 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSISL:Self-Supervised Image Signature Learning for Splicing Detection and Localization
Paper and Code
Mar 15, 2022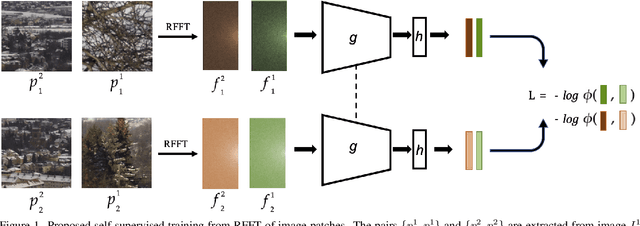
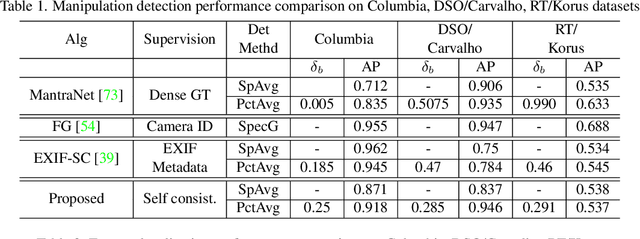
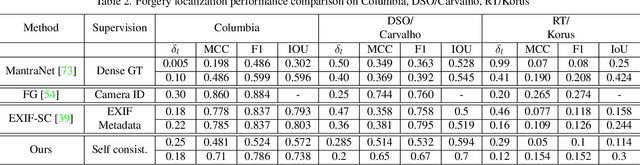

Recent algorithms for image manipulation detection almost exclusively use deep network models. These approaches require either dense pixelwise groundtruth masks, camera ids, or image metadata to train the networks. On one hand, constructing a training set to represent the countless tampering possibilities is impractical. On the other hand, social media platforms or commercial applications are often constrained to remove camera ids as well as metadata from images. A self-supervised algorithm for training manipulation detection models without dense groundtruth or camera/image metadata would be extremely useful for many forensics applications. In this paper, we propose self-supervised approach for training splicing detection/localization models from frequency transforms of images. To identify the spliced regions, our deep network learns a representation to capture an image specific signature by enforcing (image) self consistency . We experimentally demonstrate that our proposed model can yield similar or better performances of multiple existing methods on standard datasets without relying on labels or metadata.