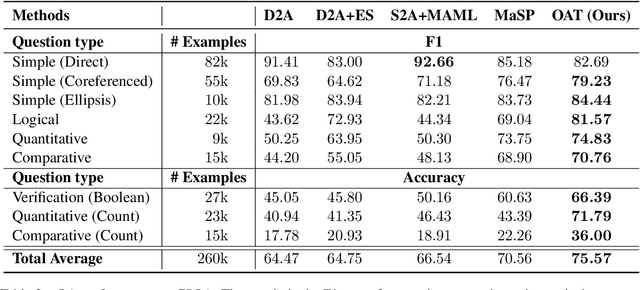
We tackle the problem of weakly-supervised conversational Question Answering over large Knowledge Graphs using a neural semantic parsing approach. We introduce a new Logical Form (LF) grammar that can model a wide range of queries on the graph while remaining sufficiently simple to generate supervision data efficiently. Our Transformer-based model takes a JSON-like structure as input, allowing us to easily incorporate both Knowledge Graph and conversational contexts. This structured input is transformed to lists of embeddings and then fed to standard attention layers. We validate our approach, both in terms of grammar coverage and LF execution accuracy, on two publicly available datasets, CSQA and ConvQuestions, both grounded in Wikidata. On CSQA, our approach increases the coverage from $80\%$ to $96.2\%$, and the LF execution accuracy from $70.6\%$ to $75.6\%$, with respect to previous state-of-the-art results. On ConvQuestions, we achieve competitive results with respect to the state-of-the-art.