 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge Flow: A Tractable and Predictive Continuous-Time Model for Gradient Descent at the Edge of Stability
Jun 16, 2026Gradient descent in deep learning may operate at the edge of stability (EoS), a regime in which the largest eigenvalue of the loss Hessian hovers near the stability threshold $2/η$, where $η$ is the learning rate. Classical analysis tools such as gradient flow and the descent lemma do not apply here, motivating the search for a continuous-time model valid at EoS. We propose Edge Flow, a system of three coupled ordinary differential equations that provides a tractable, faithful, and predictive model of gradient descent dynamics at EoS. Edge Flow decomposes the dynamics into a center, an oscillation direction, and an oscillation magnitude. The center follows a modified gradient flow on a symmetrized loss; the direction tracks a top eigenvector of the Hessian via Rayleigh quotient dynamics; and the magnitude grows or decays exponentially depending on whether the sharpness exceeds or falls below the threshold $2/η$. Crucially, sharpness stabilization emerges from the coupled dynamics via a self-stabilization feedback loop. Discretizing Edge Flow only requires two gradient evaluations and one Hessian--vector product at each iteration. We demonstrate empirically that Edge Flow tracks the dynamics of gradient descent at least as faithfully as previously proposed continuous-time EoS models, while in addition resolving the oscillation of the sharpness at the onset of EoS, and that it provides a principled framework for understanding and mitigating instabilities in this regime.
Distilling LLM Feedback for Lean Theorem Proving
May 29, 2026Post-training for reasoning models typically combines supervised fine-tuning with reinforcement learning from verifiable rewards, most commonly with GRPO. However, this algorithm suffers from sparse rewards, limited exploration, and mode collapse. Building upon recent works on self-distillation, we propose Feedback Distillation, a training method where the model is trained to match, at the token level, its own distribution conditioned on privileged feedback produced by a language model. Feedback Distillation offers token-level supervision and can inject external knowledge. Evaluating our method for Lean4 theorem-proving, we find that Feedback Distillation maintains greater diversity in generated trajectories than GRPO, yielding higher policy entropy and better pass@k scaling. The two methods are complementary: initializing GRPO from a Feedback Distillation checkpoint outperforms either method alone. All in all, our results suggest a promising avenue to improve post-training for complex reasoning.
Understanding diffusion models requires rethinking (again) generalization
May 07, 2026This position paper argues that understanding generalization in diffusion models requires fundamentally new theoretical frameworks that go beyond both classical statistical learning theory and the benign overfitting paradigm developed for supervised learning. In diffusion models, unlike in supervised learning, memorization of training data and generalization to novel samples are incompatible: a model that has fully memorized its training set generates copies rather than novel data. Several theoretical explanations for why practical diffusion models nevertheless generalize have been proposed, based on capacity limitations, implicit regularization from optimization, or architectural inductive biases, but their interactions remain unclear. We argue that the field should pivot from explaining why the diffusion models do not memorize to investigating what the model actually learns during pre-memorization phase. To highlight our stance, we conduct empirical study of diffusion models trained on CIFAR-10, and we distill the findings into concrete open questions that we believe are key to improve understanding of generalization in diffusion models.
Exponential Convergence of (Stochastic) Gradient Descent for Separable Logistic Regression
Feb 21, 2026Gradient descent and stochastic gradient descent are central to modern machine learning, yet their behavior under large step sizes remains theoretically unclear. Recent work suggests that acceleration often arises near the edge of stability, where optimization trajectories become unstable and difficult to analyze. Existing results for separable logistic regression achieve faster convergence by explicitly leveraging such unstable regimes through constant or adaptive large step sizes. In this paper, we show that instability is not inherent to acceleration. We prove that gradient descent with a simple, non-adaptive increasing step-size schedule achieves exponential convergence for separable logistic regression under a margin condition, while remaining entirely within a stable optimization regime. The resulting method is anytime and does not require prior knowledge of the optimization horizon or target accuracy. We also establish exponential convergence of stochastic gradient descent using a lightweight adaptive step-size rule that avoids line search and specialized procedures, improving upon existing polynomial-rate guarantees. Together, our results demonstrate that carefully structured step-size growth alone suffices to obtain exponential acceleration for both gradient descent and stochastic gradient descent.
Clustering in Deep Stochastic Transformers
Jan 29, 2026Transformers have revolutionized deep learning across various domains but understanding the precise token dynamics remains a theoretical challenge. Existing theories of deep Transformers with layer normalization typically predict that tokens cluster to a single point; however, these results rely on deterministic weight assumptions, which fail to capture the standard initialization scheme in Transformers. In this work, we show that accounting for the intrinsic stochasticity of random initialization alters this picture. More precisely, we analyze deep Transformers where noise arises from the random initialization of value matrices. Under diffusion scaling and token-wise RMS normalization, we prove that, as the number of Transformer layers goes to infinity, the discrete token dynamics converge to an interacting-particle system on the sphere where tokens are driven by a \emph{common} matrix-valued Brownian noise. In this limit, we show that initialization noise prevents the collapse to a single cluster predicted by deterministic models. For two tokens, we prove a phase transition governed by the interaction strength and the token dimension: unlike deterministic attention flows, antipodal configurations become attracting with positive probability. Numerical experiments confirm the predicted transition, reveal that antipodal formations persist for more than two tokens, and demonstrate that suppressing the intrinsic noise degrades accuracy.
Attention-based clustering
May 19, 2025Transformers have emerged as a powerful neural network architecture capable of tackling a wide range of learning tasks. In this work, we provide a theoretical analysis of their ability to automatically extract structure from data in an unsupervised setting. In particular, we demonstrate their suitability for clustering when the input data is generated from a Gaussian mixture model. To this end, we study a simplified two-head attention layer and define a population risk whose minimization with unlabeled data drives the head parameters to align with the true mixture centroids.
Taking a Big Step: Large Learning Rates in Denoising Score Matching Prevent Memorization
Feb 05, 2025



Denoising score matching plays a pivotal role in the performance of diffusion-based generative models. However, the empirical optimal score--the exact solution to the denoising score matching--leads to memorization, where generated samples replicate the training data. Yet, in practice, only a moderate degree of memorization is observed, even without explicit regularization. In this paper, we investigate this phenomenon by uncovering an implicit regularization mechanism driven by large learning rates. Specifically, we show that in the small-noise regime, the empirical optimal score exhibits high irregularity. We then prove that, when trained by stochastic gradient descent with a large enough learning rate, neural networks cannot stably converge to a local minimum with arbitrarily small excess risk. Consequently, the learned score cannot be arbitrarily close to the empirical optimal score, thereby mitigating memorization. To make the analysis tractable, we consider one-dimensional data and two-layer neural networks. Experiments validate the crucial role of the learning rate in preventing memorization, even beyond the one-dimensional setting.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Attention layers provably solve single-location regression
Oct 02, 2024
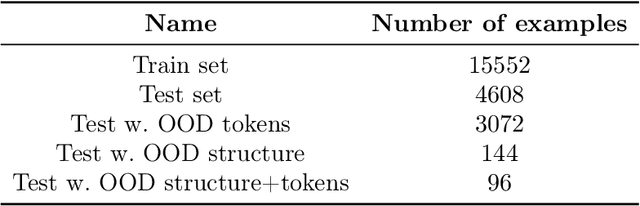

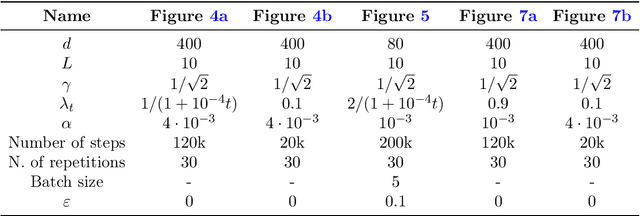
Attention-based models, such as Transformer, excel across various tasks but lack a comprehensive theoretical understanding, especially regarding token-wise sparsity and internal linear representations. To address this gap, we introduce the single-location regression task, where only one token in a sequence determines the output, and its position is a latent random variable, retrievable via a linear projection of the input. To solve this task, we propose a dedicated predictor, which turns out to be a simplified version of a non-linear self-attention layer. We study its theoretical properties, by showing its asymptotic Bayes optimality and analyzing its training dynamics. In particular, despite the non-convex nature of the problem, the predictor effectively learns the underlying structure. This work highlights the capacity of attention mechanisms to handle sparse token information and internal linear structures.
Deep linear networks for regression are implicitly regularized towards flat minima
May 22, 2024The largest eigenvalue of the Hessian, or sharpness, of neural networks is a key quantity to understand their optimization dynamics. In this paper, we study the sharpness of deep linear networks for overdetermined univariate regression. Minimizers can have arbitrarily large sharpness, but not an arbitrarily small one. Indeed, we show a lower bound on the sharpness of minimizers, which grows linearly with depth. We then study the properties of the minimizer found by gradient flow, which is the limit of gradient descent with vanishing learning rate. We show an implicit regularization towards flat minima: the sharpness of the minimizer is no more than a constant times the lower bound. The constant depends on the condition number of the data covariance matrix, but not on width or depth. This result is proven both for a small-scale initialization and a residual initialization. Results of independent interest are shown in both cases. For small-scale initialization, we show that the learned weight matrices are approximately rank-one and that their singular vectors align. For residual initialization, convergence of the gradient flow for a Gaussian initialization of the residual network is proven. Numerical experiments illustrate our results and connect them to gradient descent with non-vanishing learning rate.