 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't stop the training: continuously-updating self-supervised algorithms best account for auditory responses in the cortex
Paper and Code
Feb 15, 2022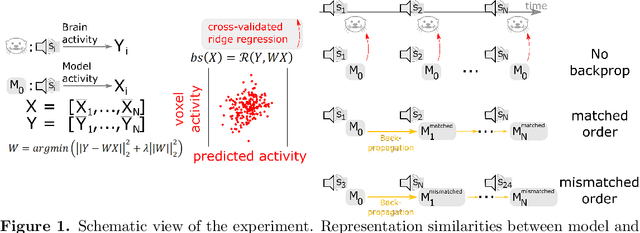
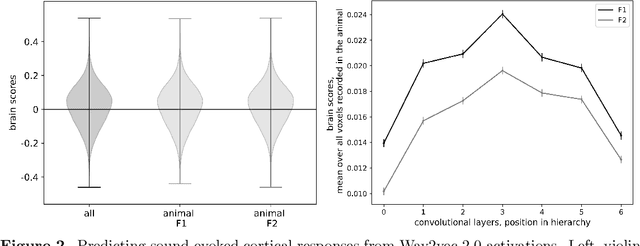
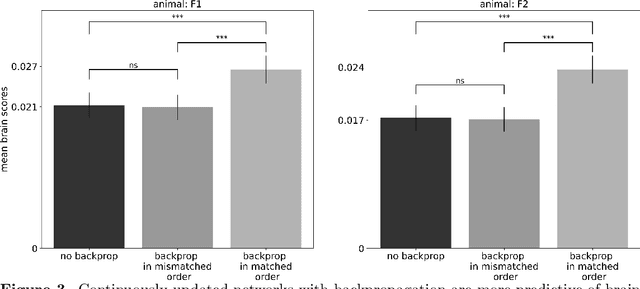
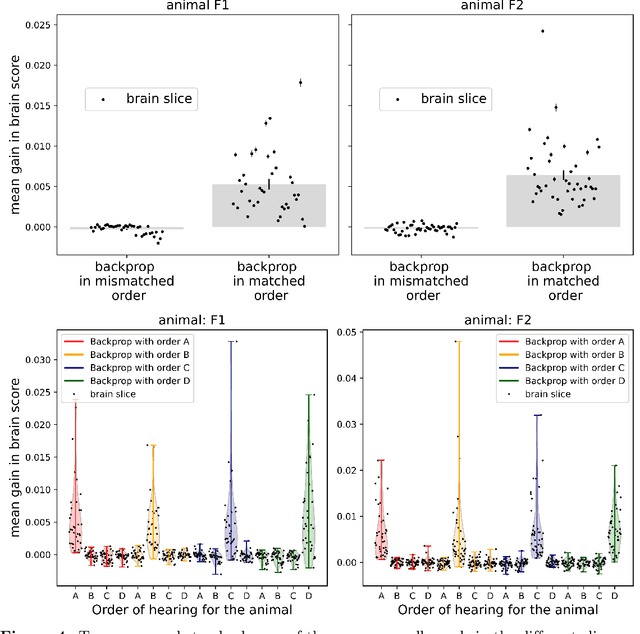
Over the last decade, numerous studies have shown that deep neural networks exhibit sensory representations similar to those of the mammalian brain, in that their activations linearly map onto cortical responses to the same sensory inputs. However, it remains unknown whether these artificial networks also learn like the brain. To address this issue, we analyze the brain responses of two ferret auditory cortices recorded with functional UltraSound imaging (fUS), while the animals were presented with 320 10\,s sounds. We compare these brain responses to the activations of Wav2vec 2.0, a self-supervised neural network pretrained with 960\,h of speech, and input with the same 320 sounds. Critically, we evaluate Wav2vec 2.0 under two distinct modes: (i) "Pretrained", where the same model is used for all sounds, and (ii) "Continuous Update", where the weights of the pretrained model are modified with back-propagation after every sound, presented in the same order as the ferrets. Our results show that the Continuous-Update mode leads Wav2Vec 2.0 to generate activations that are more similar to the brain than a Pretrained Wav2Vec 2.0 or than other control models using different training modes. These results suggest that the trial-by-trial modifications of self-supervised algorithms induced by back-propagation aligns with the corresponding fluctuations of cortical responses to sounds. Our finding thus provides empirical evidence of a common learning mechanism between self-supervised models and the mammalian cortex during sound processing.