 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Did You Say? Task-Oriented Dialog Datasets Are Not Conversational!?
Paper and Code

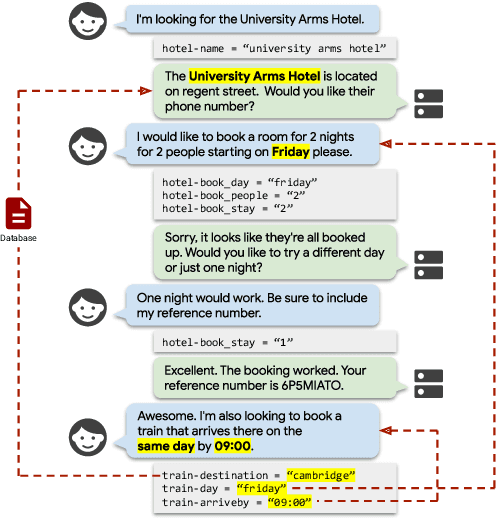
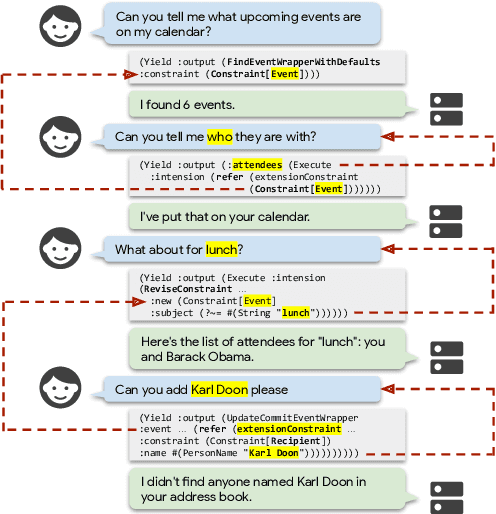

High-quality datasets for task-oriented dialog are crucial for the development of virtual assistants. Yet three of the most relevant large scale dialog datasets suffer from one common flaw: the dialog state update can be tracked, to a great extent, by a model that only considers the current user utterance, ignoring the dialog history. In this work, we outline a taxonomy of conversational and contextual effects, which we use to examine MultiWOZ, SGD and SMCalFlow, among the most recent and widely used task-oriented dialog datasets. We analyze the datasets in a model-independent fashion and corroborate these findings experimentally using a strong text-to-text baseline (T5). We find that less than 4% of MultiWOZ's turns and 10% of SGD's turns are conversational, while SMCalFlow is not conversational at all in its current release: its dialog state tracking task can be reduced to single exchange semantic parsing. We conclude by outlining desiderata for truly conversational dialog datasets.