 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDANCE: Detect and Classify Events in EEG
May 11, 2026Event identification in continuous neural recordings is a critical task in neuroscience. Decoding in EEG is dominated by classifying windows aligned to known event onsets. However, while available in controlled experiments, such onsets are absent in continuous real-world monitoring. Here, we introduce DANCE, a deep learning pipeline that frames neural decoding as a set-prediction problem and jointly detects and classifies events directly from raw, unaligned signals. Evaluated separately on ten datasets curated from the literature with a wide variety of event types (ranging from milliseconds to minutes in duration), our model outperforms existing methods on a broad range of cognitive, clinical and BCI tasks. This single architecture establishes a new state of the art in the competitive task of seizure monitoring and matches the accuracy of onset-informed models for BCI tasks. Overall, our method marks a step towards end-to-end asynchronous neural decoding models
EEG Foundation Challenge: From Cross-Task to Cross-Subject EEG Decoding
Jun 23, 2025Current electroencephalogram (EEG) decoding models are typically trained on small numbers of subjects performing a single task. Here, we introduce a large-scale, code-submission-based competition comprising two challenges. First, the Transfer Challenge asks participants to build and test a model that can zero-shot decode new tasks and new subjects from their EEG data. Second, the Psychopathology factor prediction Challenge asks participants to infer subject measures of mental health from EEG data. For this, we use an unprecedented, multi-terabyte dataset of high-density EEG signals (128 channels) recorded from over 3,000 child to young adult subjects engaged in multiple active and passive tasks. We provide several tunable neural network baselines for each of these two challenges, including a simple network and demographic-based regression models. Developing models that generalise across tasks and individuals will pave the way for ML network architectures capable of adapting to EEG data collected from diverse tasks and individuals. Similarly, predicting mental health-relevant personality trait values from EEG might identify objective biomarkers useful for clinical diagnosis and design of personalised treatment for psychological conditions. Ultimately, the advances spurred by this challenge could contribute to the development of computational psychiatry and useful neurotechnology, and contribute to breakthroughs in both fundamental neuroscience and applied clinical research.
* Approved at Neurips Competition track. webpage: https://eeg2025.github.io/
Toward a realistic model of speech processing in the brain with self-supervised learning
Jun 03, 2022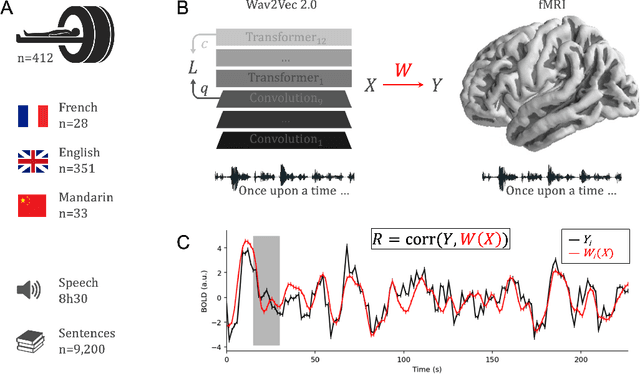
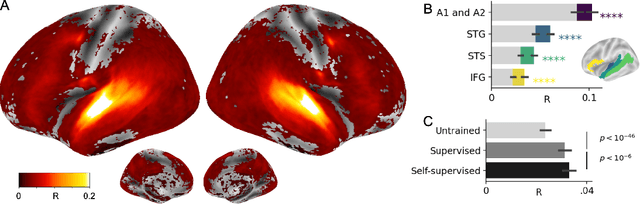
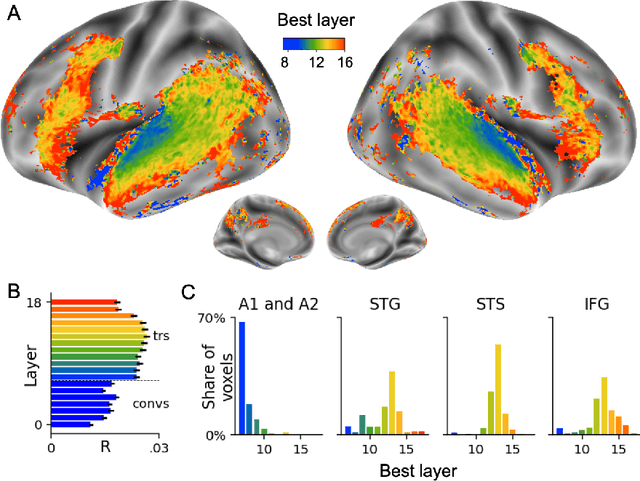
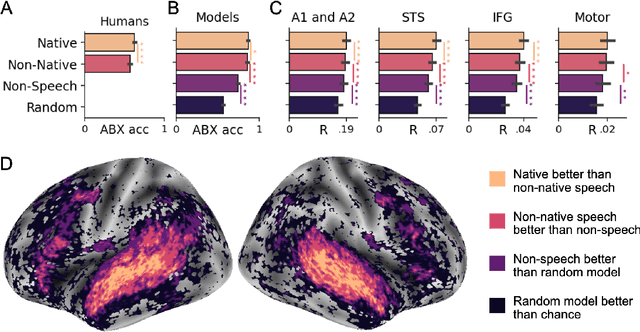
Several deep neural networks have recently been shown to generate activations similar to those of the brain in response to the same input. These algorithms, however, remain largely implausible: they require (1) extraordinarily large amounts of data, (2) unobtainable supervised labels, (3) textual rather than raw sensory input, and / or (4) implausibly large memory (e.g. thousands of contextual words). These elements highlight the need to identify algorithms that, under these limitations, would suffice to account for both behavioral and brain responses. Focusing on the issue of speech processing, we here hypothesize that self-supervised algorithms trained on the raw waveform constitute a promising candidate. Specifically, we compare a recent self-supervised architecture, Wav2Vec 2.0, to the brain activity of 412 English, French, and Mandarin individuals recorded with functional Magnetic Resonance Imaging (fMRI), while they listened to ~1h of audio books. Our results are four-fold. First, we show that this algorithm learns brain-like representations with as little as 600 hours of unlabelled speech -- a quantity comparable to what infants can be exposed to during language acquisition. Second, its functional hierarchy aligns with the cortical hierarchy of speech processing. Third, different training regimes reveal a functional specialization akin to the cortex: Wav2Vec 2.0 learns sound-generic, speech-specific and language-specific representations similar to those of the prefrontal and temporal cortices. Fourth, we confirm the similarity of this specialization with the behavior of 386 additional participants. These elements, resulting from the largest neuroimaging benchmark to date, show how self-supervised learning can account for a rich organization of speech processing in the brain, and thus delineate a path to identify the laws of language acquisition which shape the human brain.
Long-range and hierarchical language predictions in brains and algorithms
Nov 28, 2021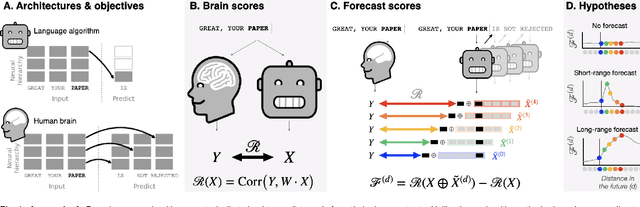
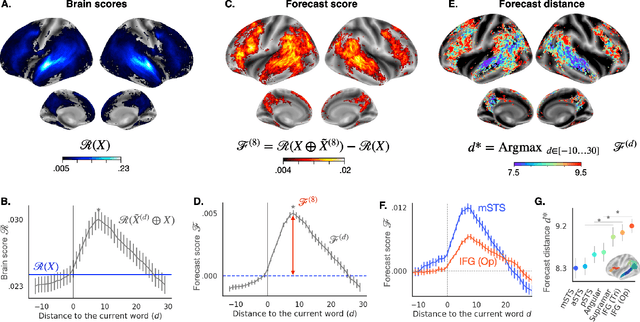
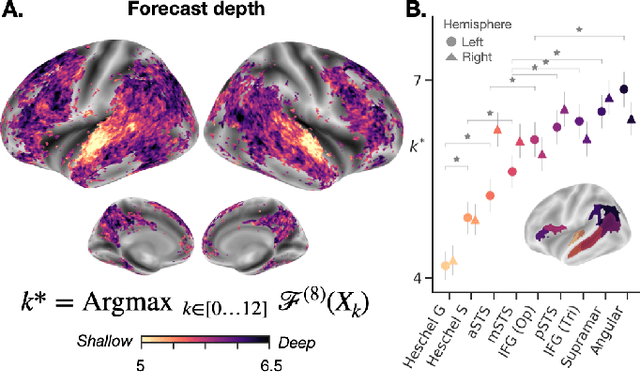
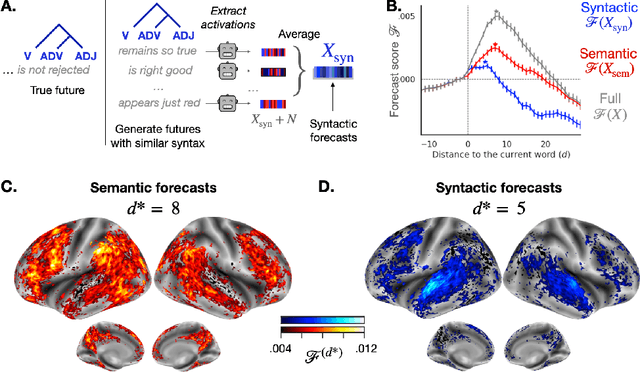
Deep learning has recently made remarkable progress in natural language processing. Yet, the resulting algorithms remain far from competing with the language abilities of the human brain. Predictive coding theory offers a potential explanation to this discrepancy: while deep language algorithms are optimized to predict adjacent words, the human brain would be tuned to make long-range and hierarchical predictions. To test this hypothesis, we analyze the fMRI brain signals of 304 subjects each listening to 70min of short stories. After confirming that the activations of deep language algorithms linearly map onto those of the brain, we show that enhancing these models with long-range forecast representations improves their brain-mapping. The results further reveal a hierarchy of predictions in the brain, whereby the fronto-parietal cortices forecast more abstract and more distant representations than the temporal cortices. Overall, this study strengthens predictive coding theory and suggests a critical role of long-range and hierarchical predictions in natural language processing.
Deep Recurrent Encoder: A scalable end-to-end network to model brain signals
Mar 29, 2021
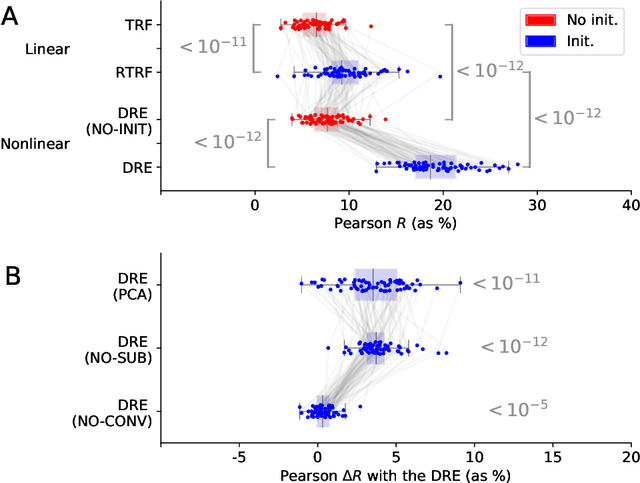
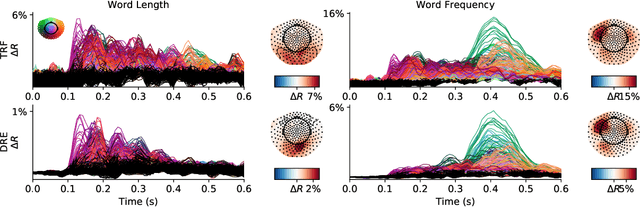
Understanding how the brain responds to sensory inputs is challenging: brain recordings are partial, noisy, and high dimensional; they vary across sessions and subjects and they capture highly nonlinear dynamics. These challenges have led the community to develop a variety of preprocessing and analytical (almost exclusively linear) methods, each designed to tackle one of these issues. Instead, we propose to address these challenges through a specific end-to-end deep learning architecture, trained to predict the brain responses of multiple subjects at once. We successfully test this approach on a large cohort of magnetoencephalography (MEG) recordings acquired during a one-hour reading task. Our Deep Recurrent Encoding (DRE) architecture reliably predicts MEG responses to words with a three-fold improvement over classic linear methods. To overcome the notorious issue of interpretability of deep learning, we describe a simple variable importance analysis. When applied to DRE, this method recovers the expected evoked responses to word length and word frequency. The quantitative improvement of the present deep learning approach paves the way to better understand the nonlinear dynamics of brain activity from large datasets.
Decomposing lexical and compositional syntax and semantics with deep language models
Mar 02, 2021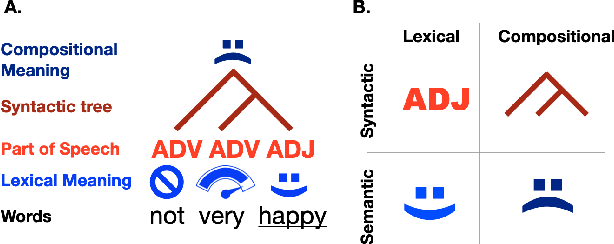
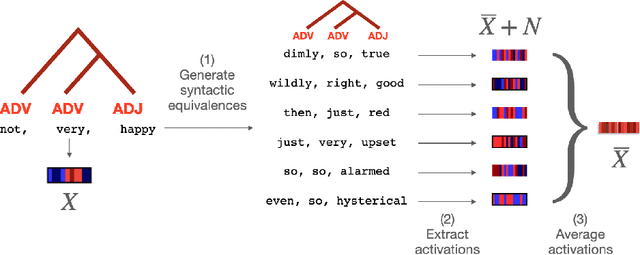
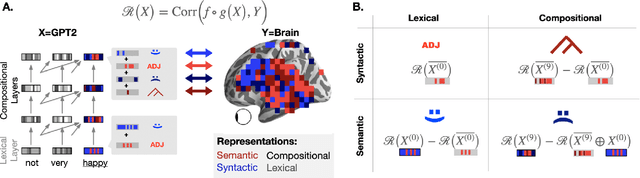
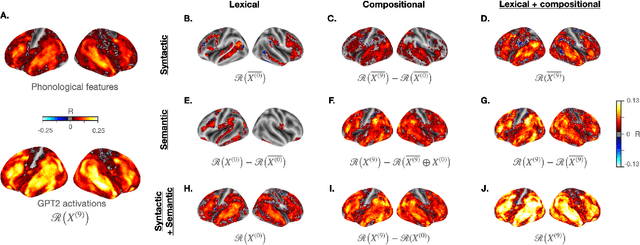
The activations of language transformers like GPT2 have been shown to linearly map onto brain activity during speech comprehension. However, the nature of these activations remains largely unknown and presumably conflate distinct linguistic classes. Here, we propose a taxonomy to factorize the high-dimensional activations of language models into four combinatorial classes: lexical, compositional, syntactic, and semantic representations. We then introduce a statistical method to decompose, through the lens of GPT2's activations, the brain activity of 345 subjects recorded with functional magnetic resonance imaging (fMRI) during the listening of ~4.6 hours of narrated text. The results highlight two findings. First, compositional representations recruit a more widespread cortical network than lexical ones, and encompass the bilateral temporal, parietal and prefrontal cortices. Second, contrary to previous claims, syntax and semantics are not associated with separated modules, but, instead, appear to share a common and distributed neural substrate. Overall, this study introduces a general framework to isolate the distributed representations of linguistic constructs generated in naturalistic settings.
Inductive biases, pretraining and fine-tuning jointly account for brain responses to speech
Feb 25, 2021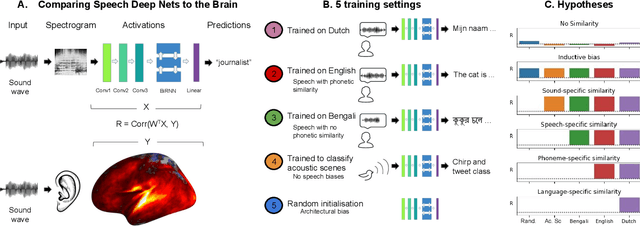
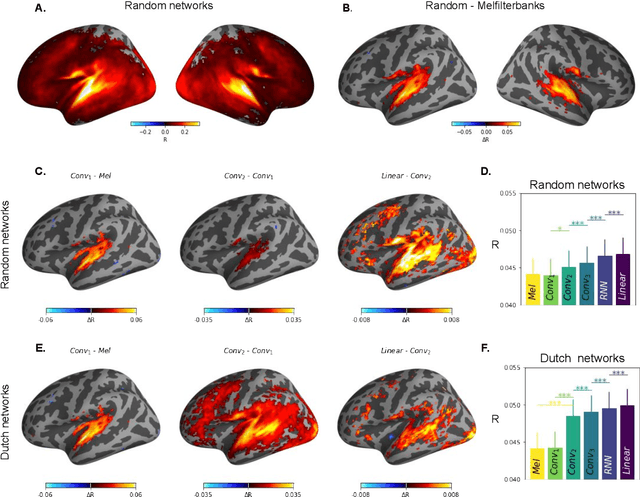
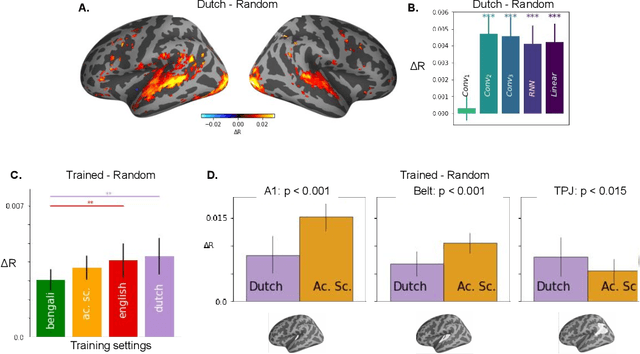
Our ability to comprehend speech remains, to date, unrivaled by deep learning models. This feat could result from the brain's ability to fine-tune generic sound representations for speech-specific processes. To test this hypothesis, we compare i) five types of deep neural networks to ii) human brain responses elicited by spoken sentences and recorded in 102 Dutch subjects using functional Magnetic Resonance Imaging (fMRI). Each network was either trained on an acoustics scene classification, a speech-to-text task (based on Bengali, English, or Dutch), or not trained. The similarity between each model and the brain is assessed by correlating their respective activations after an optimal linear projection. The differences in brain-similarity across networks revealed three main results. First, speech representations in the brain can be accounted for by random deep networks. Second, learning to classify acoustic scenes leads deep nets to increase their brain similarity. Third, learning to process phonetically-related speech inputs (i.e., Dutch vs English) leads deep nets to reach higher levels of brain-similarity than learning to process phonetically-distant speech inputs (i.e. Dutch vs Bengali). Together, these results suggest that the human brain fine-tunes its heavily-trained auditory hierarchy to learn to process speech.