 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIRTUE: Versatile Video Retrieval Through Unified Embeddings
Jan 17, 2026Modern video retrieval systems are expected to handle diverse tasks ranging from corpus-level retrieval and fine-grained moment localization to flexible multimodal querying. Specialized architectures achieve strong retrieval performance by training modality-specific encoders on massive datasets, but they lack the ability to process composed multimodal queries. In contrast, multimodal LLM (MLLM)-based methods support rich multimodal search but their retrieval performance remains well below that of specialized systems. We present VIRTUE, an MLLM-based versatile video retrieval framework that integrates corpus and moment-level retrieval capabilities while accommodating composed multimodal queries within a single architecture. We use contrastive alignment of visual and textual embeddings generated using a shared MLLM backbone to facilitate efficient embedding-based candidate search. Our embedding model, trained efficiently using low-rank adaptation (LoRA) on 700K paired visual-text data samples, surpasses other MLLM-based methods on zero-shot video retrieval tasks. Additionally, we demonstrate that the same model can be adapted without further training to achieve competitive results on zero-shot moment retrieval, and state of the art results for zero-shot composed video retrieval. With additional training for reranking candidates identified in the embedding-based search, our model substantially outperforms existing MLLM-based retrieval systems and achieves retrieval performance comparable to state of the art specialized models which are trained on orders of magnitude larger data.
VIDEOP2R: Video Understanding from Perception to Reasoning
Nov 14, 2025Reinforcement fine-tuning (RFT), a two-stage framework consisting of supervised fine-tuning (SFT) and reinforcement learning (RL) has shown promising results on improving reasoning ability of large language models (LLMs). Yet extending RFT to large video language models (LVLMs) remains challenging. We propose VideoP2R, a novel process-aware video RFT framework that enhances video reasoning by modeling perception and reasoning as distinct processes. In the SFT stage, we develop a three-step pipeline to generate VideoP2R-CoT-162K, a high-quality, process-aware chain-of-thought (CoT) dataset for perception and reasoning. In the RL stage, we introduce a novel process-aware group relative policy optimization (PA-GRPO) algorithm that supplies separate rewards for perception and reasoning. Extensive experiments show that VideoP2R achieves state-of-the-art (SotA) performance on six out of seven video reasoning and understanding benchmarks. Ablation studies further confirm the effectiveness of our process-aware modeling and PA-GRPO and demonstrate that model's perception output is information-sufficient for downstream reasoning.
SISL:Self-Supervised Image Signature Learning for Splicing Detection and Localization
Mar 15, 2022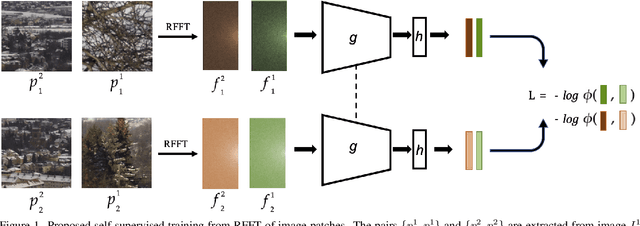
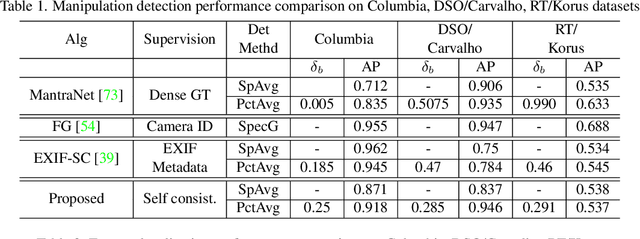
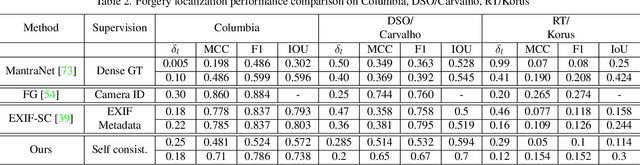

Recent algorithms for image manipulation detection almost exclusively use deep network models. These approaches require either dense pixelwise groundtruth masks, camera ids, or image metadata to train the networks. On one hand, constructing a training set to represent the countless tampering possibilities is impractical. On the other hand, social media platforms or commercial applications are often constrained to remove camera ids as well as metadata from images. A self-supervised algorithm for training manipulation detection models without dense groundtruth or camera/image metadata would be extremely useful for many forensics applications. In this paper, we propose self-supervised approach for training splicing detection/localization models from frequency transforms of images. To identify the spliced regions, our deep network learns a representation to capture an image specific signature by enforcing (image) self consistency . We experimentally demonstrate that our proposed model can yield similar or better performances of multiple existing methods on standard datasets without relying on labels or metadata.
Class Incremental Online Streaming Learning
Oct 20, 2021
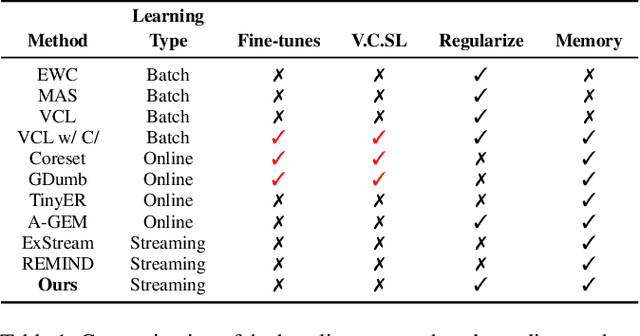

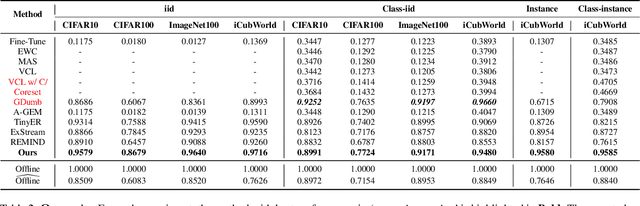
A wide variety of methods have been developed to enable lifelong learning in conventional deep neural networks. However, to succeed, these methods require a `batch' of samples to be available and visited multiple times during training. While this works well in a static setting, these methods continue to suffer in a more realistic situation where data arrives in \emph{online streaming manner}. We empirically demonstrate that the performance of current approaches degrades if the input is obtained as a stream of data with the following restrictions: $(i)$ each instance comes one at a time and can be seen only once, and $(ii)$ the input data violates the i.i.d assumption, i.e., there can be a class-based correlation. We propose a novel approach (CIOSL) for the class-incremental learning in an \emph{online streaming setting} to address these challenges. The proposed approach leverages implicit and explicit dual weight regularization and experience replay. The implicit regularization is leveraged via the knowledge distillation, while the explicit regularization incorporates a novel approach for parameter regularization by learning the joint distribution of the buffer replay and the current sample. Also, we propose an efficient online memory replay and replacement buffer strategy that significantly boosts the model's performance. Extensive experiments and ablation on challenging datasets show the efficacy of the proposed method.
Multilayer Dense Connections for Hierarchical Concept Classification
Mar 19, 2020
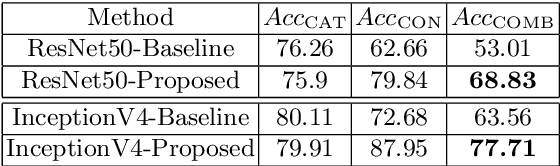
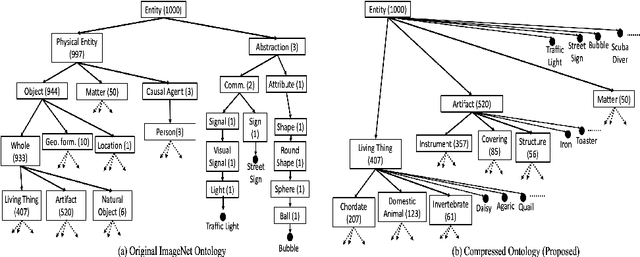

Classification is a pivotal function for many computer vision tasks such as object classification, detection, scene segmentation. Multinomial logistic regression with a single final layer of dense connections has become the ubiquitous technique for CNN-based classification. While these classifiers learn a mapping between the input and a set of output category classes, they do not typically learn a comprehensive knowledge about the category. In particular, when a CNN based image classifier correctly identifies the image of a Chimpanzee, it does not know that it is a member of Primate, Mammal, Chordate families and a living thing. We propose a multilayer dense connectivity for a CNN to simultaneously predict the category and its conceptual superclasses in hierarchical order. We experimentally demonstrate that our proposed dense connections, in conjunction with popular convolutional feature layers, can learn to predict the conceptual classes with minimal increase in network size while maintaining the categorical classification accuracy.
VideoSSL: Semi-Supervised Learning for Video Classification
Feb 29, 2020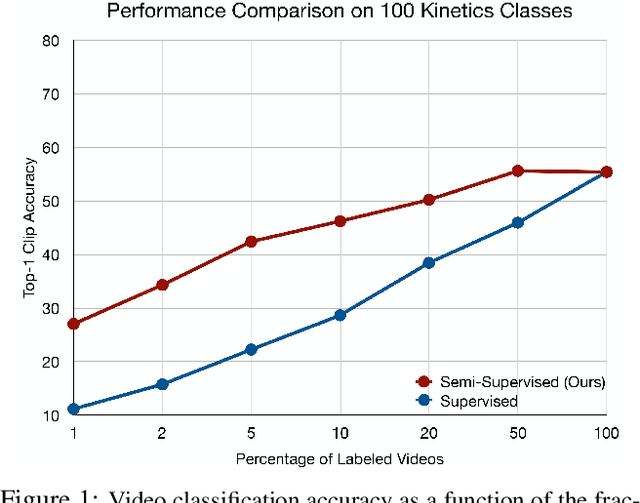



We propose a semi-supervised learning approach for video classification, VideoSSL, using convolutional neural networks (CNN). Like other computer vision tasks, existing supervised video classification methods demand a large amount of labeled data to attain good performance. However, annotation of a large dataset is expensive and time consuming. To minimize the dependence on a large annotated dataset, our proposed semi-supervised method trains from a small number of labeled examples and exploits two regulatory signals from unlabeled data. The first signal is the pseudo-labels of unlabeled examples computed from the confidences of the CNN being trained. The other is the normalized probabilities, as predicted by an image classifier CNN, that captures the information about appearances of the interesting objects in the video. We show that, under the supervision of these guiding signals from unlabeled examples, a video classification CNN can achieve impressive performances utilizing a small fraction of annotated examples on three publicly available datasets: UCF101, HMDB51 and Kinetics.
Detecting Synapse Location and Connectivity by Signed Proximity Estimation and Pruning with Deep Nets
Oct 25, 2018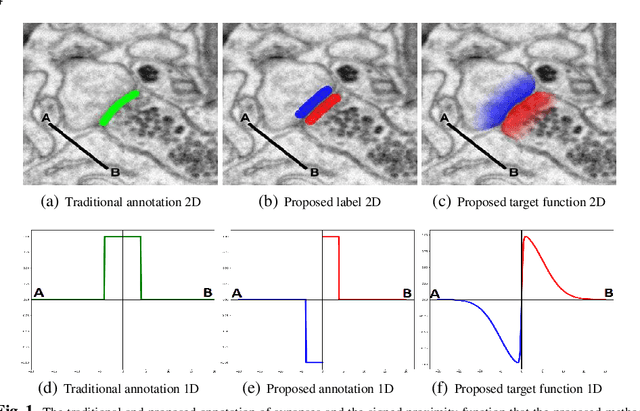



Synaptic connectivity detection is a critical task for neural reconstruction from Electron Microscopy (EM) data. Most of the existing algorithms for synapse detection do not identify the cleft location and direction of connectivity simultaneously. The few methods that computes direction along with contact location have only been demonstrated to work on either dyadic (most common in vertebrate brain) or polyadic (found in fruit fly brain) synapses, but not on both types. In this paper, we present an algorithm to automatically predict the location as well as the direction of both dyadic and polyadic synapses. The proposed algorithm first generates candidate synaptic connections from voxelwise predictions of signed proximity generated by a 3D U-net. A second 3D CNN then prunes the set of candidates to produce the final detection of cleft and connectivity orientation. Experimental results demonstrate that the proposed method outperforms the existing methods for determining synapses in both rodent and fruit fly brain.
Parallel Separable 3D Convolution for Video and Volumetric Data Understanding
Sep 11, 2018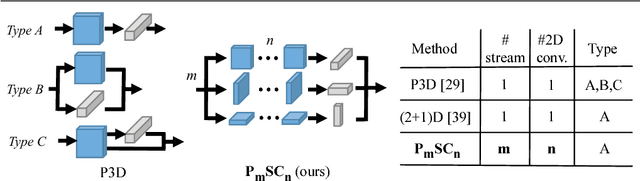

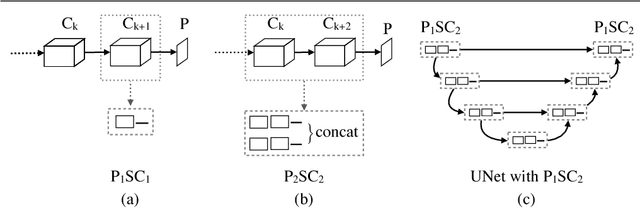
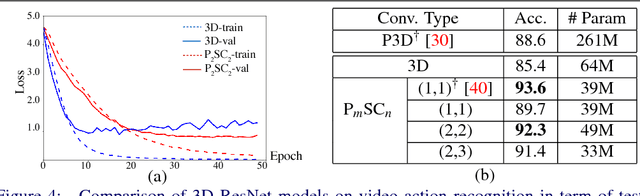
For video and volumetric data understanding, 3D convolution layers are widely used in deep learning, however, at the cost of increasing computation and training time. Recent works seek to replace the 3D convolution layer with convolution blocks, e.g. structured combinations of 2D and 1D convolution layers. In this paper, we propose a novel convolution block, Parallel Separable 3D Convolution (PmSCn), which applies m parallel streams of n 2D and one 1D convolution layers along different dimensions. We first mathematically justify the need of parallel streams (Pm) to replace a single 3D convolution layer through tensor decomposition. Then we jointly replace consecutive 3D convolution layers, common in modern network architectures, with the multiple 2D convolution layers (Cn). Lastly, we empirically show that PmSCn is applicable to different backbone architectures, such as ResNet, DenseNet, and UNet, for different applications, such as video action recognition, MRI brain segmentation, and electron microscopy segmentation. In all three applications, we replace the 3D convolution layers in state-of-the art models with PmSCn and achieve around 14% improvement in test performance and 40% reduction in model size and on average.
Anisotropic EM Segmentation by 3D Affinity Learning and Agglomeration
Aug 03, 2018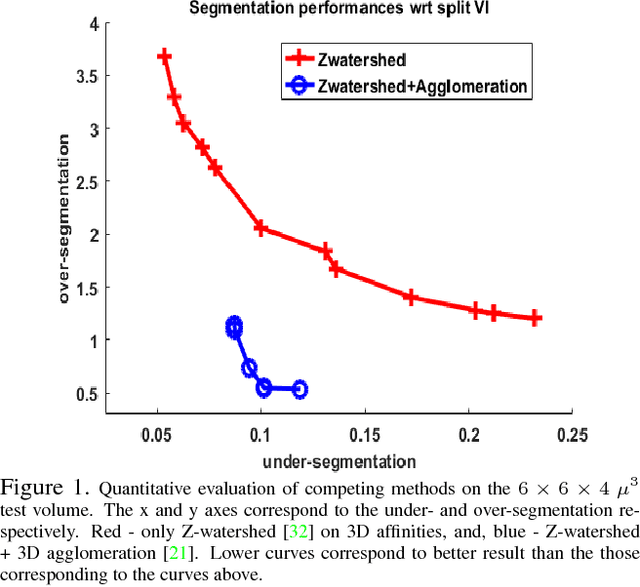
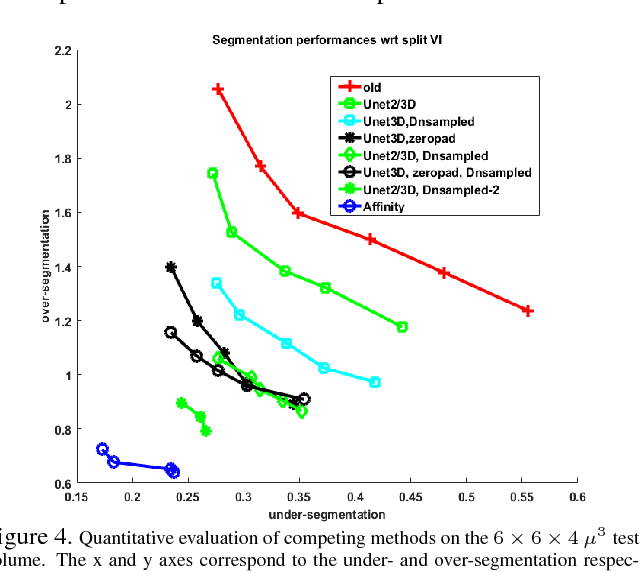
The field of connectomics has recently produced neuron wiring diagrams from relatively large brain regions from multiple animals. Most of these neural reconstructions were computed from isotropic (e.g., FIBSEM) or near isotropic (e.g., SBEM) data. In spite of the remarkable progress on algorithms in recent years, automatic dense reconstruction from anisotropic data remains a challenge for the connectomics community. One significant hurdle in the segmentation of anisotropic data is the difficulty in generating a suitable initial over-segmentation. In this study, we present a segmentation method for anisotropic EM data that agglomerates a 3D over-segmentation computed from the 3D affinity prediction. A 3D U-net is trained to predict 3D affinities by the MALIS approach. Experiments on multiple datasets demonstrates the strength and robustness of the proposed method for anisotropic EM segmentation.
Morphological Error Detection in 3D Segmentations
May 30, 2017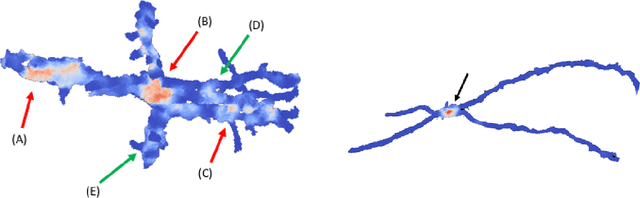
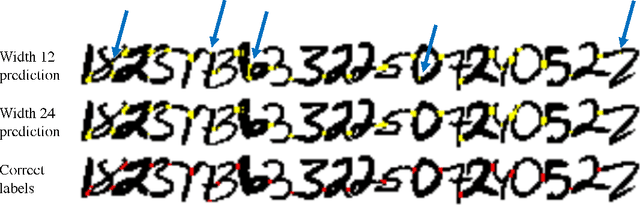
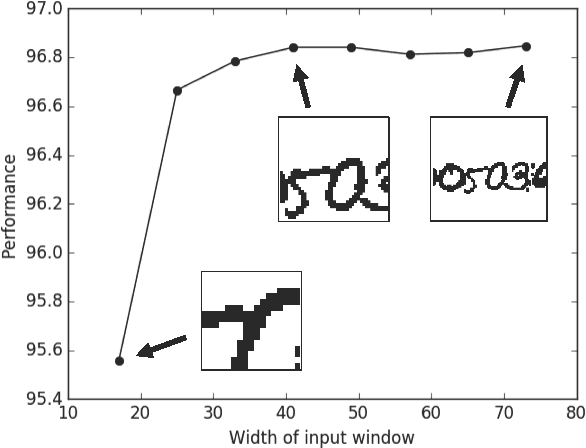
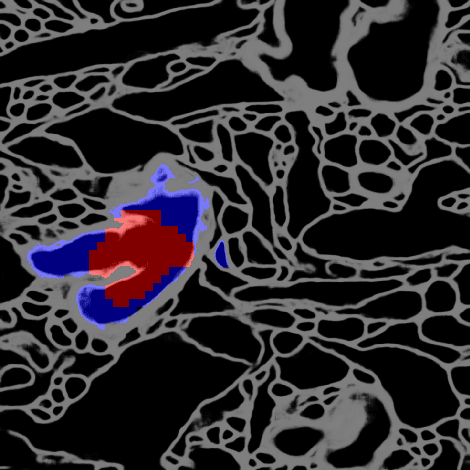
Deep learning algorithms for connectomics rely upon localized classification, rather than overall morphology. This leads to a high incidence of erroneously merged objects. Humans, by contrast, can easily detect such errors by acquiring intuition for the correct morphology of objects. Biological neurons have complicated and variable shapes, which are challenging to learn, and merge errors take a multitude of different forms. We present an algorithm, MergeNet, that shows 3D ConvNets can, in fact, detect merge errors from high-level neuronal morphology. MergeNet follows unsupervised training and operates across datasets. We demonstrate the performance of MergeNet both on a variety of connectomics data and on a dataset created from merged MNIST images.