 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoBabyVLM: Benchmarking Cross-Modal Learning from Naturalistic Egocentric Video Data
May 18, 2026Children acquire language grounding with remarkable robustness from limited visuo-linguistic input in ways that surpass today's best large multimodal models. Recent research suggests current vision-language models (VLMs) trained on curated web data fail to generalize to the sparse, weakly-aligned egocentric streams produced by wearable devices, embodied agents, and infant head-cams -- and no fixed evaluation pipeline exists for measuring progress on this regime. We train VLMs on datasets with varying degrees of semantic alignment between visual and linguistic inputs, including naturalistic infant and adult egocentric videos, and evaluate them with a comprehensive suite spanning multimodal language grounding and unimodal vision and language tasks. At the core of this suite is Machine-DevBench, a corpus-grounded benchmark of lexical and grammatical competence, automatically generated from the model's training vocabulary across logarithmic frequency bins to eliminate the train/eval mismatch and low statistical power of prior developmental benchmarks. Our results show that current VLM paradigms hinge on the tight semantic alignment of curated data and fail to exploit the weakly-aligned signal that dominates naturalistic egocentric input -- the very regime in which humans thrive. To motivate progress, we introduce the EgoBabyVLM Challenge to drive the development of models capable of grounded language learning from the kind of naturalistic data that human infants experience.
DiscoPhon: Benchmarking the Unsupervised Discovery of Phoneme Inventories With Discrete Speech Units
Mar 19, 2026We introduce DiscoPhon, a multilingual benchmark for evaluating unsupervised phoneme discovery from discrete speech units. DiscoPhon covers 6 dev and 6 test languages, chosen to span a wide range of phonemic contrasts. Given only 10 hours of speech in a previously unseen language, systems must produce discrete units that are mapped to a predefined phoneme inventory, through either a many-to-one or a one-to-one assignment. The resulting sequences are evaluated for unit quality, recognition and segmentation. We provide four pretrained multilingual HuBERT and SpidR baselines, and show that phonemic information is available enough in current models for derived units to correlate well with phonemes, though with variations across languages.
Why AI systems don't learn and what to do about it: Lessons on autonomous learning from cognitive science
Mar 16, 2026We critically examine the limitations of current AI models in achieving autonomous learning and propose a learning architecture inspired by human and animal cognition. The proposed framework integrates learning from observation (System A) and learning from active behavior (System B) while flexibly switching between these learning modes as a function of internally generated meta-control signals (System M). We discuss how this could be built by taking inspiration on how organisms adapt to real-world, dynamic environments across evolutionary and developmental timescales.
SpidR-Adapt: A Universal Speech Representation Model for Few-Shot Adaptation
Dec 24, 2025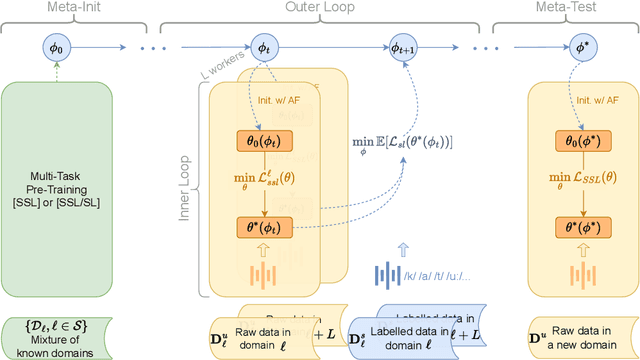

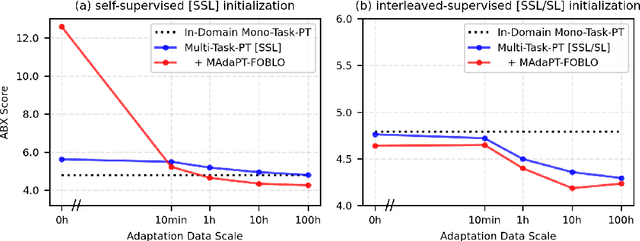
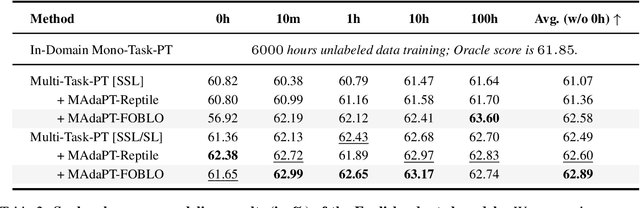
Human infants, with only a few hundred hours of speech exposure, acquire basic units of new languages, highlighting a striking efficiency gap compared to the data-hungry self-supervised speech models. To address this gap, this paper introduces SpidR-Adapt for rapid adaptation to new languages using minimal unlabeled data. We cast such low-resource speech representation learning as a meta-learning problem and construct a multi-task adaptive pre-training (MAdaPT) protocol which formulates the adaptation process as a bi-level optimization framework. To enable scalable meta-training under this framework, we propose a novel heuristic solution, first-order bi-level optimization (FOBLO), avoiding heavy computation costs. Finally, we stabilize meta-training by using a robust initialization through interleaved supervision which alternates self-supervised and supervised objectives. Empirically, SpidR-Adapt achieves rapid gains in phonemic discriminability (ABX) and spoken language modeling (sWUGGY, sBLIMP, tSC), improving over in-domain language models after training on less than 1h of target-language audio, over $100\times$ more data-efficient than standard training. These findings highlight a practical, architecture-agnostic path toward biologically inspired, data-efficient representations. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr-adapt.
SpidR: Learning Fast and Stable Linguistic Units for Spoken Language Models Without Supervision
Dec 23, 2025The parallel advances in language modeling and speech representation learning have raised the prospect of learning language directly from speech without textual intermediates. This requires extracting semantic representations directly from speech. Our contributions are threefold. First, we introduce SpidR, a self-supervised speech representation model that efficiently learns representations with highly accessible phonetic information, which makes it particularly suited for textless spoken language modeling. It is trained on raw waveforms using a masked prediction objective combined with self-distillation and online clustering. The intermediate layers of the student model learn to predict assignments derived from the teacher's intermediate layers. This learning objective stabilizes the online clustering procedure compared to previous approaches, resulting in higher quality codebooks. SpidR outperforms wav2vec 2.0, HuBERT, WavLM, and DinoSR on downstream language modeling benchmarks (sWUGGY, sBLIMP, tSC). Second, we systematically evaluate across models and layers the correlation between speech unit quality (ABX, PNMI) and language modeling performance, validating these metrics as reliable proxies. Finally, SpidR significantly reduces pretraining time compared to HuBERT, requiring only one day of pretraining on 16 GPUs, instead of a week. This speedup is enabled by the pretraining method and an efficient codebase, which allows faster iteration and easier experimentation. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr.
MauBERT: Universal Phonetic Inductive Biases for Few-Shot Acoustic Units Discovery
Dec 22, 2025This paper introduces MauBERT, a multilingual extension of HuBERT that leverages articulatory features for robust cross-lingual phonetic representation learning. We continue HuBERT pre-training with supervision based on a phonetic-to-articulatory feature mapping in 55 languages. Our models learn from multilingual data to predict articulatory features or phones, resulting in language-independent representations that capture multilingual phonetic properties. Through comprehensive ABX discriminability testing, we show MauBERT models produce more context-invariant representations than state-of-the-art multilingual self-supervised learning models. Additionally, the models effectively adapt to unseen languages and casual speech with minimal self-supervised fine-tuning (10 hours of speech). This establishes an effective approach for instilling linguistic inductive biases in self-supervised speech models.
LongTail-Swap: benchmarking language models' abilities on rare words
Oct 05, 2025Children learn to speak with a low amount of data and can be taught new words on a few-shot basis, making them particularly data-efficient learners. The BabyLM challenge aims at exploring language model (LM) training in the low-data regime but uses metrics that concentrate on the head of the word distribution. Here, we introduce LongTail-Swap (LT-Swap), a benchmark that focuses on the tail of the distribution, i.e., measures the ability of LMs to learn new words with very little exposure, like infants do. LT-Swap is a pretraining corpus-specific test set of acceptable versus unacceptable sentence pairs that isolate semantic and syntactic usage of rare words. Models are evaluated in a zero-shot fashion by computing the average log probabilities over the two members of each pair. We built two such test sets associated with the 10M words and 100M words BabyLM training sets, respectively, and evaluated 16 models from the BabyLM leaderboard. Our results not only highlight the poor performance of language models on rare words but also reveal that performance differences across LM architectures are much more pronounced in the long tail than in the head. This offers new insights into which architectures are better at handling rare word generalization. We've also made the code publicly avail
BabyHuBERT: Multilingual Self-Supervised Learning for Segmenting Speakers in Child-Centered Long-Form Recordings
Sep 18, 2025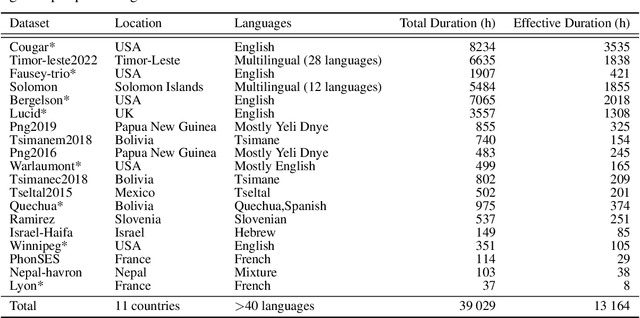
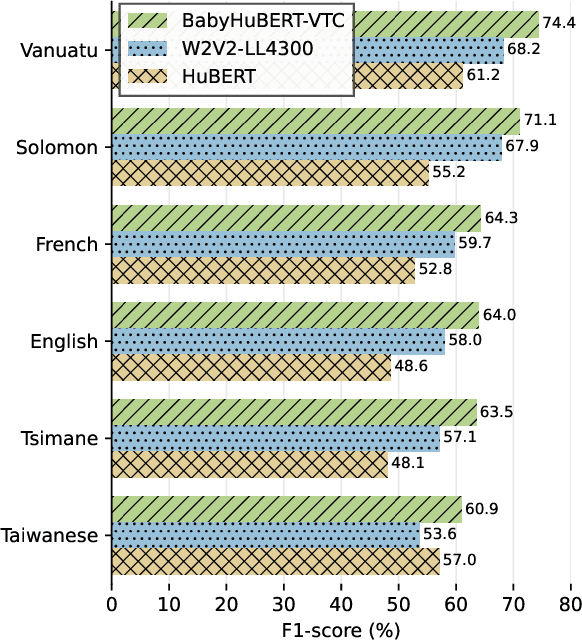
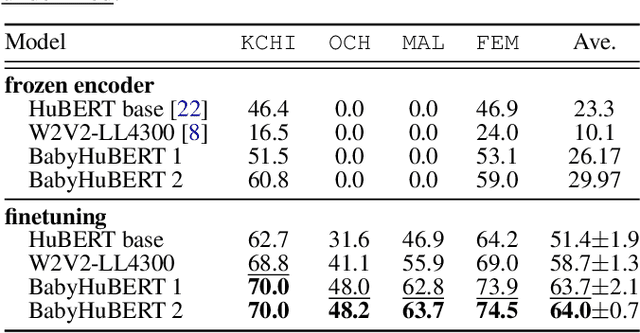
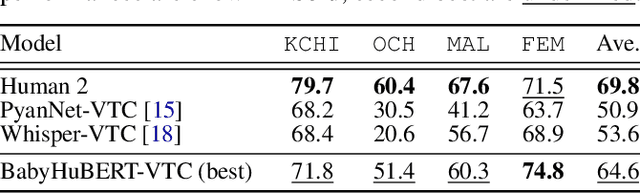
Child-centered long-form recordings are essential for studying early language development, but existing speech models trained on clean adult data perform poorly due to acoustic and linguistic differences. We introduce BabyHuBERT, the first self-supervised speech representation model trained on 13,000 hours of multilingual child-centered long-form recordings spanning over 40 languages. We evaluate BabyHuBERT on speaker segmentation, identifying when target children speak versus female adults, male adults, or other children -- a fundamental preprocessing step for analyzing naturalistic language experiences. BabyHuBERT achieves F1-scores from 52.1% to 74.4% across six diverse datasets, consistently outperforming W2V2-LL4300 (trained on English long-forms) and standard HuBERT (trained on clean adult speech). Notable improvements include 13.2 absolute F1 points over HuBERT on Vanuatu and 15.9 points on Solomon Islands corpora, demonstrating effectiveness on underrepresented languages. By sharing code and models, BabyHuBERT serves as a foundation model for child speech research, enabling fine-tuning on diverse downstream tasks.
IntPhys 2: Benchmarking Intuitive Physics Understanding In Complex Synthetic Environments
Jun 11, 2025



We present IntPhys 2, a video benchmark designed to evaluate the intuitive physics understanding of deep learning models. Building on the original IntPhys benchmark, IntPhys 2 focuses on four core principles related to macroscopic objects: Permanence, Immutability, Spatio-Temporal Continuity, and Solidity. These conditions are inspired by research into intuitive physical understanding emerging during early childhood. IntPhys 2 offers a comprehensive suite of tests, based on the violation of expectation framework, that challenge models to differentiate between possible and impossible events within controlled and diverse virtual environments. Alongside the benchmark, we provide performance evaluations of several state-of-the-art models. Our findings indicate that while these models demonstrate basic visual understanding, they face significant challenges in grasping intuitive physics across the four principles in complex scenes, with most models performing at chance levels (50%), in stark contrast to human performance, which achieves near-perfect accuracy. This underscores the gap between current models and human-like intuitive physics understanding, highlighting the need for advancements in model architectures and training methodologies.
fastabx: A library for efficient computation of ABX discriminability
May 05, 2025



We introduce fastabx, a high-performance Python library for building ABX discrimination tasks. ABX is a measure of the separation between generic categories of interest. It has been used extensively to evaluate phonetic discriminability in self-supervised speech representations. However, its broader adoption has been limited by the absence of adequate tools. fastabx addresses this gap by providing a framework capable of constructing any type of ABX task while delivering the efficiency necessary for rapid development cycles, both in task creation and in calculating distances between representations. We believe that fastabx will serve as a valuable resource for the broader representation learning community, enabling researchers to systematically investigate what information can be directly extracted from learned representations across several domains beyond speech processing. The source code is available at https://github.com/bootphon/fastabx.