 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergence of Phonemic, Syntactic, and Semantic Representations in Artificial Neural Networks
Jan 26, 2026During language acquisition, children successively learn to categorize phonemes, identify words, and combine them with syntax to form new meaning. While the development of this behavior is well characterized, we still lack a unifying computational framework to explain its underlying neural representations. Here, we investigate whether and when phonemic, lexical, and syntactic representations emerge in the activations of artificial neural networks during their training. Our results show that both speech- and text-based models follow a sequence of learning stages: during training, their neural activations successively build subspaces, where the geometry of the neural activations represents phonemic, lexical, and syntactic structure. While this developmental trajectory qualitatively relates to children's, it is quantitatively different: These algorithms indeed require two to four orders of magnitude more data for these neural representations to emerge. Together, these results show conditions under which major stages of language acquisition spontaneously emerge, and hence delineate a promising path to understand the computations underpinning language acquisition.
Toward a realistic model of speech processing in the brain with self-supervised learning
Jun 03, 2022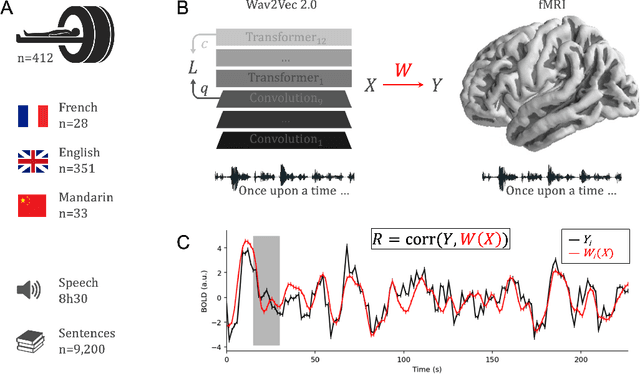
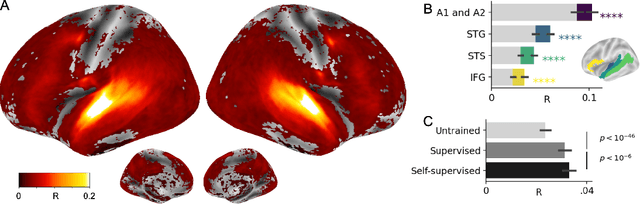
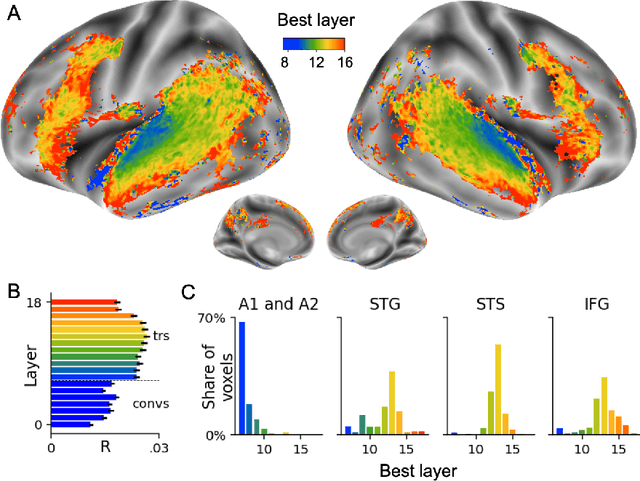
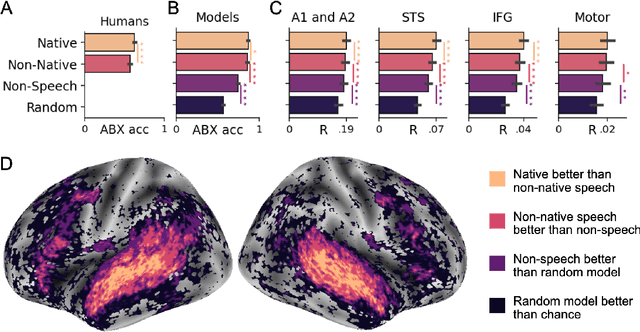
Several deep neural networks have recently been shown to generate activations similar to those of the brain in response to the same input. These algorithms, however, remain largely implausible: they require (1) extraordinarily large amounts of data, (2) unobtainable supervised labels, (3) textual rather than raw sensory input, and / or (4) implausibly large memory (e.g. thousands of contextual words). These elements highlight the need to identify algorithms that, under these limitations, would suffice to account for both behavioral and brain responses. Focusing on the issue of speech processing, we here hypothesize that self-supervised algorithms trained on the raw waveform constitute a promising candidate. Specifically, we compare a recent self-supervised architecture, Wav2Vec 2.0, to the brain activity of 412 English, French, and Mandarin individuals recorded with functional Magnetic Resonance Imaging (fMRI), while they listened to ~1h of audio books. Our results are four-fold. First, we show that this algorithm learns brain-like representations with as little as 600 hours of unlabelled speech -- a quantity comparable to what infants can be exposed to during language acquisition. Second, its functional hierarchy aligns with the cortical hierarchy of speech processing. Third, different training regimes reveal a functional specialization akin to the cortex: Wav2Vec 2.0 learns sound-generic, speech-specific and language-specific representations similar to those of the prefrontal and temporal cortices. Fourth, we confirm the similarity of this specialization with the behavior of 386 additional participants. These elements, resulting from the largest neuroimaging benchmark to date, show how self-supervised learning can account for a rich organization of speech processing in the brain, and thus delineate a path to identify the laws of language acquisition which shape the human brain.
Don't stop the training: continuously-updating self-supervised algorithms best account for auditory responses in the cortex
Feb 15, 2022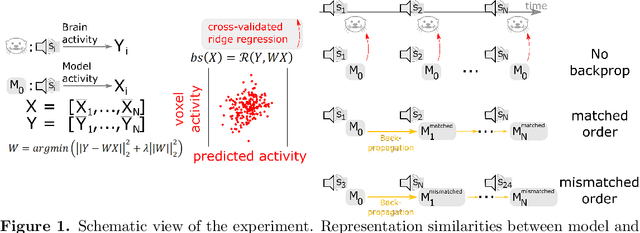
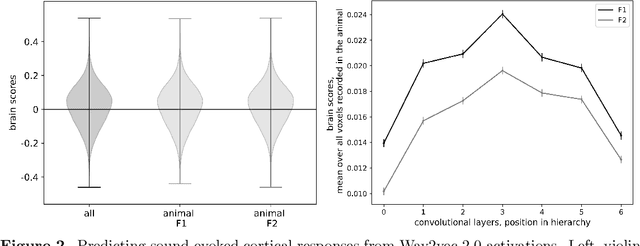
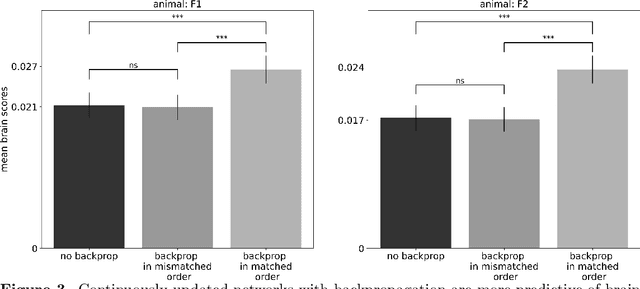
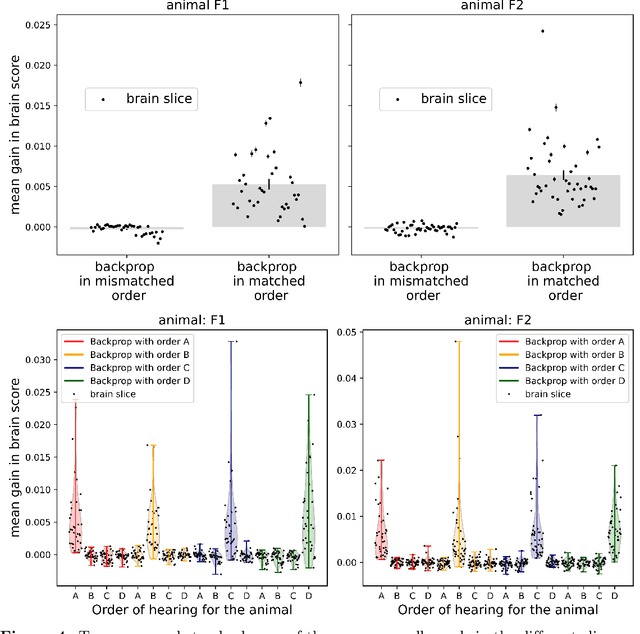
Over the last decade, numerous studies have shown that deep neural networks exhibit sensory representations similar to those of the mammalian brain, in that their activations linearly map onto cortical responses to the same sensory inputs. However, it remains unknown whether these artificial networks also learn like the brain. To address this issue, we analyze the brain responses of two ferret auditory cortices recorded with functional UltraSound imaging (fUS), while the animals were presented with 320 10\,s sounds. We compare these brain responses to the activations of Wav2vec 2.0, a self-supervised neural network pretrained with 960\,h of speech, and input with the same 320 sounds. Critically, we evaluate Wav2vec 2.0 under two distinct modes: (i) "Pretrained", where the same model is used for all sounds, and (ii) "Continuous Update", where the weights of the pretrained model are modified with back-propagation after every sound, presented in the same order as the ferrets. Our results show that the Continuous-Update mode leads Wav2Vec 2.0 to generate activations that are more similar to the brain than a Pretrained Wav2Vec 2.0 or than other control models using different training modes. These results suggest that the trial-by-trial modifications of self-supervised algorithms induced by back-propagation aligns with the corresponding fluctuations of cortical responses to sounds. Our finding thus provides empirical evidence of a common learning mechanism between self-supervised models and the mammalian cortex during sound processing.