Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Neural Spatial Filtering for Multichannel Source Separation in the Waveform Domain
Paper and Code
Jun 30, 2022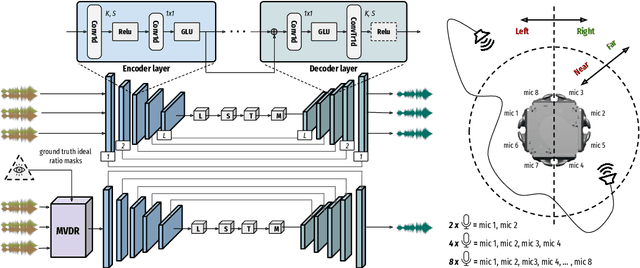
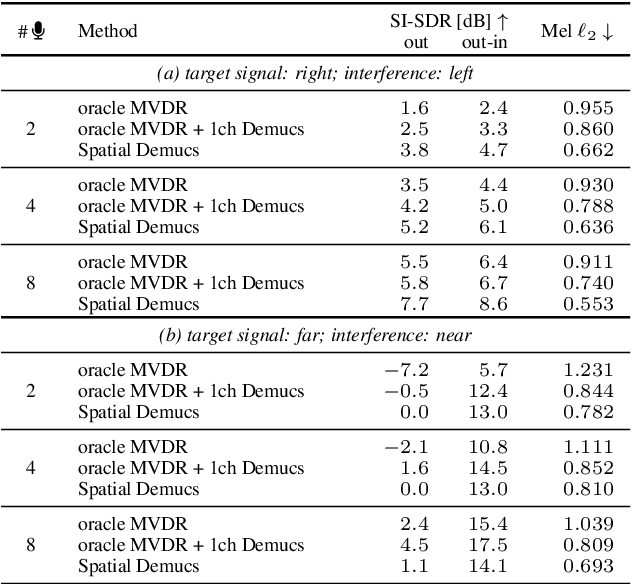
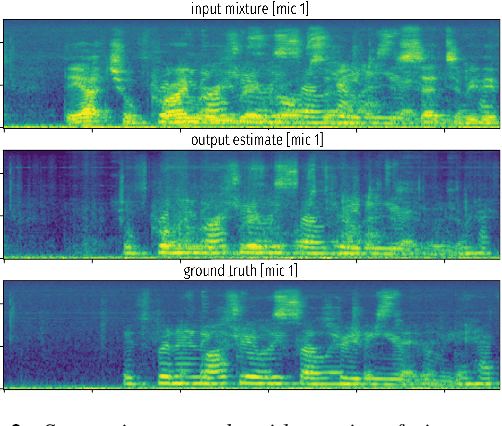
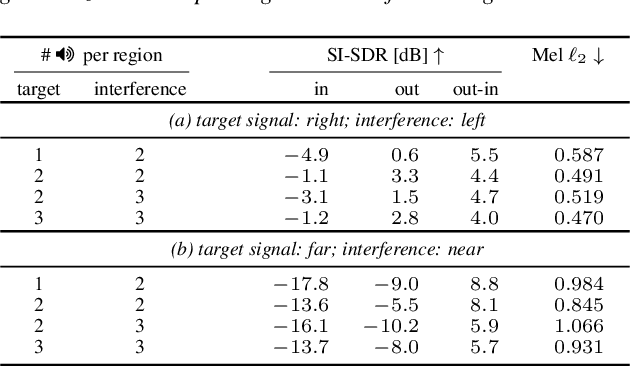
We present a single-stage casual waveform-to-waveform multichannel model that can separate moving sound sources based on their broad spatial locations in a dynamic acoustic scene. We divide the scene into two spatial regions containing, respectively, the target and the interfering sound sources. The model is trained end-to-end and performs spatial processing implicitly, without any components based on traditional processing or use of hand-crafted spatial features. We evaluate the proposed model on a real-world dataset and show that the model matches the performance of an oracle beamformer followed by a state-of-the-art single-channel enhancement network.
* Interspeech 2022
View paper on