 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Transformation and Radial Distance Clustering for Unsupervised Person Re-identification
Nov 06, 2024


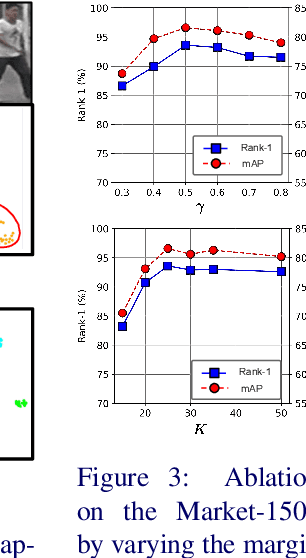
Person re-identification (re-ID) aims to tackle the problem of matching identities across non-overlapping cameras. Supervised approaches require identity information that may be difficult to obtain and are inherently biased towards the dataset they are trained on, making them unscalable across domains. To overcome these challenges, we propose an unsupervised approach to the person re-ID setup. Having zero knowledge of true labels, our proposed method enhances the discriminating ability of the learned features via a novel two-stage training strategy. The first stage involves training a deep network on an expertly designed pose-transformed dataset obtained by generating multiple perturbations for each original image in the pose space. Next, the network learns to map similar features closer in the feature space using the proposed discriminative clustering algorithm. We introduce a novel radial distance loss, that attends to the fundamental aspects of feature learning - compact clusters with low intra-cluster and high inter-cluster variation. Extensive experiments on several large-scale re-ID datasets demonstrate the superiority of our method compared to state-of-the-art approaches.
PocoLoco: A Point Cloud Diffusion Model of Human Shape in Loose Clothing
Nov 06, 2024
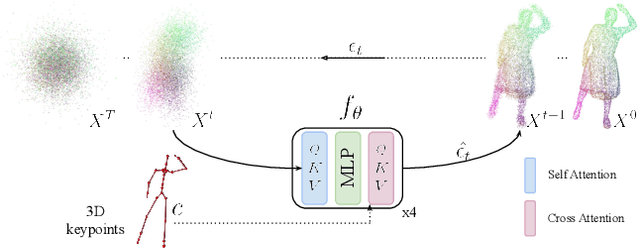
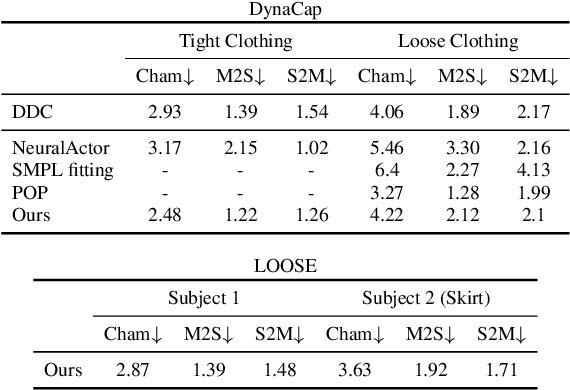
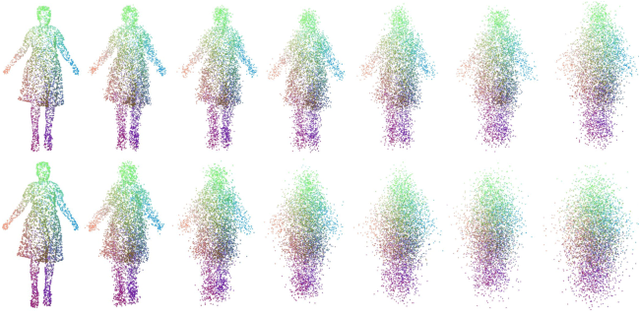
Modeling a human avatar that can plausibly deform to articulations is an active area of research. We present PocoLoco -- the first template-free, point-based, pose-conditioned generative model for 3D humans in loose clothing. We motivate our work by noting that most methods require a parametric model of the human body to ground pose-dependent deformations. Consequently, they are restricted to modeling clothing that is topologically similar to the naked body and do not extend well to loose clothing. The few methods that attempt to model loose clothing typically require either canonicalization or a UV-parameterization and need to address the challenging problem of explicitly estimating correspondences for the deforming clothes. In this work, we formulate avatar clothing deformation as a conditional point-cloud generation task within the denoising diffusion framework. Crucially, our framework operates directly on unordered point clouds, eliminating the need for a parametric model or a clothing template. This also enables a variety of practical applications, such as point-cloud completion and pose-based editing -- important features for virtual human animation. As current datasets for human avatars in loose clothing are far too small for training diffusion models, we release a dataset of two subjects performing various poses in loose clothing with a total of 75K point clouds. By contributing towards tackling the challenging task of effectively modeling loose clothing and expanding the available data for training these models, we aim to set the stage for further innovation in digital humans. The source code is available at https://github.com/sidsunny/pocoloco .
Non-Local Latent Relation Distillation for Self-Adaptive 3D Human Pose Estimation
Apr 06, 2022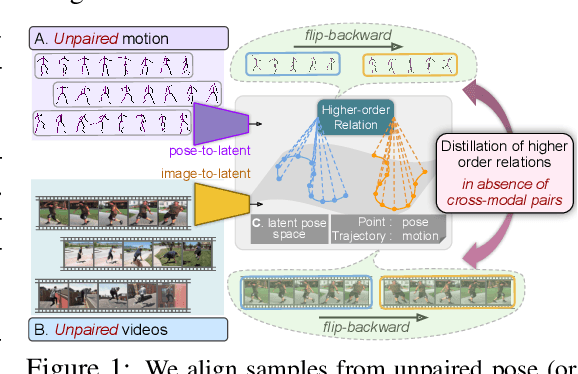
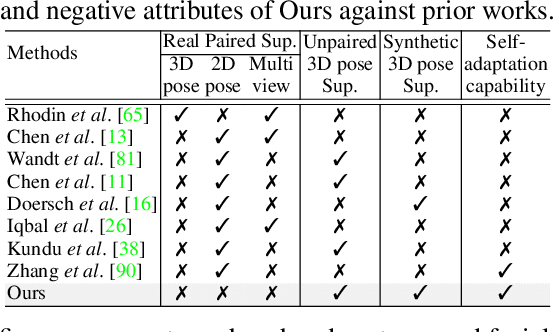
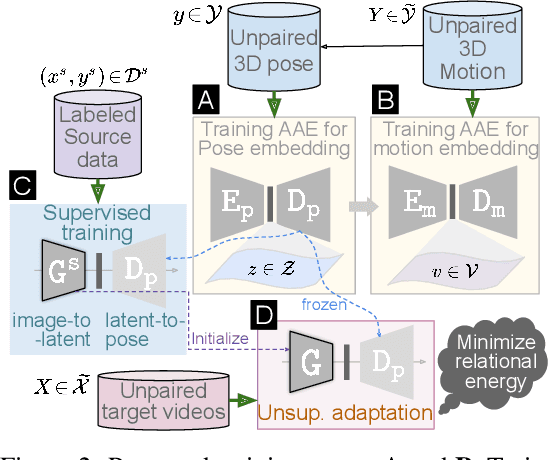
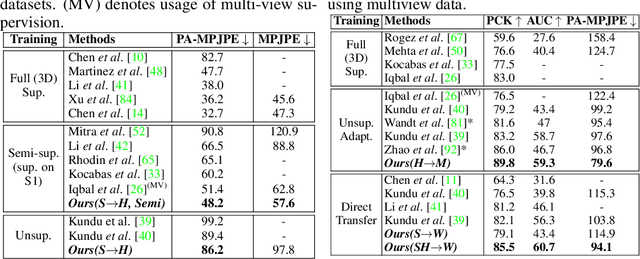
Available 3D human pose estimation approaches leverage different forms of strong (2D/3D pose) or weak (multi-view or depth) paired supervision. Barring synthetic or in-studio domains, acquiring such supervision for each new target environment is highly inconvenient. To this end, we cast 3D pose learning as a self-supervised adaptation problem that aims to transfer the task knowledge from a labeled source domain to a completely unpaired target. We propose to infer image-to-pose via two explicit mappings viz. image-to-latent and latent-to-pose where the latter is a pre-learned decoder obtained from a prior-enforcing generative adversarial auto-encoder. Next, we introduce relation distillation as a means to align the unpaired cross-modal samples i.e. the unpaired target videos and unpaired 3D pose sequences. To this end, we propose a new set of non-local relations in order to characterize long-range latent pose interactions unlike general contrastive relations where positive couplings are limited to a local neighborhood structure. Further, we provide an objective way to quantify non-localness in order to select the most effective relation set. We evaluate different self-adaptation settings and demonstrate state-of-the-art 3D human pose estimation performance on standard benchmarks.
Uncertainty-Aware Adaptation for Self-Supervised 3D Human Pose Estimation
Mar 29, 2022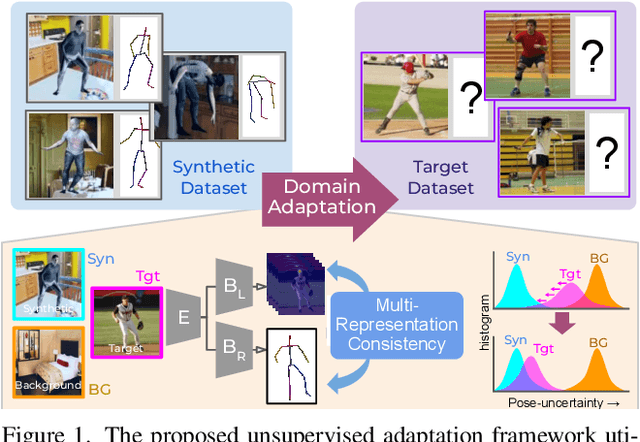

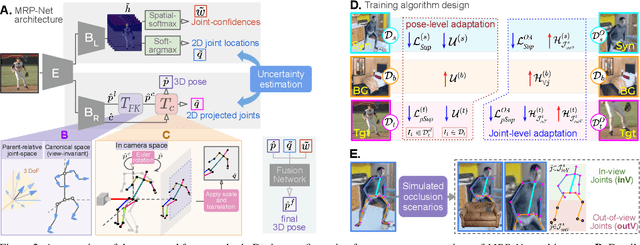
The advances in monocular 3D human pose estimation are dominated by supervised techniques that require large-scale 2D/3D pose annotations. Such methods often behave erratically in the absence of any provision to discard unfamiliar out-of-distribution data. To this end, we cast the 3D human pose learning as an unsupervised domain adaptation problem. We introduce MRP-Net that constitutes a common deep network backbone with two output heads subscribing to two diverse configurations; a) model-free joint localization and b) model-based parametric regression. Such a design allows us to derive suitable measures to quantify prediction uncertainty at both pose and joint level granularity. While supervising only on labeled synthetic samples, the adaptation process aims to minimize the uncertainty for the unlabeled target images while maximizing the same for an extreme out-of-distribution dataset (backgrounds). Alongside synthetic-to-real 3D pose adaptation, the joint-uncertainties allow expanding the adaptation to work on in-the-wild images even in the presence of occlusion and truncation scenarios. We present a comprehensive evaluation of the proposed approach and demonstrate state-of-the-art performance on benchmark datasets.
SISL:Self-Supervised Image Signature Learning for Splicing Detection and Localization
Mar 15, 2022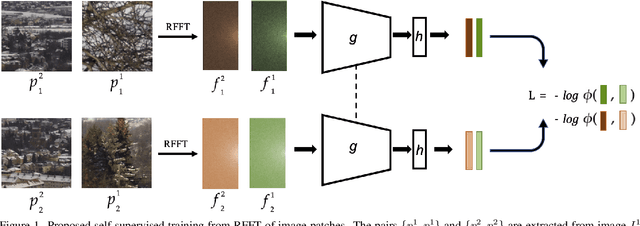
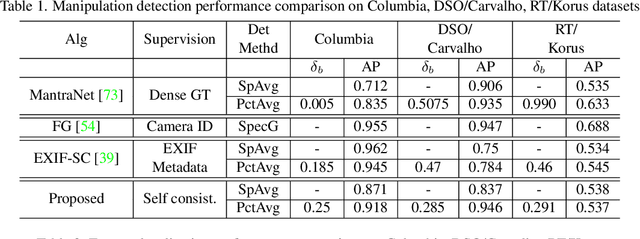
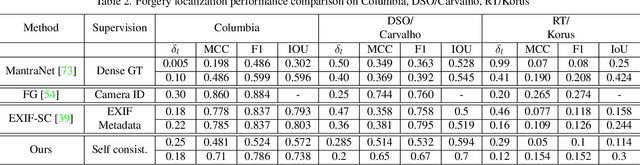

Recent algorithms for image manipulation detection almost exclusively use deep network models. These approaches require either dense pixelwise groundtruth masks, camera ids, or image metadata to train the networks. On one hand, constructing a training set to represent the countless tampering possibilities is impractical. On the other hand, social media platforms or commercial applications are often constrained to remove camera ids as well as metadata from images. A self-supervised algorithm for training manipulation detection models without dense groundtruth or camera/image metadata would be extremely useful for many forensics applications. In this paper, we propose self-supervised approach for training splicing detection/localization models from frequency transforms of images. To identify the spliced regions, our deep network learns a representation to capture an image specific signature by enforcing (image) self consistency . We experimentally demonstrate that our proposed model can yield similar or better performances of multiple existing methods on standard datasets without relying on labels or metadata.
Kinematic-Structure-Preserved Representation for Unsupervised 3D Human Pose Estimation
Jun 24, 2020
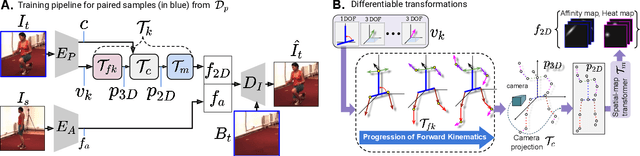
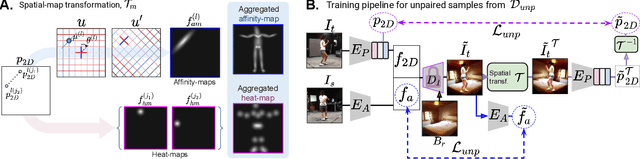
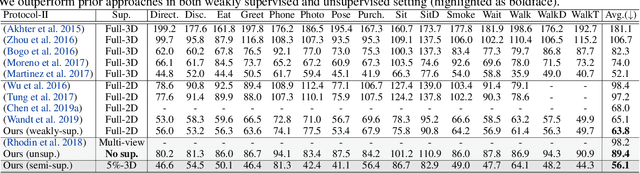
Estimation of 3D human pose from monocular image has gained considerable attention, as a key step to several human-centric applications. However, generalizability of human pose estimation models developed using supervision on large-scale in-studio datasets remains questionable, as these models often perform unsatisfactorily on unseen in-the-wild environments. Though weakly-supervised models have been proposed to address this shortcoming, performance of such models relies on availability of paired supervision on some related tasks, such as 2D pose or multi-view image pairs. In contrast, we propose a novel kinematic-structure-preserved unsupervised 3D pose estimation framework, which is not restrained by any paired or unpaired weak supervisions. Our pose estimation framework relies on a minimal set of prior knowledge that defines the underlying kinematic 3D structure, such as skeletal joint connectivity information with bone-length ratios in a fixed canonical scale. The proposed model employs three consecutive differentiable transformations named as forward-kinematics, camera-projection and spatial-map transformation. This design not only acts as a suitable bottleneck stimulating effective pose disentanglement but also yields interpretable latent pose representations avoiding training of an explicit latent embedding to pose mapper. Furthermore, devoid of unstable adversarial setup, we re-utilize the decoder to formalize an energy-based loss, which enables us to learn from in-the-wild videos, beyond laboratory settings. Comprehensive experiments demonstrate our state-of-the-art unsupervised and weakly-supervised pose estimation performance on both Human3.6M and MPI-INF-3DHP datasets. Qualitative results on unseen environments further establish our superior generalization ability.
Self-Supervised 3D Human Pose Estimation via Part Guided Novel Image Synthesis
Apr 09, 2020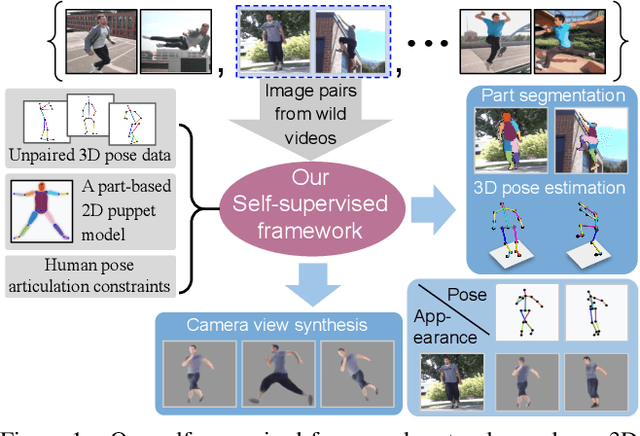


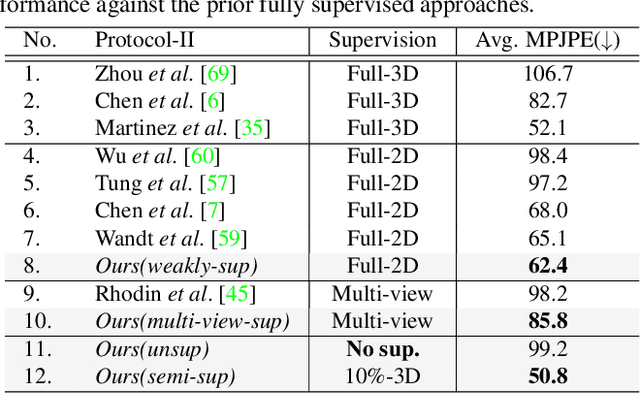
Camera captured human pose is an outcome of several sources of variation. Performance of supervised 3D pose estimation approaches comes at the cost of dispensing with variations, such as shape and appearance, that may be useful for solving other related tasks. As a result, the learned model not only inculcates task-bias but also dataset-bias because of its strong reliance on the annotated samples, which also holds true for weakly-supervised models. Acknowledging this, we propose a self-supervised learning framework to disentangle such variations from unlabeled video frames. We leverage the prior knowledge on human skeleton and poses in the form of a single part-based 2D puppet model, human pose articulation constraints, and a set of unpaired 3D poses. Our differentiable formalization, bridging the representation gap between the 3D pose and spatial part maps, not only facilitates discovery of interpretable pose disentanglement but also allows us to operate on videos with diverse camera movements. Qualitative results on unseen in-the-wild datasets establish our superior generalization across multiple tasks beyond the primary tasks of 3D pose estimation and part segmentation. Furthermore, we demonstrate state-of-the-art weakly-supervised 3D pose estimation performance on both Human3.6M and MPI-INF-3DHP datasets.