 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoldiCLIP: The Goldilocks Approach for Balancing Explicit Supervision for Language-Image Pretraining
Mar 25, 2026Until recently, the success of large-scale vision-language models (VLMs) has primarily relied on billion-sample datasets, posing a significant barrier to progress. Latest works have begun to close this gap by improving supervision quality, but each addresses only a subset of the weaknesses in contrastive pretraining. We present GoldiCLIP, a framework built on a Goldilocks principle of finding the right balance of supervision signals. Our multifaceted training framework synergistically combines three key innovations: (1) a text-conditioned self-distillation method to align both text-agnostic and text-conditioned features; (2) an encoder integrated decoder with Visual Question Answering (VQA) objective that enables the encoder to generalize beyond the caption-like queries; and (3) an uncertainty-based weighting mechanism that automatically balances all heterogeneous losses. Trained on just 30 million images, 300x less data than leading methods, GoldiCLIP achieves state-of-the-art among data-efficient approaches, improving over the best comparable baseline by 2.2 points on MSCOCO retrieval, 2.0 on fine-grained retrieval, and 5.9 on question-based retrieval, while remaining competitive with billion-scale models. Project page: https://petsi.uk/goldiclip.
ARGENT: Adaptive Hierarchical Image-Text Representations
Mar 24, 2026Large-scale Vision-Language Models (VLMs) such as CLIP learn powerful semantic representations but operate in Euclidean space, which fails to capture the inherent hierarchical structure of visual and linguistic concepts. Hyperbolic geometry, with its exponential volume growth, offers a principled alternative for embedding such hierarchies with low distortion. However, existing hyperbolic VLMs use entailment losses that are unstable: as parent embeddings contract toward the origin, their entailment cones widen toward a half-space, causing catastrophic cone collapse that destroys the intended hierarchy. Additionally, hierarchical evaluation of these models remains unreliable, being largely retrieval-based and correlation-based metrics and prone to taxonomy dependence and ambiguous negatives. To address these limitations, we propose an adaptive entailment loss paired with a norm regularizer that prevents cone collapse without heuristic aperture clipping. We further introduce an angle-based probabilistic entailment protocol (PEP) for evaluating hierarchical understanding, scored with AUC-ROC and Average Precision. This paper introduces a stronger hyperbolic VLM baseline ARGENT, Adaptive hieRarchical imaGe-tExt represeNTation. ARGENT improves the SOTA hyperbolic VLM by 0.7, 1.1, and 0.8 absolute points on image classification, text-to-image retrieval, and proposed hierarchical metrics, respectively.
Generating Potent Poisons and Backdoors from Scratch with Guided Diffusion
Mar 25, 2024



Modern neural networks are often trained on massive datasets that are web scraped with minimal human inspection. As a result of this insecure curation pipeline, an adversary can poison or backdoor the resulting model by uploading malicious data to the internet and waiting for a victim to scrape and train on it. Existing approaches for creating poisons and backdoors start with randomly sampled clean data, called base samples, and then modify those samples to craft poisons. However, some base samples may be significantly more amenable to poisoning than others. As a result, we may be able to craft more potent poisons by carefully choosing the base samples. In this work, we use guided diffusion to synthesize base samples from scratch that lead to significantly more potent poisons and backdoors than previous state-of-the-art attacks. Our Guided Diffusion Poisoning (GDP) base samples can be combined with any downstream poisoning or backdoor attack to boost its effectiveness. Our implementation code is publicly available at: https://github.com/hsouri/GDP .
Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks
Nov 20, 2023



Neural network based computer vision systems are typically built on a backbone, a pretrained or randomly initialized feature extractor. Several years ago, the default option was an ImageNet-trained convolutional neural network. However, the recent past has seen the emergence of countless backbones pretrained using various algorithms and datasets. While this abundance of choice has led to performance increases for a range of systems, it is difficult for practitioners to make informed decisions about which backbone to choose. Battle of the Backbones (BoB) makes this choice easier by benchmarking a diverse suite of pretrained models, including vision-language models, those trained via self-supervised learning, and the Stable Diffusion backbone, across a diverse set of computer vision tasks ranging from classification to object detection to OOD generalization and more. Furthermore, BoB sheds light on promising directions for the research community to advance computer vision by illuminating strengths and weakness of existing approaches through a comprehensive analysis conducted on more than 1500 training runs. While vision transformers (ViTs) and self-supervised learning (SSL) are increasingly popular, we find that convolutional neural networks pretrained in a supervised fashion on large training sets still perform best on most tasks among the models we consider. Moreover, in apples-to-apples comparisons on the same architectures and similarly sized pretraining datasets, we find that SSL backbones are highly competitive, indicating that future works should perform SSL pretraining with advanced architectures and larger pretraining datasets. We release the raw results of our experiments along with code that allows researchers to put their own backbones through the gauntlet here: https://github.com/hsouri/Battle-of-the-Backbones
Thinking Two Moves Ahead: Anticipating Other Users Improves Backdoor Attacks in Federated Learning
Oct 17, 2022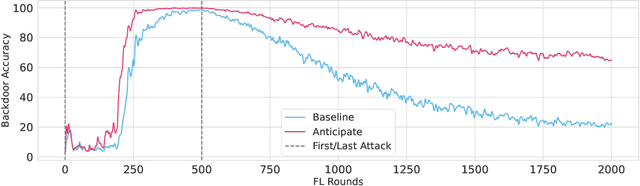
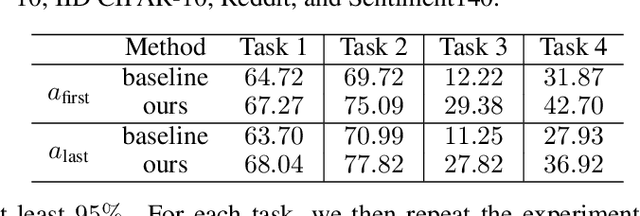
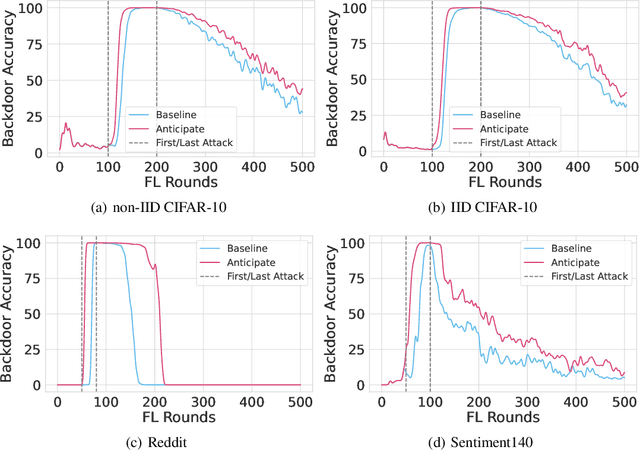
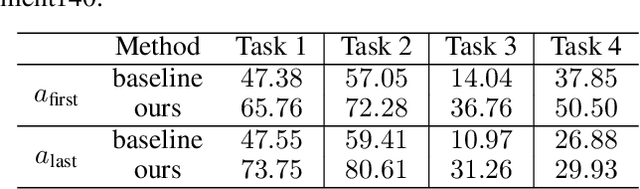
Federated learning is particularly susceptible to model poisoning and backdoor attacks because individual users have direct control over the training data and model updates. At the same time, the attack power of an individual user is limited because their updates are quickly drowned out by those of many other users. Existing attacks do not account for future behaviors of other users, and thus require many sequential updates and their effects are quickly erased. We propose an attack that anticipates and accounts for the entire federated learning pipeline, including behaviors of other clients, and ensures that backdoors are effective quickly and persist even after multiple rounds of community updates. We show that this new attack is effective in realistic scenarios where the attacker only contributes to a small fraction of randomly sampled rounds and demonstrate this attack on image classification, next-word prediction, and sentiment analysis.
Pre-Train Your Loss: Easy Bayesian Transfer Learning with Informative Priors
May 20, 2022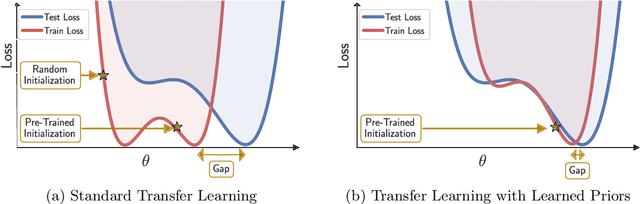

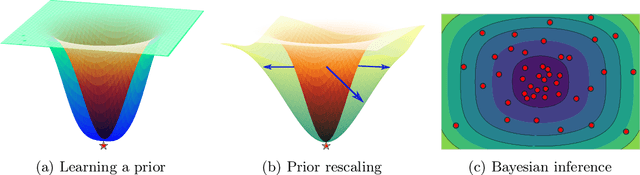
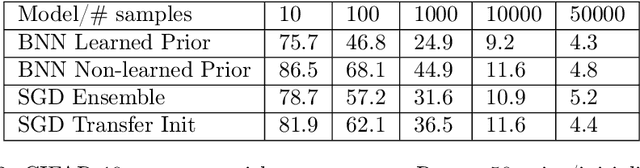
Deep learning is increasingly moving towards a transfer learning paradigm whereby large foundation models are fine-tuned on downstream tasks, starting from an initialization learned on the source task. But an initialization contains relatively little information about the source task. Instead, we show that we can learn highly informative posteriors from the source task, through supervised or self-supervised approaches, which then serve as the basis for priors that modify the whole loss surface on the downstream task. This simple modular approach enables significant performance gains and more data-efficient learning on a variety of downstream classification and segmentation tasks, serving as a drop-in replacement for standard pre-training strategies. These highly informative priors also can be saved for future use, similar to pre-trained weights, and stand in contrast to the zero-mean isotropic uninformative priors that are typically used in Bayesian deep learning.
A Deep Dive into Dataset Imbalance and Bias in Face Identification
Mar 15, 2022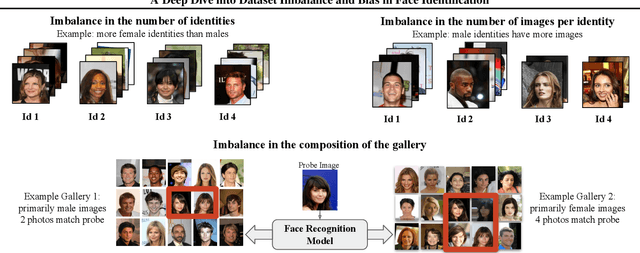



As the deployment of automated face recognition (FR) systems proliferates, bias in these systems is not just an academic question, but a matter of public concern. Media portrayals often center imbalance as the main source of bias, i.e., that FR models perform worse on images of non-white people or women because these demographic groups are underrepresented in training data. Recent academic research paints a more nuanced picture of this relationship. However, previous studies of data imbalance in FR have focused exclusively on the face verification setting, while the face identification setting has been largely ignored, despite being deployed in sensitive applications such as law enforcement. This is an unfortunate omission, as 'imbalance' is a more complex matter in identification; imbalance may arise in not only the training data, but also the testing data, and furthermore may affect the proportion of identities belonging to each demographic group or the number of images belonging to each identity. In this work, we address this gap in the research by thoroughly exploring the effects of each kind of imbalance possible in face identification, and discuss other factors which may impact bias in this setting.
Interpolated Joint Space Adversarial Training for Robust and Generalizable Defenses
Dec 12, 2021
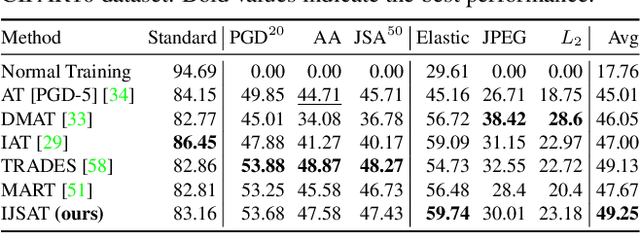
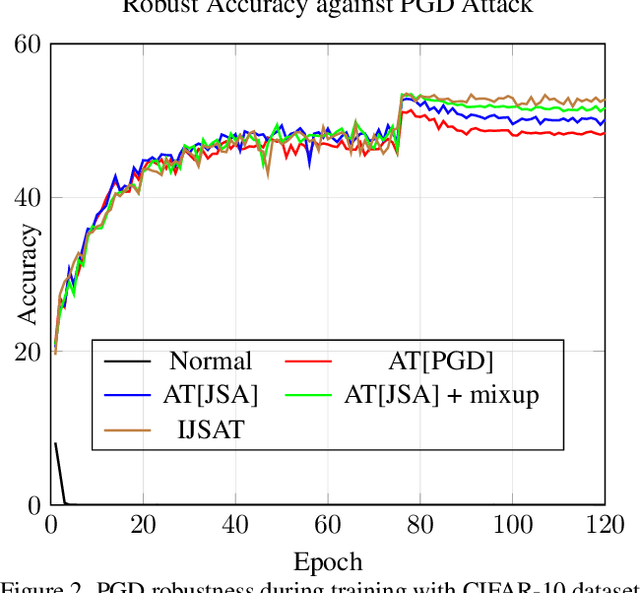
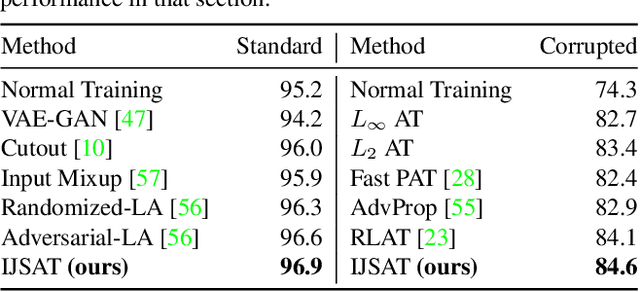
Adversarial training (AT) is considered to be one of the most reliable defenses against adversarial attacks. However, models trained with AT sacrifice standard accuracy and do not generalize well to novel attacks. Recent works show generalization improvement with adversarial samples under novel threat models such as on-manifold threat model or neural perceptual threat model. However, the former requires exact manifold information while the latter requires algorithm relaxation. Motivated by these considerations, we exploit the underlying manifold information with Normalizing Flow, ensuring that exact manifold assumption holds. Moreover, we propose a novel threat model called Joint Space Threat Model (JSTM), which can serve as a special case of the neural perceptual threat model that does not require additional relaxation to craft the corresponding adversarial attacks. Under JSTM, we develop novel adversarial attacks and defenses. The mixup strategy improves the standard accuracy of neural networks but sacrifices robustness when combined with AT. To tackle this issue, we propose the Robust Mixup strategy in which we maximize the adversity of the interpolated images and gain robustness and prevent overfitting. Our experiments show that Interpolated Joint Space Adversarial Training (IJSAT) achieves good performance in standard accuracy, robustness, and generalization in CIFAR-10/100, OM-ImageNet, and CIFAR-10-C datasets. IJSAT is also flexible and can be used as a data augmentation method to improve standard accuracy and combine with many existing AT approaches to improve robustness.
Mutual Adversarial Training: Learning together is better than going alone
Dec 09, 2021
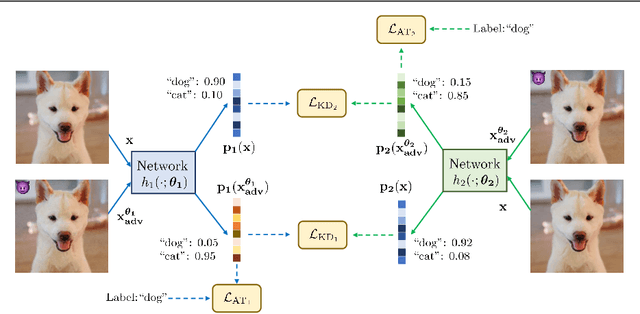

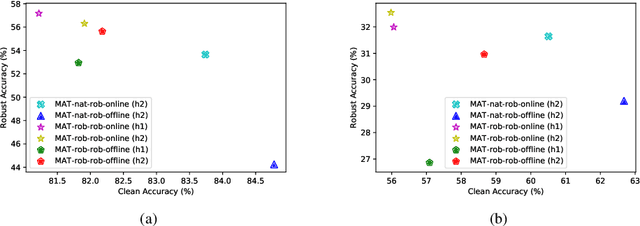
Recent studies have shown that robustness to adversarial attacks can be transferred across networks. In other words, we can make a weak model more robust with the help of a strong teacher model. We ask if instead of learning from a static teacher, can models "learn together" and "teach each other" to achieve better robustness? In this paper, we study how interactions among models affect robustness via knowledge distillation. We propose mutual adversarial training (MAT), in which multiple models are trained together and share the knowledge of adversarial examples to achieve improved robustness. MAT allows robust models to explore a larger space of adversarial samples, and find more robust feature spaces and decision boundaries. Through extensive experiments on CIFAR-10 and CIFAR-100, we demonstrate that MAT can effectively improve model robustness and outperform state-of-the-art methods under white-box attacks, bringing $\sim$8% accuracy gain to vanilla adversarial training (AT) under PGD-100 attacks. In addition, we show that MAT can also mitigate the robustness trade-off among different perturbation types, bringing as much as 13.1% accuracy gain to AT baselines against the union of $l_\infty$, $l_2$ and $l_1$ attacks. These results show the superiority of the proposed method and demonstrate that collaborative learning is an effective strategy for designing robust models.
Identification of Attack-Specific Signatures in Adversarial Examples
Oct 13, 2021

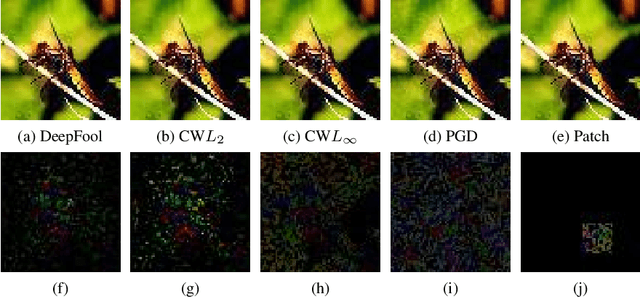
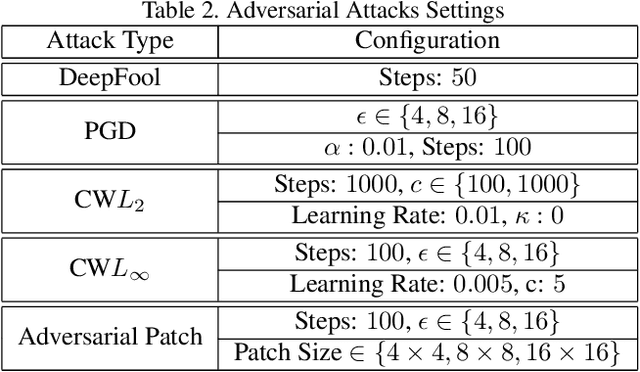
The adversarial attack literature contains a myriad of algorithms for crafting perturbations which yield pathological behavior in neural networks. In many cases, multiple algorithms target the same tasks and even enforce the same constraints. In this work, we show that different attack algorithms produce adversarial examples which are distinct not only in their effectiveness but also in how they qualitatively affect their victims. We begin by demonstrating that one can determine the attack algorithm that crafted an adversarial example. Then, we leverage recent advances in parameter-space saliency maps to show, both visually and quantitatively, that adversarial attack algorithms differ in which parts of the network and image they target. Our findings suggest that prospective adversarial attacks should be compared not only via their success rates at fooling models but also via deeper downstream effects they have on victims.