 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBMD-45: A Large-Scale CCTV Vehicle Detection Dataset for Urban Traffic in Developing Cities
Apr 27, 2026Robust vehicle detection from fixed CCTV cameras is critical for Intelligent Transportation Systems. Yet existing benchmarks predominantly feature relatively homogeneous, highly organized traffic patterns captured from ego-centric driving perspectives or controlled aerial views. This regional and sensor view bias creates a significant gap. Models trained on datasets such as UA-DETRAC and COCO struggle to generalize to the dense, heterogeneous, disorganized traffic conditions observed in rapidly developing urban centers in emerging economies. To address this limitation, we introduce BMD-45, a large-scale dataset comprising 480K bounding boxes annotated over 45K images captured from over 3.6K operational Safe City CCTV cameras. BMD-45 contains 14 fine-grained vehicle categories, including region-specific modes such as auto-rickshaws and tempo travellers, which are not present in existing benchmarks. The dataset captures real-world deployment challenges, including extreme viewpoint variation, occlusion, and vehicle density . We establish comprehensive baselines using state-of-the-art detectors and reveal a striking domain gap: models fine-tuned on UA-DETRAC achieve only 33.6% mAP@0.50:0.95, compared to 83.8% when trained in-domain on BMD-45, representing a 2.5x improvement that persists even when accounting for novel vehicle classes. This performance gap underscores the critical need for geographically diverse traffic benchmarks and establishes BMD-45 as a baseline for developing robust perception systems in underrepresented urban environments worldwide. The dataset is available at: https://huggingface.co/datasets/iisc-aim/BMD-45.
LLM Essay Scoring Under Holistic and Analytic Rubrics: Prompt Effects and Bias
Mar 31, 2026Despite growing interest in using Large Language Models (LLMs) for educational assessment, it remains unclear how closely they align with human scoring. We present a systematic evaluation of instruction-tuned LLMs across three open essay-scoring datasets (ASAP 2.0, ELLIPSE, and DREsS) that cover both holistic and analytic scoring. We analyze agreement with human consensus scores, directional bias, and the stability of bias estimates. Our results show that strong open-weight models achieve moderate to high agreement with humans on holistic scoring (Quadratic Weighted Kappa about 0.6), but this does not transfer uniformly to analytic scoring. In particular, we observe large and stable negative directional bias on Lower-Order Concern (LOC) traits, such as Grammar and Conventions, meaning that models often score these traits more harshly than human raters. We also find that concise keyword-based prompts generally outperform longer rubric-style prompts in multi-trait analytic scoring. To quantify the amount of data needed to detect these systematic deviations, we compute the minimum sample size at which a 95% bootstrap confidence interval for the mean bias excludes zero. This analysis shows that LOC bias is often detectable with very small validation sets, whereas Higher-Order Concern (HOC) traits typically require much larger samples. These findings support a bias-correction-first deployment strategy: instead of relying on raw zero-shot scores, systematic score offsets can be estimated and corrected using small human-labeled bias-estimation sets, without requiring large-scale fine-tuning.
Minimizing Layerwise Activation Norm Improves Generalization in Federated Learning
Dec 09, 2025Federated Learning (FL) is an emerging machine learning framework that enables multiple clients (coordinated by a server) to collaboratively train a global model by aggregating the locally trained models without sharing any client's training data. It has been observed in recent works that learning in a federated manner may lead the aggregated global model to converge to a 'sharp minimum' thereby adversely affecting the generalizability of this FL-trained model. Therefore, in this work, we aim to improve the generalization performance of models trained in a federated setup by introducing a 'flatness' constrained FL optimization problem. This flatness constraint is imposed on the top eigenvalue of the Hessian computed from the training loss. As each client trains a model on its local data, we further re-formulate this complex problem utilizing the client loss functions and propose a new computationally efficient regularization technique, dubbed 'MAN,' which Minimizes Activation's Norm of each layer on client-side models. We also theoretically show that minimizing the activation norm reduces the top eigenvalue of the layer-wise Hessian of the client's loss, which in turn decreases the overall Hessian's top eigenvalue, ensuring convergence to a flat minimum. We apply our proposed flatness-constrained optimization to the existing FL techniques and obtain significant improvements, thereby establishing new state-of-the-art.
O3SLM: Open Weight, Open Data, and Open Vocabulary Sketch-Language Model
Nov 18, 2025While Large Vision Language Models (LVLMs) are increasingly deployed in real-world applications, their ability to interpret abstract visual inputs remains limited. Specifically, they struggle to comprehend hand-drawn sketches, a modality that offers an intuitive means of expressing concepts that are difficult to describe textually. We identify the primary bottleneck as the absence of a large-scale dataset that jointly models sketches, photorealistic images, and corresponding natural language instructions. To address this, we present two key contributions: (1) a new, large-scale dataset of image-sketch-instruction triplets designed to facilitate both pretraining and instruction tuning, and (2) O3SLM, an LVLM trained on this dataset. Comprehensive evaluations on multiple sketch-based tasks: (a) object localization, (b) counting, (c) image retrieval i.e., (SBIR and fine-grained SBIR), and (d) visual question answering (VQA); while incorporating the three existing sketch datasets, namely QuickDraw!, Sketchy, and Tu Berlin, along with our generated SketchVCL dataset, show that O3SLM achieves state-of-the-art performance, substantially outperforming existing LVLMs in sketch comprehension and reasoning.
Optimizing Federated Learning for Scalable Power-demand Forecasting in Microgrids
Aug 11, 2025Real-time monitoring of power consumption in cities and micro-grids through the Internet of Things (IoT) can help forecast future demand and optimize grid operations. But moving all consumer-level usage data to the cloud for predictions and analysis at fine time scales can expose activity patterns. Federated Learning~(FL) is a privacy-sensitive collaborative DNN training approach that retains data on edge devices, trains the models on private data locally, and aggregates the local models in the cloud. But key challenges exist: (i) clients can have non-independently identically distributed~(non-IID) data, and (ii) the learning should be computationally cheap while scaling to 1000s of (unseen) clients. In this paper, we develop and evaluate several optimizations to FL training across edge and cloud for time-series demand forecasting in micro-grids and city-scale utilities using DNNs to achieve a high prediction accuracy while minimizing the training cost. We showcase the benefit of using exponentially weighted loss while training and show that it further improves the prediction of the final model. Finally, we evaluate these strategies by validating over 1000s of clients for three states in the US from the OpenEIA corpus, and performing FL both in a pseudo-distributed setting and a Pi edge cluster. The results highlight the benefits of the proposed methods over baselines like ARIMA and DNNs trained for individual consumers, which are not scalable.
Pose-Transformation and Radial Distance Clustering for Unsupervised Person Re-identification
Nov 06, 2024


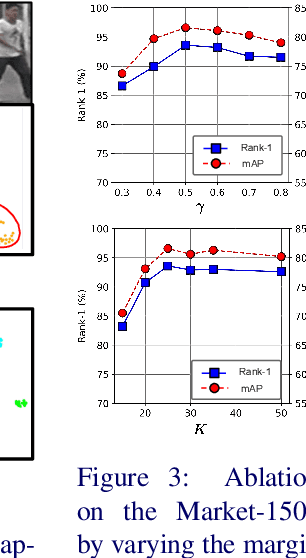
Person re-identification (re-ID) aims to tackle the problem of matching identities across non-overlapping cameras. Supervised approaches require identity information that may be difficult to obtain and are inherently biased towards the dataset they are trained on, making them unscalable across domains. To overcome these challenges, we propose an unsupervised approach to the person re-ID setup. Having zero knowledge of true labels, our proposed method enhances the discriminating ability of the learned features via a novel two-stage training strategy. The first stage involves training a deep network on an expertly designed pose-transformed dataset obtained by generating multiple perturbations for each original image in the pose space. Next, the network learns to map similar features closer in the feature space using the proposed discriminative clustering algorithm. We introduce a novel radial distance loss, that attends to the fundamental aspects of feature learning - compact clusters with low intra-cluster and high inter-cluster variation. Extensive experiments on several large-scale re-ID datasets demonstrate the superiority of our method compared to state-of-the-art approaches.
Learning non-Gaussian spatial distributions via Bayesian transport maps with parametric shrinkage
Sep 28, 2024Many applications, including climate-model analysis and stochastic weather generators, require learning or emulating the distribution of a high-dimensional and non-Gaussian spatial field based on relatively few training samples. To address this challenge, a recently proposed Bayesian transport map (BTM) approach consists of a triangular transport map with nonparametric Gaussian-process (GP) components, which is trained to transform the distribution of interest distribution to a Gaussian reference distribution. To improve the performance of this existing BTM, we propose to shrink the map components toward a ``base'' parametric Gaussian family combined with a Vecchia approximation for scalability. The resulting ShrinkTM approach is more accurate than the existing BTM, especially for small numbers of training samples. It can even outperform the ``base'' family when trained on a single sample of the spatial field. We demonstrate the advantage of ShrinkTM though numerical experiments on simulated data and on climate-model output.
Improving Domain Adaptation Through Class Aware Frequency Transformation
Jul 28, 2024In this work, we explore the usage of the Frequency Transformation for reducing the domain shift between the source and target domain (e.g., synthetic image and real image respectively) towards solving the Domain Adaptation task. Most of the Unsupervised Domain Adaptation (UDA) algorithms focus on reducing the global domain shift between labelled source and unlabelled target domains by matching the marginal distributions under a small domain gap assumption. UDA performance degrades for the cases where the domain gap between source and target distribution is large. In order to bring the source and the target domains closer, we propose a novel approach based on traditional image processing technique Class Aware Frequency Transformation (CAFT) that utilizes pseudo label based class consistent low-frequency swapping for improving the overall performance of the existing UDA algorithms. The proposed approach, when compared with the state-of-the-art deep learning based methods, is computationally more efficient and can easily be plugged into any existing UDA algorithm to improve its performance. Additionally, we introduce a novel approach based on absolute difference of top-2 class prediction probabilities (ADT2P) for filtering target pseudo labels into clean and noisy sets. Samples with clean pseudo labels can be used to improve the performance of unsupervised learning algorithms. We name the overall framework as CAFT++. We evaluate the same on the top of different UDA algorithms across many public domain adaptation datasets. Our extensive experiments indicate that CAFT++ is able to achieve significant performance gains across all the popular benchmarks.
Sketch-guided Image Inpainting with Partial Discrete Diffusion Process
Apr 18, 2024In this work, we study the task of sketch-guided image inpainting. Unlike the well-explored natural language-guided image inpainting, which excels in capturing semantic details, the relatively less-studied sketch-guided inpainting offers greater user control in specifying the object's shape and pose to be inpainted. As one of the early solutions to this task, we introduce a novel partial discrete diffusion process (PDDP). The forward pass of the PDDP corrupts the masked regions of the image and the backward pass reconstructs these masked regions conditioned on hand-drawn sketches using our proposed sketch-guided bi-directional transformer. The proposed novel transformer module accepts two inputs -- the image containing the masked region to be inpainted and the query sketch to model the reverse diffusion process. This strategy effectively addresses the domain gap between sketches and natural images, thereby, enhancing the quality of inpainting results. In the absence of a large-scale dataset specific to this task, we synthesize a dataset from the MS-COCO to train and extensively evaluate our proposed framework against various competent approaches in the literature. The qualitative and quantitative results and user studies establish that the proposed method inpaints realistic objects that fit the context in terms of the visual appearance of the provided sketch. To aid further research, we have made our code publicly available at https://github.com/vl2g/Sketch-Inpainting .
Scalable Model-Based Gaussian Process Clustering
Sep 14, 2023


Gaussian process is an indispensable tool in clustering functional data, owing to it's flexibility and inherent uncertainty quantification. However, when the functional data is observed over a large grid (say, of length $p$), Gaussian process clustering quickly renders itself infeasible, incurring $O(p^2)$ space complexity and $O(p^3)$ time complexity per iteration; and thus prohibiting it's natural adaptation to large environmental applications. To ensure scalability of Gaussian process clustering in such applications, we propose to embed the popular Vecchia approximation for Gaussian processes at the heart of the clustering task, provide crucial theoretical insights towards algorithmic design, and finally develop a computationally efficient expectation maximization (EM) algorithm. Empirical evidence of the utility of our proposal is provided via simulations and analysis of polar temperature anomaly (\href{https://www.ncei.noaa.gov/access/monitoring/climate-at-a-glance/global/time-series}{noaa.gov}) data-sets.