 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Happens During Finetuning of Vision Transformers: An Invariance Based Investigation
Paper and Code
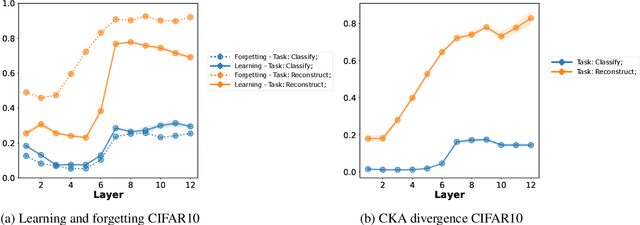
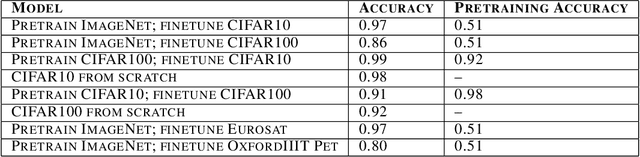
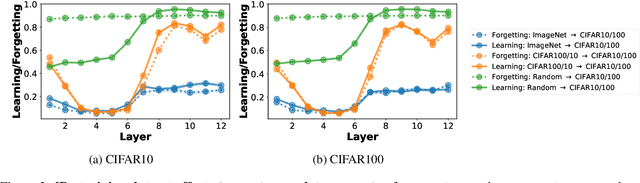
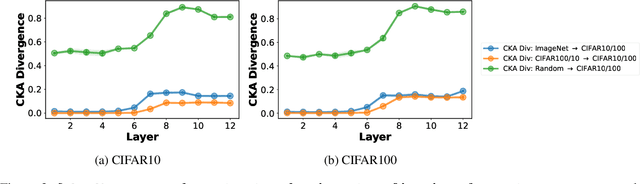
The pretrain-finetune paradigm usually improves downstream performance over training a model from scratch on the same task, becoming commonplace across many areas of machine learning. While pretraining is empirically observed to be beneficial for a range of tasks, there is not a clear understanding yet of the reasons for this effect. In this work, we examine the relationship between pretrained vision transformers and the corresponding finetuned versions on several benchmark datasets and tasks. We present new metrics that specifically investigate the degree to which invariances learned by a pretrained model are retained or forgotten during finetuning. Using these metrics, we present a suite of empirical findings, including that pretraining induces transferable invariances in shallow layers and that invariances from deeper pretrained layers are compressed towards shallower layers during finetuning. Together, these findings contribute to understanding some of the reasons for the successes of pretrained models and the changes that a pretrained model undergoes when finetuned on a downstream task.