 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unifying View of Variational Generative Wasserstein Flows
May 29, 2026Many modern generative models can be viewed as minimizing divergences between probability distributions, yet they rely on different algorithmic and geometric principles. Wasserstein gradient flows provide a continuous-time formulation for optimizing over distributions, and can be approximated through their implicit discretization via the Jordan-Kinderlehrer-Otto (JKO) scheme. In this work, we present a unified theoretical framework for generative modeling based on Wasserstein gradient flows, which we refer to as Generative Wasserstein Flows (GWF). We show that a broad class of existing methods can be derived as instances of parametric JKO schemes for $f$-divergence objectives, and we establish equivalences between several recently proposed algorithms. We extend this framework beyond f-divergence to Integral Probability Metrics and squared Maximum Mean Discrepancy, deriving new JKO-based generative algorithms, and clarifying their connections with GANs. We study empirically the impact of the JKO regularization for a wide set of objectives. Finally, we analyze parametric Wasserstein flows, where the dynamics are restricted to distributions induced by parametrized maps.
Evaluating the Relevance of Uncertainty Estimators for LLM Hallucination
May 26, 2026Large language models (LLMs) are prone to hallucinations, i.e., statements unsupported by the input or training data, hindering reliable deployment. In parallel, numerous uncertainty estimation (UE) methods have been proposed to quantify model confidence and are often implicitly treated as proxies for model failure. However, the relationship between uncertainty and hallucinations remains insufficiently characterized. We present a systematic empirical study of the association between uncertainty estimators and hallucinations in LLMs. Rather than assuming this association, we evaluate directly when and to what extent it holds. We consider a diverse set of uncertainty estimators, including information-theoretic, sampling-based, and reflexive estimators, and examine their behavior across hallucination settings. Our experiments cover both intrinsic hallucinations (violations of input faithfulness) and extrinsic hallucinations (unsupported claims relative to training data), using four complementary benchmarks, including RAGTruth and HalluLens. We find that the association is highly variable and often weak, depending on the hallucination type and the LLM under evaluation. These results challenge the use of uncertainty as a direct signal of hallucination and clarify when it provides actionable information.
Generalized Discrete Diffusion from Snapshots
Mar 22, 2026We introduce Generalized Discrete Diffusion from Snapshots (GDDS), a unified framework for discrete diffusion modeling that supports arbitrary noising processes over large discrete state spaces. Our formulation encompasses all existing discrete diffusion approaches, while allowing significantly greater flexibility in the choice of corruption dynamics. The forward noising process relies on uniformization and enables fast arbitrary corruption. For the reverse process, we derive a simple evidence lower bound (ELBO) based on snapshot latents, instead of the entire noising path, that allows efficient training of standard generative modeling architectures with clear probabilistic interpretation. Our experiments on large-vocabulary discrete generation tasks suggest that the proposed framework outperforms existing discrete diffusion methods in terms of training efficiency and generation quality, and beats autoregressive models for the first time at this scale. We provide the code along with a blog post on the project page : \href{https://oussamazekri.fr/gdds}{https://oussamazekri.fr/gdds}.
Kernel Trace Distance: Quantum Statistical Metric between Measures through RKHS Density Operators
Jul 08, 2025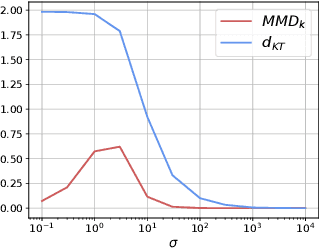

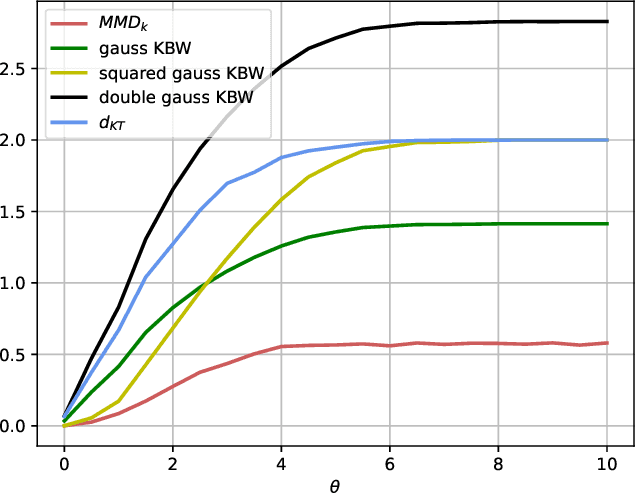
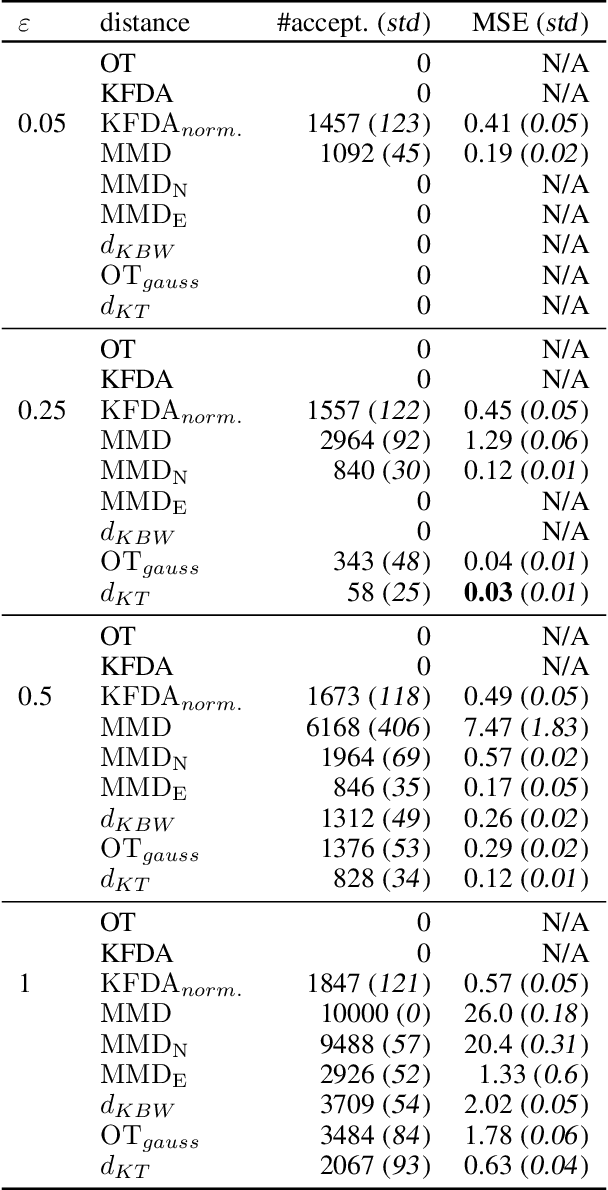
Distances between probability distributions are a key component of many statistical machine learning tasks, from two-sample testing to generative modeling, among others. We introduce a novel distance between measures that compares them through a Schatten norm of their kernel covariance operators. We show that this new distance is an integral probability metric that can be framed between a Maximum Mean Discrepancy (MMD) and a Wasserstein distance. In particular, we show that it avoids some pitfalls of MMD, by being more discriminative and robust to the choice of hyperparameters. Moreover, it benefits from some compelling properties of kernel methods, that can avoid the curse of dimensionality for their sample complexity. We provide an algorithm to compute the distance in practice by introducing an extension of kernel matrix for difference of distributions that could be of independent interest. Those advantages are illustrated by robust approximate Bayesian computation under contamination as well as particle flow simulations.
Variational Inference with Mixtures of Isotropic Gaussians
Jun 16, 2025Variational inference (VI) is a popular approach in Bayesian inference, that looks for the best approximation of the posterior distribution within a parametric family, minimizing a loss that is typically the (reverse) Kullback-Leibler (KL) divergence. In this paper, we focus on the following parametric family: mixtures of isotropic Gaussians (i.e., with diagonal covariance matrices proportional to the identity) and uniform weights. We develop a variational framework and provide efficient algorithms suited for this family. In contrast with mixtures of Gaussian with generic covariance matrices, this choice presents a balance between accurate approximations of multimodal Bayesian posteriors, while being memory and computationally efficient. Our algorithms implement gradient descent on the location of the mixture components (the modes of the Gaussians), and either (an entropic) Mirror or Bures descent on their variance parameters. We illustrate the performance of our algorithms on numerical experiments.
Flowing Datasets with Wasserstein over Wasserstein Gradient Flows
Jun 09, 2025Many applications in machine learning involve data represented as probability distributions. The emergence of such data requires radically novel techniques to design tractable gradient flows on probability distributions over this type of (infinite-dimensional) objects. For instance, being able to flow labeled datasets is a core task for applications ranging from domain adaptation to transfer learning or dataset distillation. In this setting, we propose to represent each class by the associated conditional distribution of features, and to model the dataset as a mixture distribution supported on these classes (which are themselves probability distributions), meaning that labeled datasets can be seen as probability distributions over probability distributions. We endow this space with a metric structure from optimal transport, namely the Wasserstein over Wasserstein (WoW) distance, derive a differential structure on this space, and define WoW gradient flows. The latter enables to design dynamics over this space that decrease a given objective functional. We apply our framework to transfer learning and dataset distillation tasks, leveraging our gradient flow construction as well as novel tractable functionals that take the form of Maximum Mean Discrepancies with Sliced-Wasserstein based kernels between probability distributions.
DDEQs: Distributional Deep Equilibrium Models through Wasserstein Gradient Flows
Mar 03, 2025Deep Equilibrium Models (DEQs) are a class of implicit neural networks that solve for a fixed point of a neural network in their forward pass. Traditionally, DEQs take sequences as inputs, but have since been applied to a variety of data. In this work, we present Distributional Deep Equilibrium Models (DDEQs), extending DEQs to discrete measure inputs, such as sets or point clouds. We provide a theoretically grounded framework for DDEQs. Leveraging Wasserstein gradient flows, we show how the forward pass of the DEQ can be adapted to find fixed points of discrete measures under permutation-invariance, and derive adequate network architectures for DDEQs. In experiments, we show that they can compete with state-of-the-art models in tasks such as point cloud classification and point cloud completion, while being significantly more parameter-efficient.
Properties of Wasserstein Gradient Flows for the Sliced-Wasserstein Distance
Feb 10, 2025In this paper, we investigate the properties of the Sliced Wasserstein Distance (SW) when employed as an objective functional. The SW metric has gained significant interest in the optimal transport and machine learning literature, due to its ability to capture intricate geometric properties of probability distributions while remaining computationally tractable, making it a valuable tool for various applications, including generative modeling and domain adaptation. Our study aims to provide a rigorous analysis of the critical points arising from the optimization of the SW objective. By computing explicit perturbations, we establish that stable critical points of SW cannot concentrate on segments. This stability analysis is crucial for understanding the behaviour of optimization algorithms for models trained using the SW objective. Furthermore, we investigate the properties of the SW objective, shedding light on the existence and convergence behavior of critical points. We illustrate our theoretical results through numerical experiments.
Density Ratio Estimation with Conditional Probability Paths
Feb 04, 2025Density ratio estimation in high dimensions can be reframed as integrating a certain quantity, the time score, over probability paths which interpolate between the two densities. In practice, the time score has to be estimated based on samples from the two densities. However, existing methods for this problem remain computationally expensive and can yield inaccurate estimates. Inspired by recent advances in generative modeling, we introduce a novel framework for time score estimation, based on a conditioning variable. Choosing the conditioning variable judiciously enables a closed-form objective function. We demonstrate that, compared to previous approaches, our approach results in faster learning of the time score and competitive or better estimation accuracies of the density ratio on challenging tasks. Furthermore, we establish theoretical guarantees on the error of the estimated density ratio.
Polynomial time sampling from log-smooth distributions in fixed dimension under semi-log-concavity of the forward diffusion with application to strongly dissipative distributions
Dec 31, 2024In this article we provide a stochastic sampling algorithm with polynomial complexity in fixed dimension that leverages the recent advances on diffusion models where it is shown that under mild conditions, sampling can be achieved via an accurate estimation of intermediate scores across the marginals $(p_t)_{t\ge 0}$ of the standard Ornstein-Uhlenbeck process started at the density we wish to sample from. The heart of our method consists into approaching these scores via a computationally cheap estimator and relating the variance of this estimator to the smoothness properties of the forward process. Under the assumption that the density to sample from is $L$-log-smooth and that the forward process is semi-log-concave: $-\nabla^2 \log(p_t) \succeq -\beta I_d$ for some $\beta \geq 0$, we prove that our algorithm achieves an expected $\epsilon$ error in $\text{KL}$ divergence in $O(d^7L^{d+2}\epsilon^{-2(d+3)} (L+\beta)^2d^{2(d+1)})$ time. In particular, our result allows to fully transfer the problem of sampling from a log-smooth distribution into a regularity estimate problem. As an application, we derive an exponential complexity improvement for the problem of sampling from a $L$-log-smooth distribution that is $\alpha$-strongly log-concave distribution outside some ball of radius $R$: after proving that such distributions verify the semi-log-concavity assumption, a result which might be of independent interest, we recover a $poly(R,L,\alpha^{-1}, \epsilon^{-1})$ complexity in fixed dimension which exponentially improves upon the previously known $poly(e^{RL^2}, L,\alpha^{-1}, \log(\epsilon^{-1}))$ complexity in the low precision regime.