 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Planning with Latent World Models
Apr 03, 2026Model predictive control (MPC) with learned world models has emerged as a promising paradigm for embodied control, particularly for its ability to generalize zero-shot when deployed in new environments. However, learned world models often struggle with long-horizon control due to the accumulation of prediction errors and the exponentially growing search space. In this work, we address these challenges by learning latent world models at multiple temporal scales and performing hierarchical planning across these scales, enabling long-horizon reasoning while substantially reducing inference-time planning complexity. Our approach serves as a modular planning abstraction that applies across diverse latent world-model architectures and domains. We demonstrate that this hierarchical approach enables zero-shot control on real-world non-greedy robotic tasks, achieving a 70% success rate on pick-&-place using only a final goal specification, compared to 0% for a single-level world model. In addition, across physics-based simulated environments including push manipulation and maze navigation, hierarchical planning achieves higher success while requiring up to 4x less planning-time compute.
V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning
Mar 17, 2026We present V-JEPA 2.1, a family of self-supervised models that learn dense, high-quality visual representations for both images and videos while retaining strong global scene understanding. The approach combines four key components. First, a dense predictive loss uses a masking-based objective in which both visible and masked tokens contribute to the training signal, encouraging explicit spatial and temporal grounding. Second, deep self-supervision applies the self-supervised objective hierarchically across multiple intermediate encoder layers to improve representation quality. Third, multi-modal tokenizers enable unified training across images and videos. Finally, the model benefits from effective scaling in both model capacity and training data. Together, these design choices produce representations that are spatially structured, semantically coherent, and temporally consistent. Empirically, V-JEPA 2.1 achieves state-of-the-art performance on several challenging benchmarks, including 7.71 mAP on Ego4D for short-term object-interaction anticipation and 40.8 Recall@5 on EPIC-KITCHENS for high-level action anticipation, as well as a 20-point improvement in real-robot grasping success rate over V-JEPA-2 AC. The model also demonstrates strong performance in robotic navigation (5.687 ATE on TartanDrive), depth estimation (0.307 RMSE on NYUv2 with a linear probe), and global recognition (77.7 on Something-Something-V2). These results show that V-JEPA 2.1 significantly advances the state of the art in dense visual understanding and world modeling.
What Drives Success in Physical Planning with Joint-Embedding Predictive World Models?
Dec 30, 2025A long-standing challenge in AI is to develop agents capable of solving a wide range of physical tasks and generalizing to new, unseen tasks and environments. A popular recent approach involves training a world model from state-action trajectories and subsequently use it with a planning algorithm to solve new tasks. Planning is commonly performed in the input space, but a recent family of methods has introduced planning algorithms that optimize in the learned representation space of the world model, with the promise that abstracting irrelevant details yields more efficient planning. In this work, we characterize models from this family as JEPA-WMs and investigate the technical choices that make algorithms from this class work. We propose a comprehensive study of several key components with the objective of finding the optimal approach within the family. We conducted experiments using both simulated environments and real-world robotic data, and studied how the model architecture, the training objective, and the planning algorithm affect planning success. We combine our findings to propose a model that outperforms two established baselines, DINO-WM and V-JEPA-2-AC, in both navigation and manipulation tasks. Code, data and checkpoints are available at https://github.com/facebookresearch/jepa-wms.
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Jun 11, 2025A major challenge for modern AI is to learn to understand the world and learn to act largely by observation. This paper explores a self-supervised approach that combines internet-scale video data with a small amount of interaction data (robot trajectories), to develop models capable of understanding, predicting, and planning in the physical world. We first pre-train an action-free joint-embedding-predictive architecture, V-JEPA 2, on a video and image dataset comprising over 1 million hours of internet video. V-JEPA 2 achieves strong performance on motion understanding (77.3 top-1 accuracy on Something-Something v2) and state-of-the-art performance on human action anticipation (39.7 recall-at-5 on Epic-Kitchens-100) surpassing previous task-specific models. Additionally, after aligning V-JEPA 2 with a large language model, we demonstrate state-of-the-art performance on multiple video question-answering tasks at the 8 billion parameter scale (e.g., 84.0 on PerceptionTest, 76.9 on TempCompass). Finally, we show how self-supervised learning can be applied to robotic planning tasks by post-training a latent action-conditioned world model, V-JEPA 2-AC, using less than 62 hours of unlabeled robot videos from the Droid dataset. We deploy V-JEPA 2-AC zero-shot on Franka arms in two different labs and enable picking and placing of objects using planning with image goals. Notably, this is achieved without collecting any data from the robots in these environments, and without any task-specific training or reward. This work demonstrates how self-supervised learning from web-scale data and a small amount of robot interaction data can yield a world model capable of planning in the physical world.
Intuitive physics understanding emerges from self-supervised pretraining on natural videos
Feb 17, 2025We investigate the emergence of intuitive physics understanding in general-purpose deep neural network models trained to predict masked regions in natural videos. Leveraging the violation-of-expectation framework, we find that video prediction models trained to predict outcomes in a learned representation space demonstrate an understanding of various intuitive physics properties, such as object permanence and shape consistency. In contrast, video prediction in pixel space and multimodal large language models, which reason through text, achieve performance closer to chance. Our comparisons of these architectures reveal that jointly learning an abstract representation space while predicting missing parts of sensory input, akin to predictive coding, is sufficient to acquire an understanding of intuitive physics, and that even models trained on one week of unique video achieve above chance performance. This challenges the idea that core knowledge -- a set of innate systems to help understand the world -- needs to be hardwired to develop an understanding of intuitive physics.
An Introduction to Vision-Language Modeling
May 27, 2024


Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
Learning and Leveraging World Models in Visual Representation Learning
Mar 01, 2024


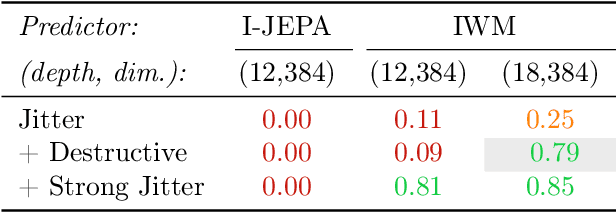
Joint-Embedding Predictive Architecture (JEPA) has emerged as a promising self-supervised approach that learns by leveraging a world model. While previously limited to predicting missing parts of an input, we explore how to generalize the JEPA prediction task to a broader set of corruptions. We introduce Image World Models, an approach that goes beyond masked image modeling and learns to predict the effect of global photometric transformations in latent space. We study the recipe of learning performant IWMs and show that it relies on three key aspects: conditioning, prediction difficulty, and capacity. Additionally, we show that the predictive world model learned by IWM can be adapted through finetuning to solve diverse tasks; a fine-tuned IWM world model matches or surpasses the performance of previous self-supervised methods. Finally, we show that learning with an IWM allows one to control the abstraction level of the learned representations, learning invariant representations such as contrastive methods, or equivariant representations such as masked image modelling.
Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks
Nov 20, 2023



Neural network based computer vision systems are typically built on a backbone, a pretrained or randomly initialized feature extractor. Several years ago, the default option was an ImageNet-trained convolutional neural network. However, the recent past has seen the emergence of countless backbones pretrained using various algorithms and datasets. While this abundance of choice has led to performance increases for a range of systems, it is difficult for practitioners to make informed decisions about which backbone to choose. Battle of the Backbones (BoB) makes this choice easier by benchmarking a diverse suite of pretrained models, including vision-language models, those trained via self-supervised learning, and the Stable Diffusion backbone, across a diverse set of computer vision tasks ranging from classification to object detection to OOD generalization and more. Furthermore, BoB sheds light on promising directions for the research community to advance computer vision by illuminating strengths and weakness of existing approaches through a comprehensive analysis conducted on more than 1500 training runs. While vision transformers (ViTs) and self-supervised learning (SSL) are increasingly popular, we find that convolutional neural networks pretrained in a supervised fashion on large training sets still perform best on most tasks among the models we consider. Moreover, in apples-to-apples comparisons on the same architectures and similarly sized pretraining datasets, we find that SSL backbones are highly competitive, indicating that future works should perform SSL pretraining with advanced architectures and larger pretraining datasets. We release the raw results of our experiments along with code that allows researchers to put their own backbones through the gauntlet here: https://github.com/hsouri/Battle-of-the-Backbones
MC-JEPA: A Joint-Embedding Predictive Architecture for Self-Supervised Learning of Motion and Content Features
Jul 24, 2023Self-supervised learning of visual representations has been focusing on learning content features, which do not capture object motion or location, and focus on identifying and differentiating objects in images and videos. On the other hand, optical flow estimation is a task that does not involve understanding the content of the images on which it is estimated. We unify the two approaches and introduce MC-JEPA, a joint-embedding predictive architecture and self-supervised learning approach to jointly learn optical flow and content features within a shared encoder, demonstrating that the two associated objectives; the optical flow estimation objective and the self-supervised learning objective; benefit from each other and thus learn content features that incorporate motion information. The proposed approach achieves performance on-par with existing unsupervised optical flow benchmarks, as well as with common self-supervised learning approaches on downstream tasks such as semantic segmentation of images and videos.
A Cookbook of Self-Supervised Learning
Apr 24, 2023



Self-supervised learning, dubbed the dark matter of intelligence, is a promising path to advance machine learning. Yet, much like cooking, training SSL methods is a delicate art with a high barrier to entry. While many components are familiar, successfully training a SSL method involves a dizzying set of choices from the pretext tasks to training hyper-parameters. Our goal is to lower the barrier to entry into SSL research by laying the foundations and latest SSL recipes in the style of a cookbook. We hope to empower the curious researcher to navigate the terrain of methods, understand the role of the various knobs, and gain the know-how required to explore how delicious SSL can be.