 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextually Pretrained Speech Language Models
May 22, 2023



Speech language models (SpeechLMs) process and generate acoustic data only, without textual supervision. In this work, we propose TWIST, a method for training SpeechLMs using a warm-start from a pretrained textual language models. We show using both automatic and human evaluations that TWIST outperforms a cold-start SpeechLM across the board. We empirically analyze the effect of different model design choices such as the speech tokenizer, the pretrained textual model, and the dataset size. We find that model and dataset scale both play an important role in constructing better-performing SpeechLMs. Based on our observations, we present the largest (to the best of our knowledge) SpeechLM both in terms of number of parameters and training data. We additionally introduce two spoken versions of the StoryCloze textual benchmark to further improve model evaluation and advance future research in the field. Speech samples can be found on our website: https://pages.cs.huji.ac.il/adiyoss-lab/twist/ .
Implicit Neural Spatial Filtering for Multichannel Source Separation in the Waveform Domain
Jun 30, 2022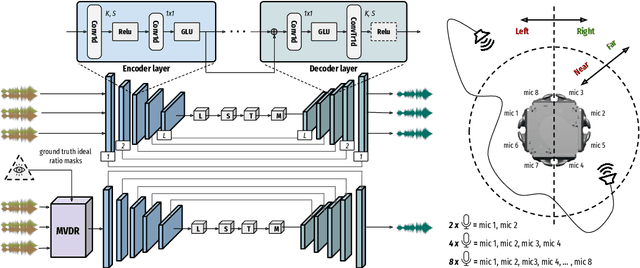
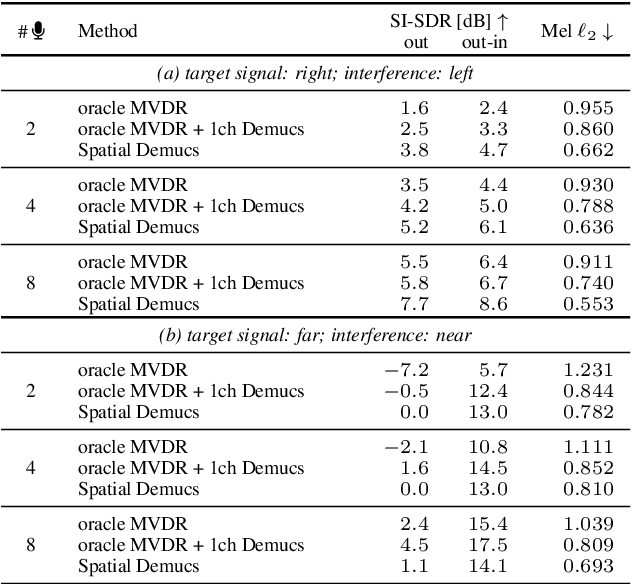
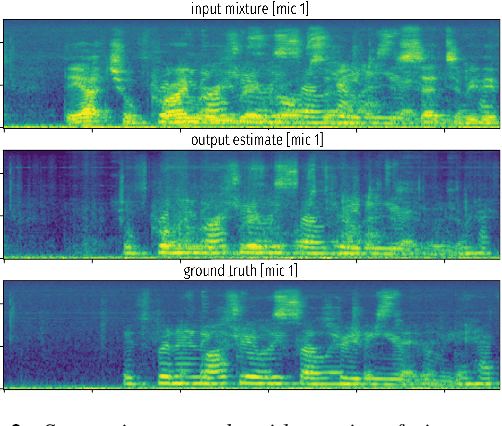
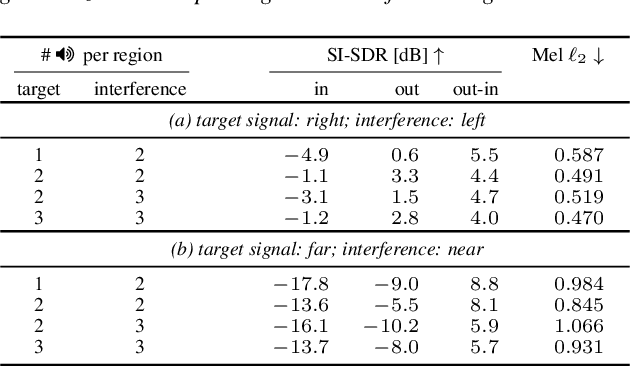
We present a single-stage casual waveform-to-waveform multichannel model that can separate moving sound sources based on their broad spatial locations in a dynamic acoustic scene. We divide the scene into two spatial regions containing, respectively, the target and the interfering sound sources. The model is trained end-to-end and performs spatial processing implicitly, without any components based on traditional processing or use of hand-crafted spatial features. We evaluate the proposed model on a real-world dataset and show that the model matches the performance of an oracle beamformer followed by a state-of-the-art single-channel enhancement network.
Deep Recurrent Encoder: A scalable end-to-end network to model brain signals
Mar 29, 2021
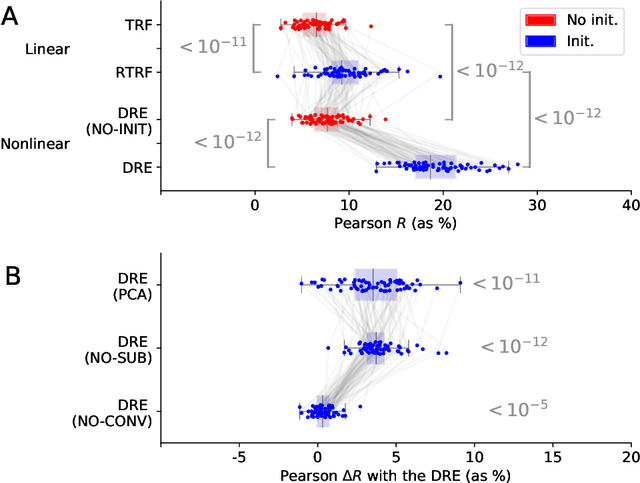
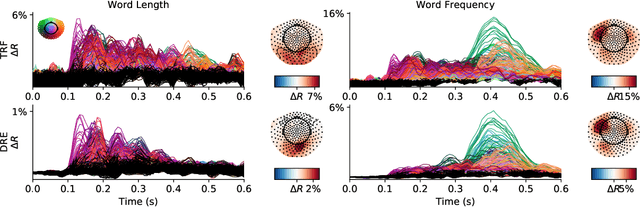
Understanding how the brain responds to sensory inputs is challenging: brain recordings are partial, noisy, and high dimensional; they vary across sessions and subjects and they capture highly nonlinear dynamics. These challenges have led the community to develop a variety of preprocessing and analytical (almost exclusively linear) methods, each designed to tackle one of these issues. Instead, we propose to address these challenges through a specific end-to-end deep learning architecture, trained to predict the brain responses of multiple subjects at once. We successfully test this approach on a large cohort of magnetoencephalography (MEG) recordings acquired during a one-hour reading task. Our Deep Recurrent Encoding (DRE) architecture reliably predicts MEG responses to words with a three-fold improvement over classic linear methods. To overcome the notorious issue of interpretability of deep learning, we describe a simple variable importance analysis. When applied to DRE, this method recovers the expected evoked responses to word length and word frequency. The quantitative improvement of the present deep learning approach paves the way to better understand the nonlinear dynamics of brain activity from large datasets.
Real Time Speech Enhancement in the Waveform Domain
Jun 23, 2020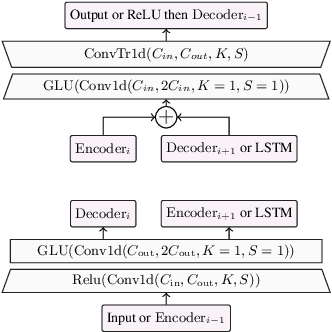
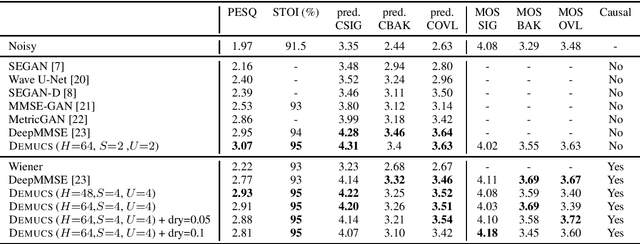
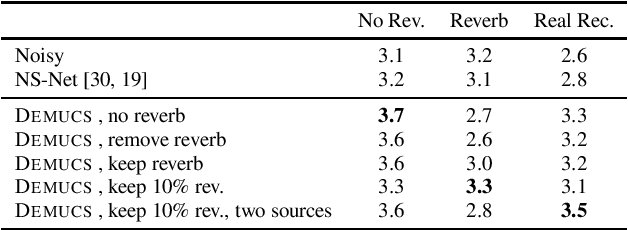

We present a causal speech enhancement model working on the raw waveform that runs in real-time on a laptop CPU. The proposed model is based on an encoder-decoder architecture with skip-connections. It is optimized on both time and frequency domains, using multiple loss functions. Empirical evidence shows that it is capable of removing various kinds of background noise including stationary and non-stationary noises, as well as room reverb. Additionally, we suggest a set of data augmentation techniques applied directly on the raw waveform which further improve model performance and its generalization abilities. We perform evaluations on several standard benchmarks, both using objective metrics and human judgements. The proposed model matches state-of-the-art performance of both causal and non causal methods while working directly on the raw waveform.