 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Energy-Based Models from Stochastic Interpolants using Spatiotemporal Differences
May 26, 2026Learning an energy-based model from data samples is a central problem in machine learning. Many recent and popular methods, such as denoising score matching for training energy-based diffusion models, use stochastic interpolants to corrupt data samples at different noise levels indexed by a time variable. This defines a joint density over both the data space and time, and most methods learn its energy through either spatial or temporal differences. We identify distinct failure modes for both of these approaches. To solve them, we propose Spatiotemporal Noise-Contrastive Estimation (stNCE), a framework for learning the energy through joint spatiotemporal differences. stNCE unifies many existing methods and leads to new training objectives. Experiments on images and molecules demonstrate performance competitive with state-of-the-art density estimation methods.
Identifiable Multi-View Causal Discovery Without Non-Gaussianity
Feb 28, 2025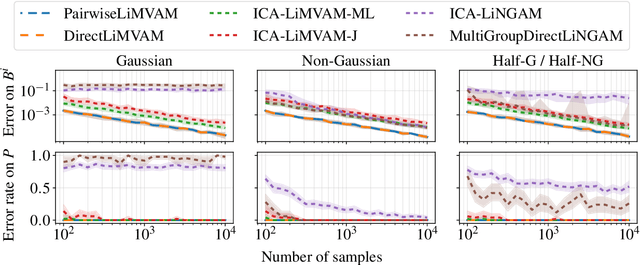
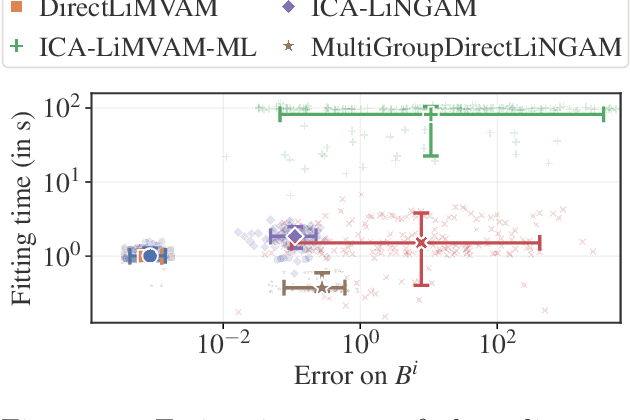
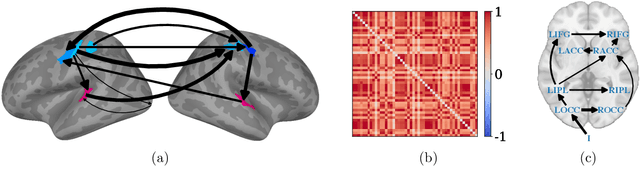
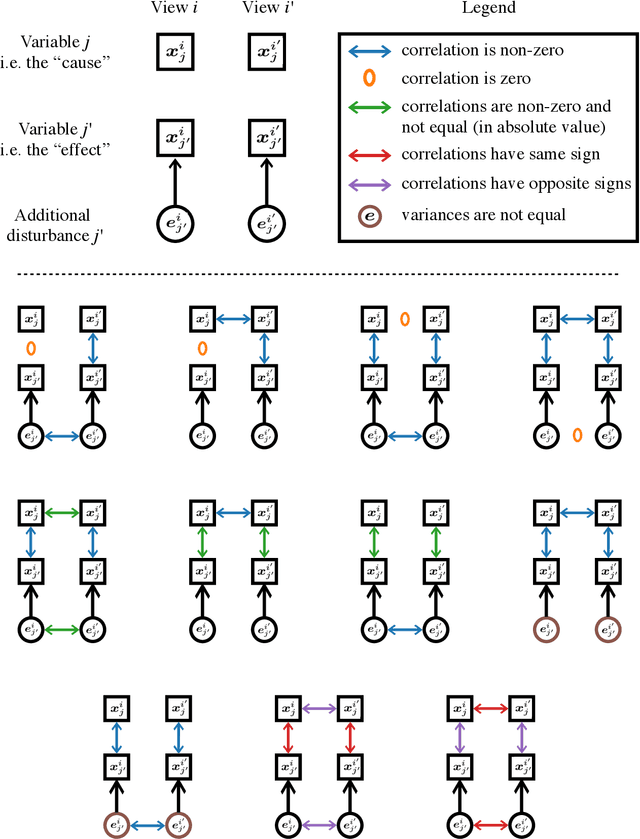
We propose a novel approach to linear causal discovery in the framework of multi-view Structural Equation Models (SEM). Our proposed model relaxes the well-known assumption of non-Gaussian disturbances by alternatively assuming diversity of variances over views, making it more broadly applicable. We prove the identifiability of all the parameters of the model without any further assumptions on the structure of the SEM other than it being acyclic. We further propose an estimation algorithm based on recent advances in multi-view Independent Component Analysis (ICA). The proposed methodology is validated through simulations and application on real neuroimaging data, where it enables the estimation of causal graphs between brain regions.
Density Ratio Estimation with Conditional Probability Paths
Feb 04, 2025Density ratio estimation in high dimensions can be reframed as integrating a certain quantity, the time score, over probability paths which interpolate between the two densities. In practice, the time score has to be estimated based on samples from the two densities. However, existing methods for this problem remain computationally expensive and can yield inaccurate estimates. Inspired by recent advances in generative modeling, we introduce a novel framework for time score estimation, based on a conditioning variable. Choosing the conditioning variable judiciously enables a closed-form objective function. We demonstrate that, compared to previous approaches, our approach results in faster learning of the time score and competitive or better estimation accuracies of the density ratio on challenging tasks. Furthermore, we establish theoretical guarantees on the error of the estimated density ratio.
MVICAD2: Multi-View Independent Component Analysis with Delays and Dilations
Jan 13, 2025



Machine learning techniques in multi-view settings face significant challenges, particularly when integrating heterogeneous data, aligning feature spaces, and managing view-specific biases. These issues are prominent in neuroscience, where data from multiple subjects exposed to the same stimuli are analyzed to uncover brain activity dynamics. In magnetoencephalography (MEG), where signals are captured at the scalp level, estimating the brain's underlying sources is crucial, especially in group studies where sources are assumed to be similar for all subjects. Common methods, such as Multi-View Independent Component Analysis (MVICA), assume identical sources across subjects, but this assumption is often too restrictive due to individual variability and age-related changes. Multi-View Independent Component Analysis with Delays (MVICAD) addresses this by allowing sources to differ up to a temporal delay. However, temporal dilation effects, particularly in auditory stimuli, are common in brain dynamics, making the estimation of time delays alone insufficient. To address this, we propose Multi-View Independent Component Analysis with Delays and Dilations (MVICAD2), which allows sources to differ across subjects in both temporal delays and dilations. We present a model with identifiable sources, derive an approximation of its likelihood in closed form, and use regularization and optimization techniques to enhance performance. Through simulations, we demonstrate that MVICAD2 outperforms existing multi-view ICA methods. We further validate its effectiveness using the Cam-CAN dataset, and showing how delays and dilations are related to aging.
Polynomial time sampling from log-smooth distributions in fixed dimension under semi-log-concavity of the forward diffusion with application to strongly dissipative distributions
Dec 31, 2024In this article we provide a stochastic sampling algorithm with polynomial complexity in fixed dimension that leverages the recent advances on diffusion models where it is shown that under mild conditions, sampling can be achieved via an accurate estimation of intermediate scores across the marginals $(p_t)_{t\ge 0}$ of the standard Ornstein-Uhlenbeck process started at the density we wish to sample from. The heart of our method consists into approaching these scores via a computationally cheap estimator and relating the variance of this estimator to the smoothness properties of the forward process. Under the assumption that the density to sample from is $L$-log-smooth and that the forward process is semi-log-concave: $-\nabla^2 \log(p_t) \succeq -\beta I_d$ for some $\beta \geq 0$, we prove that our algorithm achieves an expected $\epsilon$ error in $\text{KL}$ divergence in $O(d^7L^{d+2}\epsilon^{-2(d+3)} (L+\beta)^2d^{2(d+1)})$ time. In particular, our result allows to fully transfer the problem of sampling from a log-smooth distribution into a regularity estimate problem. As an application, we derive an exponential complexity improvement for the problem of sampling from a $L$-log-smooth distribution that is $\alpha$-strongly log-concave distribution outside some ball of radius $R$: after proving that such distributions verify the semi-log-concavity assumption, a result which might be of independent interest, we recover a $poly(R,L,\alpha^{-1}, \epsilon^{-1})$ complexity in fixed dimension which exponentially improves upon the previously known $poly(e^{RL^2}, L,\alpha^{-1}, \log(\epsilon^{-1}))$ complexity in the low precision regime.
Provable Convergence and Limitations of Geometric Tempering for Langevin Dynamics
Oct 13, 2024Geometric tempering is a popular approach to sampling from challenging multi-modal probability distributions by instead sampling from a sequence of distributions which interpolate, using the geometric mean, between an easier proposal distribution and the target distribution. In this paper, we theoretically investigate the soundness of this approach when the sampling algorithm is Langevin dynamics, proving both upper and lower bounds. Our upper bounds are the first analysis in the literature under functional inequalities. They assert the convergence of tempered Langevin in continuous and discrete-time, and their minimization leads to closed-form optimal tempering schedules for some pairs of proposal and target distributions. Our lower bounds demonstrate a simple case where the geometric tempering takes exponential time, and further reveal that the geometric tempering can suffer from poor functional inequalities and slow convergence, even when the target distribution is well-conditioned. Overall, our results indicate that geometric tempering may not help, and can even be harmful for convergence.
A Practical Diffusion Path for Sampling
Jun 20, 2024Diffusion models are state-of-the-art methods in generative modeling when samples from a target probability distribution are available, and can be efficiently sampled, using score matching to estimate score vectors guiding a Langevin process. However, in the setting where samples from the target are not available, e.g. when this target's density is known up to a normalization constant, the score estimation task is challenging. Previous approaches rely on Monte Carlo estimators that are either computationally heavy to implement or sample-inefficient. In this work, we propose a computationally attractive alternative, relying on the so-called dilation path, that yields score vectors that are available in closed-form. This path interpolates between a Dirac and the target distribution using a convolution. We propose a simple implementation of Langevin dynamics guided by the dilation path, using adaptive step-sizes. We illustrate the results of our sampling method on a range of tasks, and shows it performs better than classical alternatives.
Provable benefits of annealing for estimating normalizing constants: Importance Sampling, Noise-Contrastive Estimation, and beyond
Oct 09, 2023



Recent research has developed several Monte Carlo methods for estimating the normalization constant (partition function) based on the idea of annealing. This means sampling successively from a path of distributions that interpolate between a tractable "proposal" distribution and the unnormalized "target" distribution. Prominent estimators in this family include annealed importance sampling and annealed noise-contrastive estimation (NCE). Such methods hinge on a number of design choices: which estimator to use, which path of distributions to use and whether to use a path at all; so far, there is no definitive theory on which choices are efficient. Here, we evaluate each design choice by the asymptotic estimation error it produces. First, we show that using NCE is more efficient than the importance sampling estimator, but in the limit of infinitesimal path steps, the difference vanishes. Second, we find that using the geometric path brings down the estimation error from an exponential to a polynomial function of the parameter distance between the target and proposal distributions. Third, we find that the arithmetic path, while rarely used, can offer optimality properties over the universally-used geometric path. In fact, in a particular limit, the optimal path is arithmetic. Based on this theory, we finally propose a two-step estimator to approximate the optimal path in an efficient way.
Optimizing the Noise in Self-Supervised Learning: from Importance Sampling to Noise-Contrastive Estimation
Jan 23, 2023Self-supervised learning is an increasingly popular approach to unsupervised learning, achieving state-of-the-art results. A prevalent approach consists in contrasting data points and noise points within a classification task: this requires a good noise distribution which is notoriously hard to specify. While a comprehensive theory is missing, it is widely assumed that the optimal noise distribution should in practice be made equal to the data distribution, as in Generative Adversarial Networks (GANs). We here empirically and theoretically challenge this assumption. We turn to Noise-Contrastive Estimation (NCE) which grounds this self-supervised task as an estimation problem of an energy-based model of the data. This ties the optimality of the noise distribution to the sample efficiency of the estimator, which is rigorously defined as its asymptotic variance, or mean-squared error. In the special case where the normalization constant only is unknown, we show that NCE recovers a family of Importance Sampling estimators for which the optimal noise is indeed equal to the data distribution. However, in the general case where the energy is also unknown, we prove that the optimal noise density is the data density multiplied by a correction term based on the Fisher score. In particular, the optimal noise distribution is different from the data distribution, and is even from a different family. Nevertheless, we soberly conclude that the optimal noise may be hard to sample from, and the gain in efficiency can be modest compared to choosing the noise distribution equal to the data's.
The Optimal Noise in Noise-Contrastive Learning Is Not What You Think
Mar 02, 2022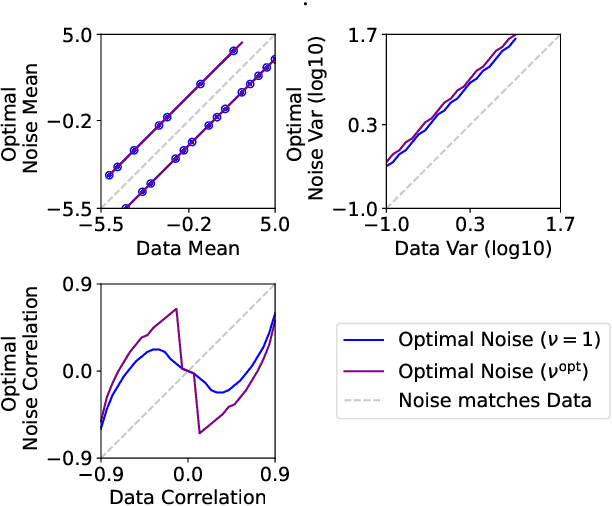
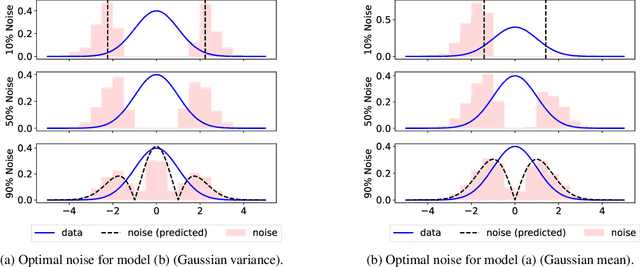

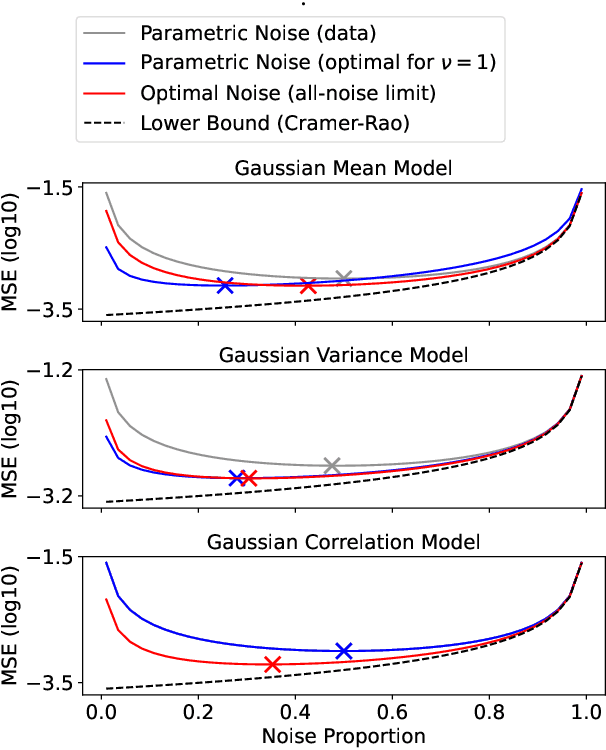
Learning a parametric model of a data distribution is a well-known statistical problem that has seen renewed interest as it is brought to scale in deep learning. Framing the problem as a self-supervised task, where data samples are discriminated from noise samples, is at the core of state-of-the-art methods, beginning with Noise-Contrastive Estimation (NCE). Yet, such contrastive learning requires a good noise distribution, which is hard to specify; domain-specific heuristics are therefore widely used. While a comprehensive theory is missing, it is widely assumed that the optimal noise should in practice be made equal to the data, both in distribution and proportion. This setting underlies Generative Adversarial Networks (GANs) in particular. Here, we empirically and theoretically challenge this assumption on the optimal noise. We show that deviating from this assumption can actually lead to better statistical estimators, in terms of asymptotic variance. In particular, the optimal noise distribution is different from the data's and even from a different family.