 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARGUS: Hallucination and Omission Evaluation in Video-LLMs
Jun 09, 2025Video large language models have not yet been widely deployed, largely due to their tendency to hallucinate. Typical benchmarks for Video-LLMs rely simply on multiple-choice questions. Unfortunately, VideoLLMs hallucinate far more aggressively on freeform text generation tasks like video captioning than they do on multiple choice verification tasks. To address this weakness, we propose ARGUS, a VideoLLM benchmark that measures freeform video captioning performance. By comparing VideoLLM outputs to human ground truth captions, ARGUS quantifies dual metrics. First, we measure the rate of hallucinations in the form of incorrect statements about video content or temporal relationships. Second, we measure the rate at which the model omits important descriptive details. Together, these dual metrics form a comprehensive view of video captioning performance.
Efficient Fine-Tuning and Concept Suppression for Pruned Diffusion Models
Dec 19, 2024



Recent advances in diffusion generative models have yielded remarkable progress. While the quality of generated content continues to improve, these models have grown considerably in size and complexity. This increasing computational burden poses significant challenges, particularly in resource-constrained deployment scenarios such as mobile devices. The combination of model pruning and knowledge distillation has emerged as a promising solution to reduce computational demands while preserving generation quality. However, this technique inadvertently propagates undesirable behaviors, including the generation of copyrighted content and unsafe concepts, even when such instances are absent from the fine-tuning dataset. In this paper, we propose a novel bilevel optimization framework for pruned diffusion models that consolidates the fine-tuning and unlearning processes into a unified phase. Our approach maintains the principal advantages of distillation-namely, efficient convergence and style transfer capabilities-while selectively suppressing the generation of unwanted content. This plug-in framework is compatible with various pruning and concept unlearning methods, facilitating efficient, safe deployment of diffusion models in controlled environments.
Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
Jun 14, 2024



Large language models can memorize and repeat their training data, causing privacy and copyright risks. To mitigate memorization, we introduce a subtle modification to the next-token training objective that we call the goldfish loss. During training, a randomly sampled subset of tokens are excluded from the loss computation. These dropped tokens are not memorized by the model, which prevents verbatim reproduction of a complete chain of tokens from the training set. We run extensive experiments training billion-scale Llama-2 models, both pre-trained and trained from scratch, and demonstrate significant reductions in extractable memorization with little to no impact on downstream benchmarks.
From Pixels to Prose: A Large Dataset of Dense Image Captions
Jun 14, 2024

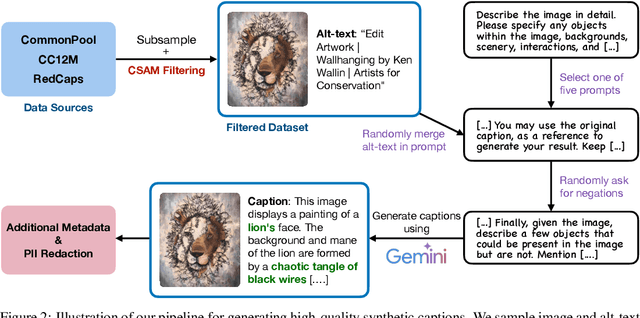
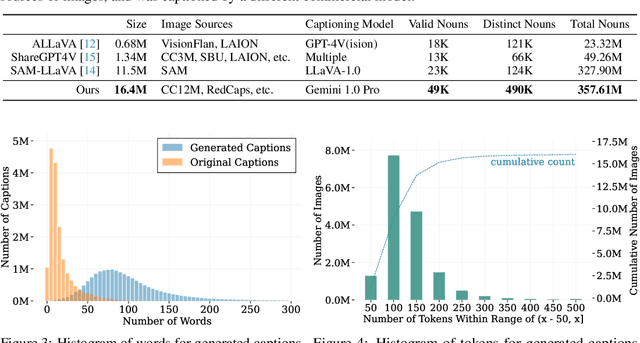
Training large vision-language models requires extensive, high-quality image-text pairs. Existing web-scraped datasets, however, are noisy and lack detailed image descriptions. To bridge this gap, we introduce PixelProse, a comprehensive dataset of over 16M (million) synthetically generated captions, leveraging cutting-edge vision-language models for detailed and accurate descriptions. To ensure data integrity, we rigorously analyze our dataset for problematic content, including child sexual abuse material (CSAM), personally identifiable information (PII), and toxicity. We also provide valuable metadata such as watermark presence and aesthetic scores, aiding in further dataset filtering. We hope PixelProse will be a valuable resource for future vision-language research. PixelProse is available at https://huggingface.co/datasets/tomg-group-umd/pixelprose
CinePile: A Long Video Question Answering Dataset and Benchmark
May 14, 2024



Current datasets for long-form video understanding often fall short of providing genuine long-form comprehension challenges, as many tasks derived from these datasets can be successfully tackled by analyzing just one or a few random frames from a video. To address this issue, we present a novel dataset and benchmark, CinePile, specifically designed for authentic long-form video understanding. This paper details our innovative approach for creating a question-answer dataset, utilizing advanced LLMs with human-in-the-loop and building upon human-generated raw data. Our comprehensive dataset comprises 305,000 multiple-choice questions (MCQs), covering various visual and multimodal aspects, including temporal comprehension, understanding human-object interactions, and reasoning about events or actions within a scene. Additionally, we evaluate recent video-centric LLMs, both open-source and proprietary, on the test split of our dataset. The findings reveal that even state-of-the-art video-centric LLMs significantly lag behind human performance in these tasks, highlighting the complexity and challenge inherent in video understanding. The dataset is available at https://hf.co/datasets/tomg-group-umd/cinepile
LMD3: Language Model Data Density Dependence
May 10, 2024



We develop a methodology for analyzing language model task performance at the individual example level based on training data density estimation. Experiments with paraphrasing as a controlled intervention on finetuning data demonstrate that increasing the support in the training distribution for specific test queries results in a measurable increase in density, which is also a significant predictor of the performance increase caused by the intervention. Experiments with pretraining data demonstrate that we can explain a significant fraction of the variance in model perplexity via density measurements. We conclude that our framework can provide statistical evidence of the dependence of a target model's predictions on subsets of its training data, and can more generally be used to characterize the support (or lack thereof) in the training data for a given test task.
Measuring Style Similarity in Diffusion Models
Apr 01, 2024



Generative models are now widely used by graphic designers and artists. Prior works have shown that these models remember and often replicate content from their training data during generation. Hence as their proliferation increases, it has become important to perform a database search to determine whether the properties of the image are attributable to specific training data, every time before a generated image is used for professional purposes. Existing tools for this purpose focus on retrieving images of similar semantic content. Meanwhile, many artists are concerned with style replication in text-to-image models. We present a framework for understanding and extracting style descriptors from images. Our framework comprises a new dataset curated using the insight that style is a subjective property of an image that captures complex yet meaningful interactions of factors including but not limited to colors, textures, shapes, etc. We also propose a method to extract style descriptors that can be used to attribute style of a generated image to the images used in the training dataset of a text-to-image model. We showcase promising results in various style retrieval tasks. We also quantitatively and qualitatively analyze style attribution and matching in the Stable Diffusion model. Code and artifacts are available at https://github.com/learn2phoenix/CSD.
Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks
Nov 20, 2023



Neural network based computer vision systems are typically built on a backbone, a pretrained or randomly initialized feature extractor. Several years ago, the default option was an ImageNet-trained convolutional neural network. However, the recent past has seen the emergence of countless backbones pretrained using various algorithms and datasets. While this abundance of choice has led to performance increases for a range of systems, it is difficult for practitioners to make informed decisions about which backbone to choose. Battle of the Backbones (BoB) makes this choice easier by benchmarking a diverse suite of pretrained models, including vision-language models, those trained via self-supervised learning, and the Stable Diffusion backbone, across a diverse set of computer vision tasks ranging from classification to object detection to OOD generalization and more. Furthermore, BoB sheds light on promising directions for the research community to advance computer vision by illuminating strengths and weakness of existing approaches through a comprehensive analysis conducted on more than 1500 training runs. While vision transformers (ViTs) and self-supervised learning (SSL) are increasingly popular, we find that convolutional neural networks pretrained in a supervised fashion on large training sets still perform best on most tasks among the models we consider. Moreover, in apples-to-apples comparisons on the same architectures and similarly sized pretraining datasets, we find that SSL backbones are highly competitive, indicating that future works should perform SSL pretraining with advanced architectures and larger pretraining datasets. We release the raw results of our experiments along with code that allows researchers to put their own backbones through the gauntlet here: https://github.com/hsouri/Battle-of-the-Backbones
A Performance-Driven Benchmark for Feature Selection in Tabular Deep Learning
Nov 10, 2023



Academic tabular benchmarks often contain small sets of curated features. In contrast, data scientists typically collect as many features as possible into their datasets, and even engineer new features from existing ones. To prevent overfitting in subsequent downstream modeling, practitioners commonly use automated feature selection methods that identify a reduced subset of informative features. Existing benchmarks for tabular feature selection consider classical downstream models, toy synthetic datasets, or do not evaluate feature selectors on the basis of downstream performance. Motivated by the increasing popularity of tabular deep learning, we construct a challenging feature selection benchmark evaluated on downstream neural networks including transformers, using real datasets and multiple methods for generating extraneous features. We also propose an input-gradient-based analogue of Lasso for neural networks that outperforms classical feature selection methods on challenging problems such as selecting from corrupted or second-order features.
NEFTune: Noisy Embeddings Improve Instruction Finetuning
Oct 10, 2023We show that language model finetuning can be improved, sometimes dramatically, with a simple augmentation. NEFTune adds noise to the embedding vectors during training. Standard finetuning of LLaMA-2-7B using Alpaca achieves 29.79% on AlpacaEval, which rises to 64.69% using noisy embeddings. NEFTune also improves over strong baselines on modern instruction datasets. Models trained with Evol-Instruct see a 10% improvement, with ShareGPT an 8% improvement, and with OpenPlatypus an 8% improvement. Even powerful models further refined with RLHF such as LLaMA-2-Chat benefit from additional training with NEFTune.