 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Happens During Finetuning of Vision Transformers: An Invariance Based Investigation
Jul 12, 2023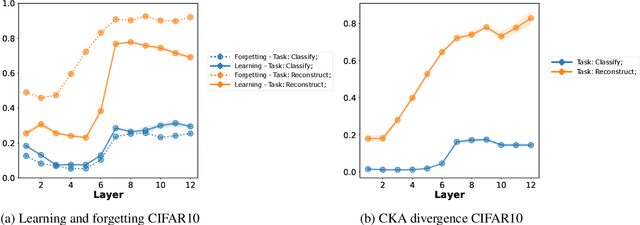
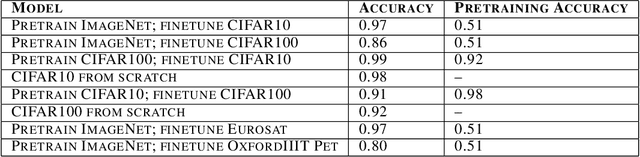
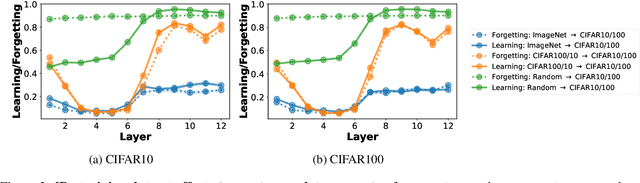
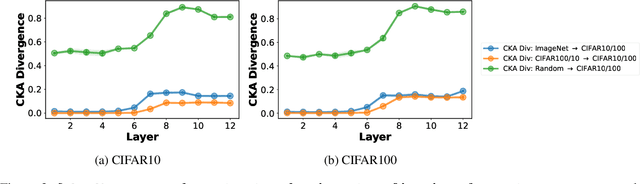
The pretrain-finetune paradigm usually improves downstream performance over training a model from scratch on the same task, becoming commonplace across many areas of machine learning. While pretraining is empirically observed to be beneficial for a range of tasks, there is not a clear understanding yet of the reasons for this effect. In this work, we examine the relationship between pretrained vision transformers and the corresponding finetuned versions on several benchmark datasets and tasks. We present new metrics that specifically investigate the degree to which invariances learned by a pretrained model are retained or forgotten during finetuning. Using these metrics, we present a suite of empirical findings, including that pretraining induces transferable invariances in shallow layers and that invariances from deeper pretrained layers are compressed towards shallower layers during finetuning. Together, these findings contribute to understanding some of the reasons for the successes of pretrained models and the changes that a pretrained model undergoes when finetuned on a downstream task.
Language models and brain alignment: beyond word-level semantics and prediction
Dec 01, 2022Pretrained language models that have been trained to predict the next word over billions of text documents have been shown to also significantly predict brain recordings of people comprehending language. Understanding the reasons behind the observed similarities between language in machines and language in the brain can lead to more insight into both systems. Recent works suggest that the prediction of the next word is a key mechanism that contributes to the alignment between the two. What is not yet understood is whether prediction of the next word is necessary for this observed alignment or simply sufficient, and whether there are other shared mechanisms or information that is similarly important. In this work, we take a first step towards a better understanding via two simple perturbations in a popular pretrained language model. The first perturbation is to improve the model's ability to predict the next word in the specific naturalistic stimulus text that the brain recordings correspond to. We show that this indeed improves the alignment with the brain recordings. However, this improved alignment may also be due to any improved word-level or multi-word level semantics for the specific world that is described by the stimulus narrative. We aim to disentangle the contribution of next word prediction and semantic knowledge via our second perturbation: scrambling the word order at inference time, which reduces the ability to predict the next word, but maintains any newly learned word-level semantics. By comparing the alignment with brain recordings of these differently perturbed models, we show that improvements in alignment with brain recordings are due to more than improvements in next word prediction and word-level semantics.
Practical Recommendations for Replay-based Continual Learning Methods
Mar 19, 2022
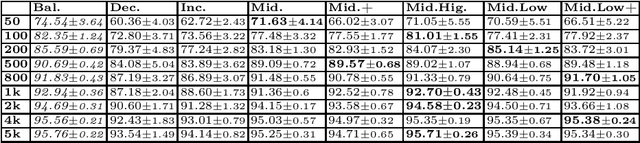
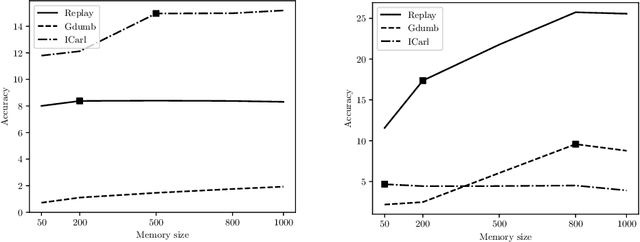

Continual Learning requires the model to learn from a stream of dynamic, non-stationary data without forgetting previous knowledge. Several approaches have been developed in the literature to tackle the Continual Learning challenge. Among them, Replay approaches have empirically proved to be the most effective ones. Replay operates by saving some samples in memory which are then used to rehearse knowledge during training in subsequent tasks. However, an extensive comparison and deeper understanding of different replay implementation subtleties is still missing in the literature. The aim of this work is to compare and analyze existing replay-based strategies and provide practical recommendations on developing efficient, effective and generally applicable replay-based strategies. In particular, we investigate the role of the memory size value, different weighting policies and discuss about the impact of data augmentation, which allows reaching better performance with lower memory sizes.