 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen AI Benchmarks Plateau: A Systematic Study of Benchmark Saturation
Feb 18, 2026Artificial Intelligence (AI) benchmarks play a central role in measuring progress in model development and guiding deployment decisions. However, many benchmarks quickly become saturated, meaning that they can no longer differentiate between the best-performing models, diminishing their long-term value. In this study, we analyze benchmark saturation across 60 Large Language Model (LLM) benchmarks selected from technical reports by major model developers. To identify factors driving saturation, we characterize benchmarks along 14 properties spanning task design, data construction, and evaluation format. We test five hypotheses examining how each property contributes to saturation rates. Our analysis reveals that nearly half of the benchmarks exhibit saturation, with rates increasing as benchmarks age. Notably, hiding test data (i.e., public vs. private) shows no protective effect, while expert-curated benchmarks resist saturation better than crowdsourced ones. Our findings highlight which design choices extend benchmark longevity and inform strategies for more durable evaluation.
ARGUS: Hallucination and Omission Evaluation in Video-LLMs
Jun 09, 2025Video large language models have not yet been widely deployed, largely due to their tendency to hallucinate. Typical benchmarks for Video-LLMs rely simply on multiple-choice questions. Unfortunately, VideoLLMs hallucinate far more aggressively on freeform text generation tasks like video captioning than they do on multiple choice verification tasks. To address this weakness, we propose ARGUS, a VideoLLM benchmark that measures freeform video captioning performance. By comparing VideoLLM outputs to human ground truth captions, ARGUS quantifies dual metrics. First, we measure the rate of hallucinations in the form of incorrect statements about video content or temporal relationships. Second, we measure the rate at which the model omits important descriptive details. Together, these dual metrics form a comprehensive view of video captioning performance.
CinePile: A Long Video Question Answering Dataset and Benchmark
May 14, 2024



Current datasets for long-form video understanding often fall short of providing genuine long-form comprehension challenges, as many tasks derived from these datasets can be successfully tackled by analyzing just one or a few random frames from a video. To address this issue, we present a novel dataset and benchmark, CinePile, specifically designed for authentic long-form video understanding. This paper details our innovative approach for creating a question-answer dataset, utilizing advanced LLMs with human-in-the-loop and building upon human-generated raw data. Our comprehensive dataset comprises 305,000 multiple-choice questions (MCQs), covering various visual and multimodal aspects, including temporal comprehension, understanding human-object interactions, and reasoning about events or actions within a scene. Additionally, we evaluate recent video-centric LLMs, both open-source and proprietary, on the test split of our dataset. The findings reveal that even state-of-the-art video-centric LLMs significantly lag behind human performance in these tasks, highlighting the complexity and challenge inherent in video understanding. The dataset is available at https://hf.co/datasets/tomg-group-umd/cinepile
Perturbed examples reveal invariances shared by language models
Nov 07, 2023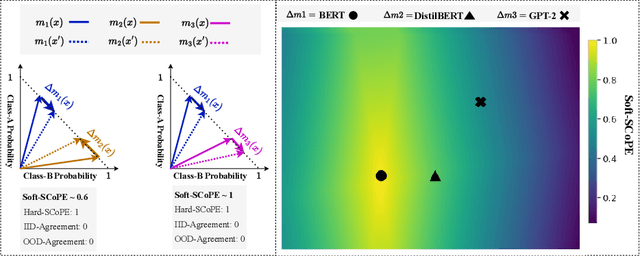
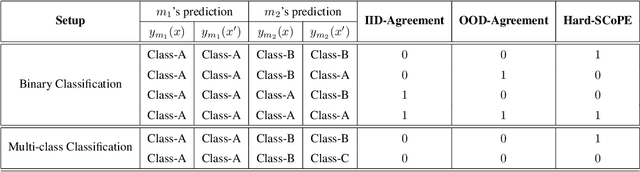
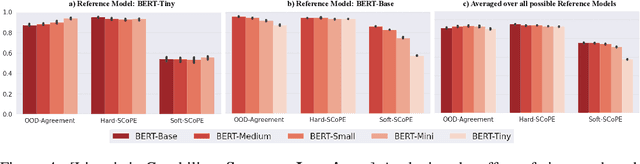
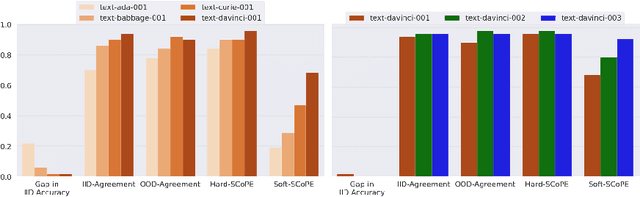
An explosion of work in language is leading to ever-increasing numbers of available natural language processing models, with little understanding of how new models compare to better-understood models. One major reason for this difficulty is saturating benchmark datasets, which may not reflect well differences in model performance in the wild. In this work, we propose a novel framework for comparing two natural language processing models by revealing their shared invariance to interpretable input perturbations that are designed to target a specific linguistic capability (e.g., Synonym-Invariance, Typo-Invariance). Via experiments on models from within the same and across different architecture families, this framework offers a number of insights about how changes in models (e.g., distillation, increase in size, amount of pre-training) affect multiple well-defined linguistic capabilities. Furthermore, we also demonstrate how our framework can enable evaluation of the invariances shared between models that are available as commercial black-box APIs (e.g., InstructGPT family) and models that are relatively better understood (e.g., GPT-2). Across several experiments, we observe that large language models share many of the invariances encoded by models of various sizes, whereas the invariances encoded by large language models are only shared by other large models. Possessing a wide variety of invariances may be a key reason for the recent successes of large language models, and our framework can shed light on the types of invariances that are retained by or emerge in new models.
DAD++: Improved Data-free Test Time Adversarial Defense
Sep 10, 2023With the increasing deployment of deep neural networks in safety-critical applications such as self-driving cars, medical imaging, anomaly detection, etc., adversarial robustness has become a crucial concern in the reliability of these networks in real-world scenarios. A plethora of works based on adversarial training and regularization-based techniques have been proposed to make these deep networks robust against adversarial attacks. However, these methods require either retraining models or training them from scratch, making them infeasible to defend pre-trained models when access to training data is restricted. To address this problem, we propose a test time Data-free Adversarial Defense (DAD) containing detection and correction frameworks. Moreover, to further improve the efficacy of the correction framework in cases when the detector is under-confident, we propose a soft-detection scheme (dubbed as "DAD++"). We conduct a wide range of experiments and ablations on several datasets and network architectures to show the efficacy of our proposed approach. Furthermore, we demonstrate the applicability of our approach in imparting adversarial defense at test time under data-free (or data-efficient) applications/setups, such as Data-free Knowledge Distillation and Source-free Unsupervised Domain Adaptation, as well as Semi-supervised classification frameworks. We observe that in all the experiments and applications, our DAD++ gives an impressive performance against various adversarial attacks with a minimal drop in clean accuracy. The source code is available at: https://github.com/vcl-iisc/Improved-Data-free-Test-Time-Adversarial-Defense
What Happens During Finetuning of Vision Transformers: An Invariance Based Investigation
Jul 12, 2023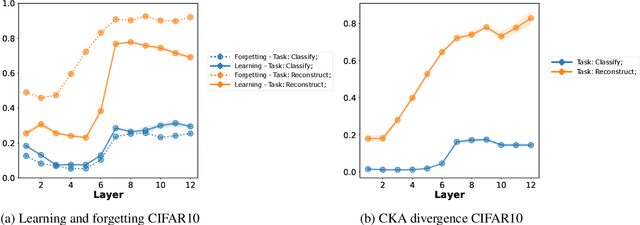
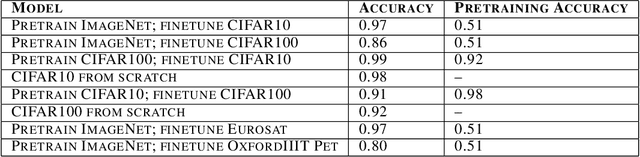
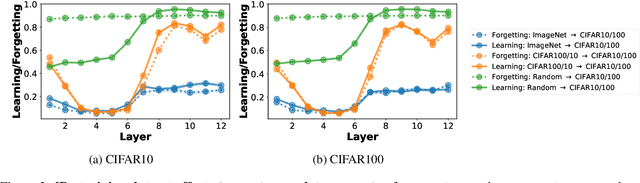
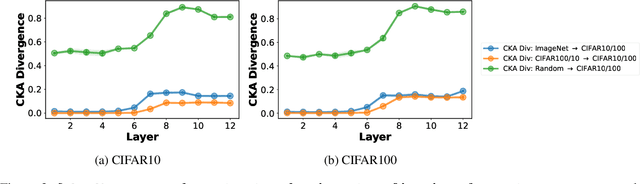
The pretrain-finetune paradigm usually improves downstream performance over training a model from scratch on the same task, becoming commonplace across many areas of machine learning. While pretraining is empirically observed to be beneficial for a range of tasks, there is not a clear understanding yet of the reasons for this effect. In this work, we examine the relationship between pretrained vision transformers and the corresponding finetuned versions on several benchmark datasets and tasks. We present new metrics that specifically investigate the degree to which invariances learned by a pretrained model are retained or forgotten during finetuning. Using these metrics, we present a suite of empirical findings, including that pretraining induces transferable invariances in shallow layers and that invariances from deeper pretrained layers are compressed towards shallower layers during finetuning. Together, these findings contribute to understanding some of the reasons for the successes of pretrained models and the changes that a pretrained model undergoes when finetuned on a downstream task.
Robust Few-shot Learning Without Using any Adversarial Samples
Nov 03, 2022The high cost of acquiring and annotating samples has made the `few-shot' learning problem of prime importance. Existing works mainly focus on improving performance on clean data and overlook robustness concerns on the data perturbed with adversarial noise. Recently, a few efforts have been made to combine the few-shot problem with the robustness objective using sophisticated Meta-Learning techniques. These methods rely on the generation of adversarial samples in every episode of training, which further adds a computational burden. To avoid such time-consuming and complicated procedures, we propose a simple but effective alternative that does not require any adversarial samples. Inspired by the cognitive decision-making process in humans, we enforce high-level feature matching between the base class data and their corresponding low-frequency samples in the pretraining stage via self distillation. The model is then fine-tuned on the samples of novel classes where we additionally improve the discriminability of low-frequency query set features via cosine similarity. On a 1-shot setting of the CIFAR-FS dataset, our method yields a massive improvement of $60.55\%$ & $62.05\%$ in adversarial accuracy on the PGD and state-of-the-art Auto Attack, respectively, with a minor drop in clean accuracy compared to the baseline. Moreover, our method only takes $1.69\times$ of the standard training time while being $\approx$ $5\times$ faster than state-of-the-art adversarial meta-learning methods. The code is available at https://github.com/vcl-iisc/robust-few-shot-learning.
Data-free Defense of Black Box Models Against Adversarial Attacks
Nov 03, 2022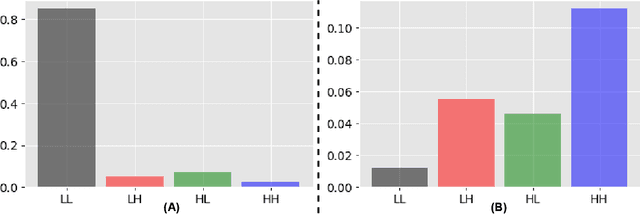


Several companies often safeguard their trained deep models (i.e. details of architecture, learnt weights, training details etc.) from third-party users by exposing them only as black boxes through APIs. Moreover, they may not even provide access to the training data due to proprietary reasons or sensitivity concerns. We make the first attempt to provide adversarial robustness to the black box models in a data-free set up. We construct synthetic data via generative model and train surrogate network using model stealing techniques. To minimize adversarial contamination on perturbed samples, we propose `wavelet noise remover' (WNR) that performs discrete wavelet decomposition on input images and carefully select only a few important coefficients determined by our `wavelet coefficient selection module' (WCSM). To recover the high-frequency content of the image after noise removal via WNR, we further train a `regenerator' network with an objective to retrieve the coefficients such that the reconstructed image yields similar to original predictions on the surrogate model. At test time, WNR combined with trained regenerator network is prepended to the black box network, resulting in a high boost in adversarial accuracy. Our method improves the adversarial accuracy on CIFAR-10 by 38.98% and 32.01% on state-of-the-art Auto Attack compared to baseline, even when the attacker uses surrogate architecture (Alexnet-half and Alexnet) similar to the black box architecture (Alexnet) with same model stealing strategy as defender. The code is available at https://github.com/vcl-iisc/data-free-black-box-defense
DE-CROP: Data-efficient Certified Robustness for Pretrained Classifiers
Oct 17, 2022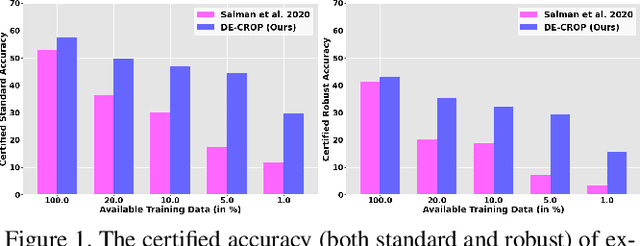
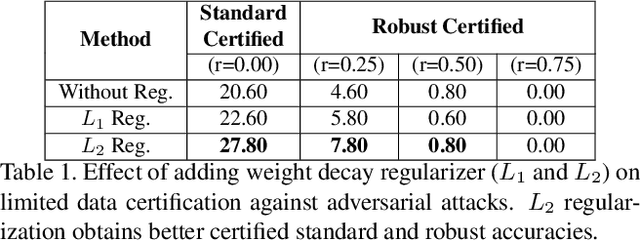
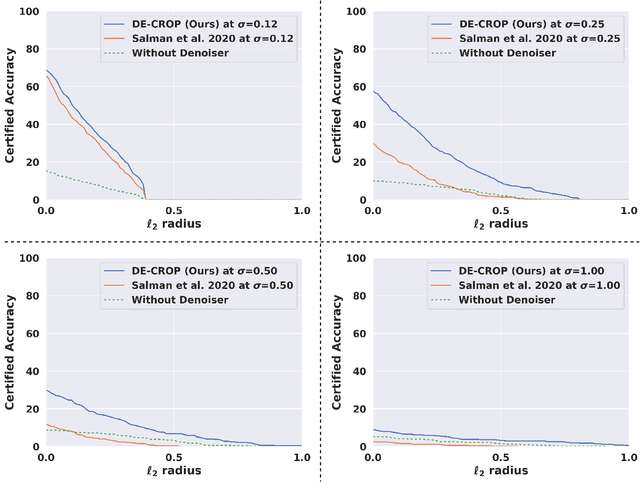
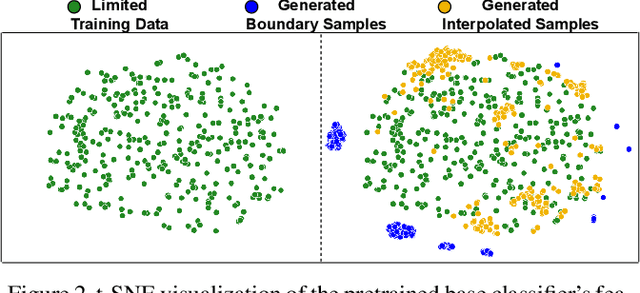
Certified defense using randomized smoothing is a popular technique to provide robustness guarantees for deep neural networks against l2 adversarial attacks. Existing works use this technique to provably secure a pretrained non-robust model by training a custom denoiser network on entire training data. However, access to the training set may be restricted to a handful of data samples due to constraints such as high transmission cost and the proprietary nature of the data. Thus, we formulate a novel problem of "how to certify the robustness of pretrained models using only a few training samples". We observe that training the custom denoiser directly using the existing techniques on limited samples yields poor certification. To overcome this, our proposed approach (DE-CROP) generates class-boundary and interpolated samples corresponding to each training sample, ensuring high diversity in the feature space of the pretrained classifier. We train the denoiser by maximizing the similarity between the denoised output of the generated sample and the original training sample in the classifier's logit space. We also perform distribution level matching using domain discriminator and maximum mean discrepancy that yields further benefit. In white box setup, we obtain significant improvements over the baseline on multiple benchmark datasets and also report similar performance under the challenging black box setup.
Holistic Approach to Measure Sample-level Adversarial Vulnerability and its Utility in Building Trustworthy Systems
May 05, 2022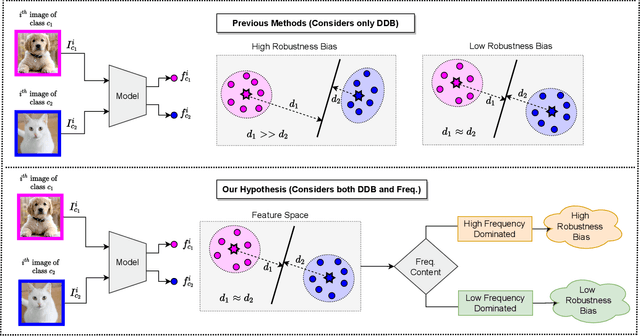
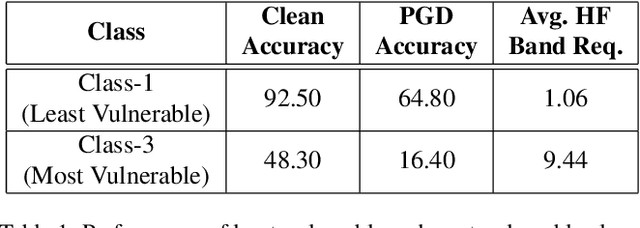

Adversarial attack perturbs an image with an imperceptible noise, leading to incorrect model prediction. Recently, a few works showed inherent bias associated with such attack (robustness bias), where certain subgroups in a dataset (e.g. based on class, gender, etc.) are less robust than others. This bias not only persists even after adversarial training, but often results in severe performance discrepancies across these subgroups. Existing works characterize the subgroup's robustness bias by only checking individual sample's proximity to the decision boundary. In this work, we argue that this measure alone is not sufficient and validate our argument via extensive experimental analysis. It has been observed that adversarial attacks often corrupt the high-frequency components of the input image. We, therefore, propose a holistic approach for quantifying adversarial vulnerability of a sample by combining these different perspectives, i.e., degree of model's reliance on high-frequency features and the (conventional) sample-distance to the decision boundary. We demonstrate that by reliably estimating adversarial vulnerability at the sample level using the proposed holistic metric, it is possible to develop a trustworthy system where humans can be alerted about the incoming samples that are highly likely to be misclassified at test time. This is achieved with better precision when our holistic metric is used over individual measures. To further corroborate the utility of the proposed holistic approach, we perform knowledge distillation in a limited-sample setting. We observe that the student network trained with the subset of samples selected using our combined metric performs better than both the competing baselines, viz., where samples are selected randomly or based on their distances to the decision boundary.