 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning of Mixture-of-Experts Mixed-Precision Neural Networks
Sep 29, 2022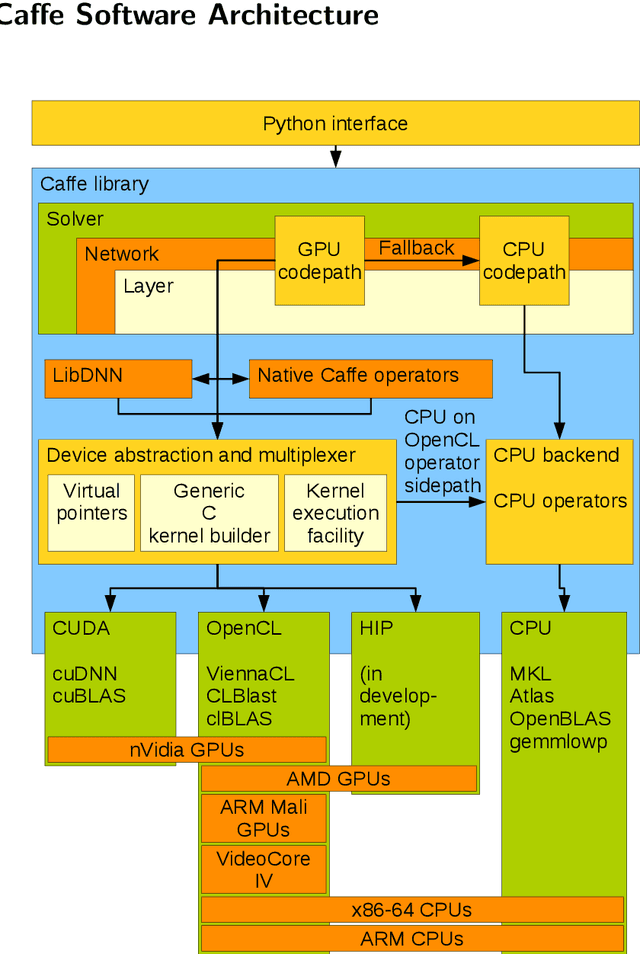
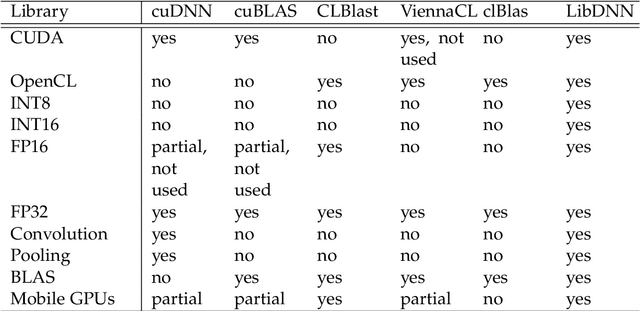
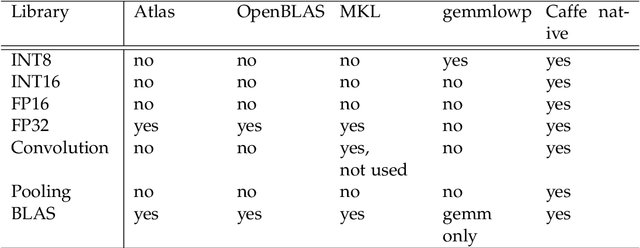
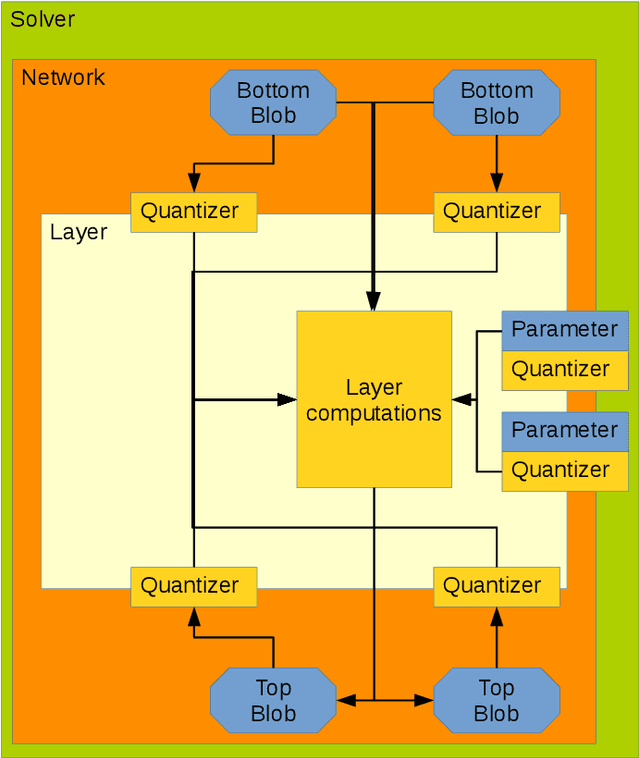
Deep learning has become a useful data analysis method, however mainstream adaption in distributed computer software and embedded devices has been low so far. Often, adding deep learning inference in mainstream applications and devices requires new hardware with signal processors suited for convolutional neural networks. This work adds new data types (quantized 16-bit and 8-bit integer, 16-bit floating point) to Caffe in order to save memory and increase inference speed on existing commodity graphics processors with OpenCL, common in everyday devices. Existing models can be executed effortlessly in mixed-precision mode. Additionally, we propose a variation of mixture-of-experts to increase inference speed on AlexNet for image classification. We managed to decrease memory usage up to 3.29x while increasing inference speed up to 3.01x on certain devices. We demonstrate with five simple examples how the presented techniques can easily be applied to different machine learning problems. The whole pipeline, consisting of models, example python scripts and modified Caffe library, is available as Open Source software.
Anisotropic EM Segmentation by 3D Affinity Learning and Agglomeration
Aug 03, 2018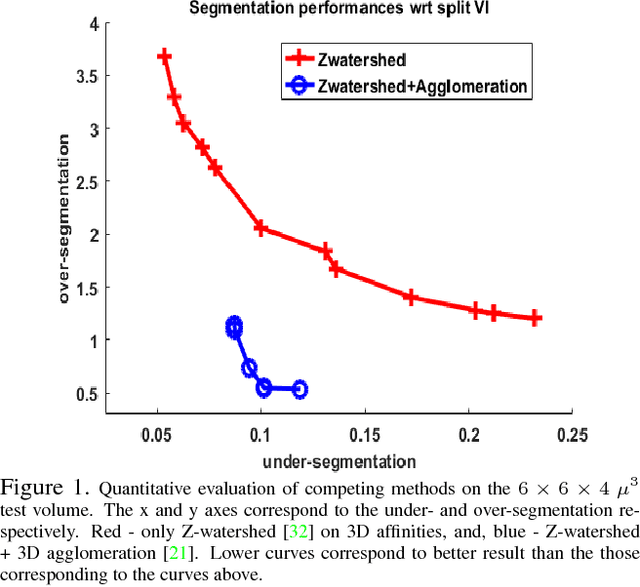
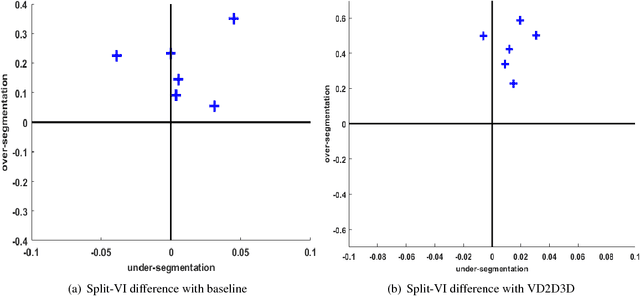
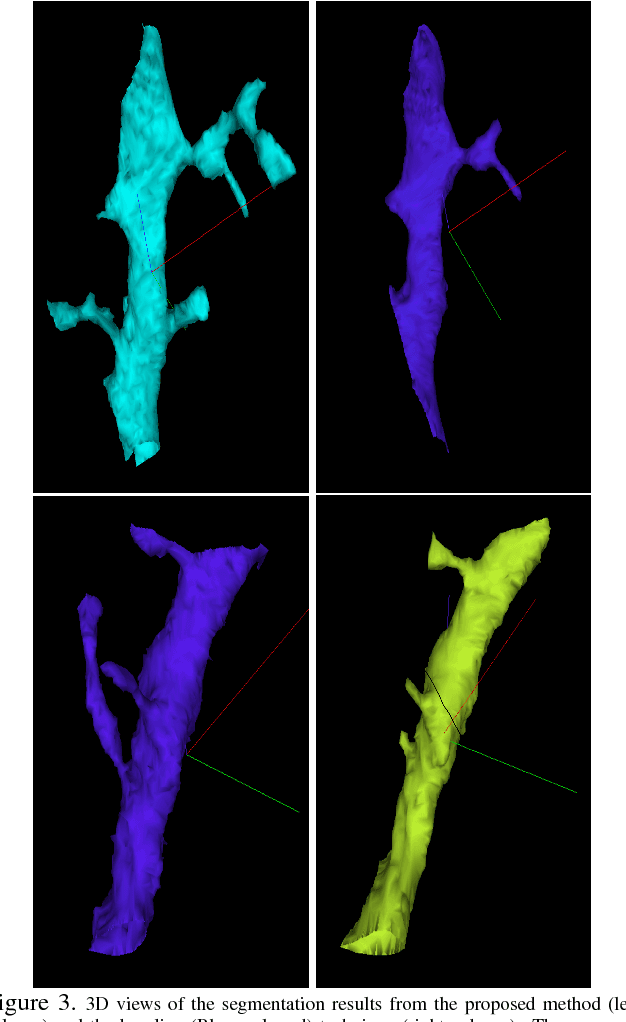
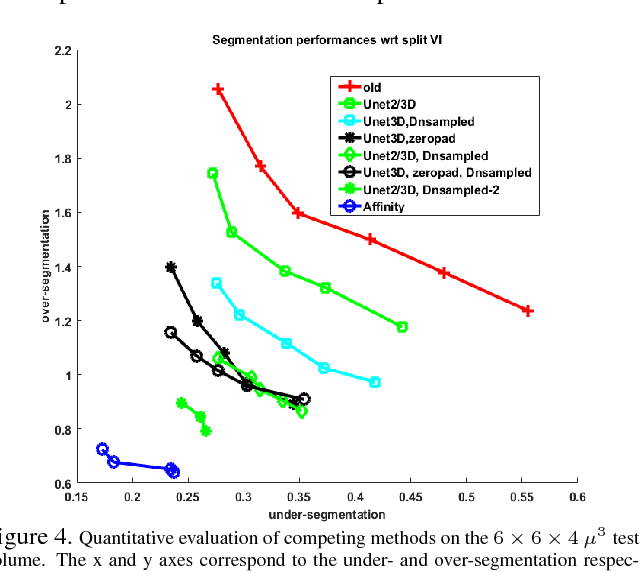
The field of connectomics has recently produced neuron wiring diagrams from relatively large brain regions from multiple animals. Most of these neural reconstructions were computed from isotropic (e.g., FIBSEM) or near isotropic (e.g., SBEM) data. In spite of the remarkable progress on algorithms in recent years, automatic dense reconstruction from anisotropic data remains a challenge for the connectomics community. One significant hurdle in the segmentation of anisotropic data is the difficulty in generating a suitable initial over-segmentation. In this study, we present a segmentation method for anisotropic EM data that agglomerates a 3D over-segmentation computed from the 3D affinity prediction. A 3D U-net is trained to predict 3D affinities by the MALIS approach. Experiments on multiple datasets demonstrates the strength and robustness of the proposed method for anisotropic EM segmentation.
Robust Large-Scale Localization in 3D Point Clouds Revisited
Nov 03, 2015
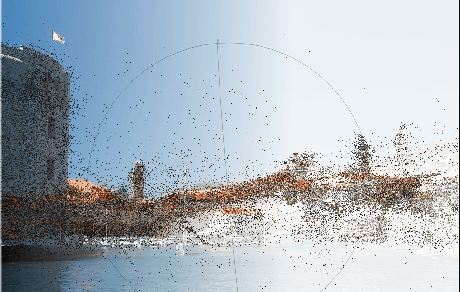

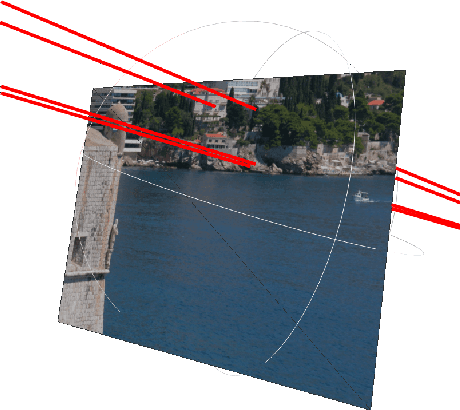
We tackle the problem of getting a full 6-DOF pose estimation of a query image inside a given point cloud. This technical report re-evaluates the algorithms proposed by Y. Li et al. "Worldwide Pose Estimation using 3D Point Cloud". Our code computes poses from 3 or 4 points, with both known and unknown focal length. The results can easily be displayed and analyzed with Meshlab. We found both advantages and shortcomings of the methods proposed. Furthermore, additional priors and parameters for point selection, RANSAC and pose quality estimate (inlier test) are proposed and applied.
Efficient Convolutional Neural Networks for Pixelwise Classification on Heterogeneous Hardware Systems
Sep 11, 2015

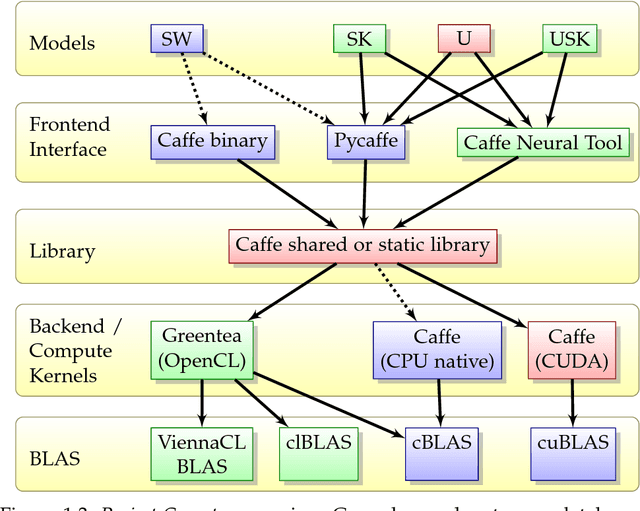
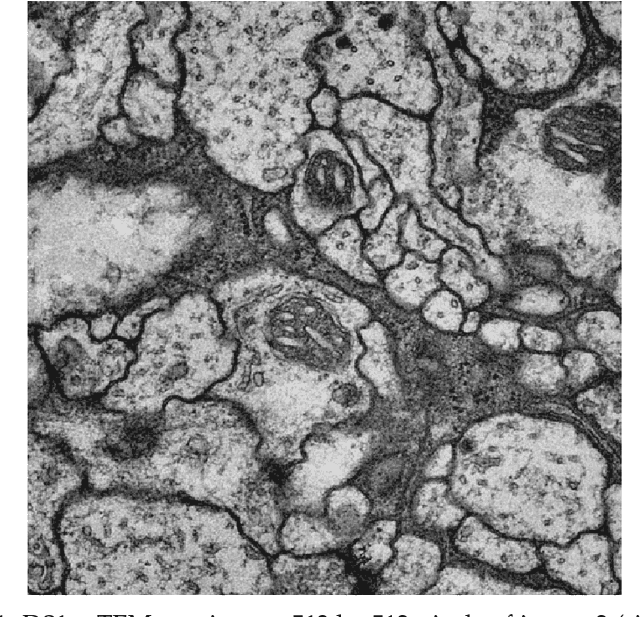
This work presents and analyzes three convolutional neural network (CNN) models for efficient pixelwise classification of images. When using convolutional neural networks to classify single pixels in patches of a whole image, a lot of redundant computations are carried out when using sliding window networks. This set of new architectures solve this issue by either removing redundant computations or using fully convolutional architectures that inherently predict many pixels at once. The implementations of the three models are accessible through a new utility on top of the Caffe library. The utility provides support for a wide range of image input and output formats, pre-processing parameters and methods to equalize the label histogram during training. The Caffe library has been extended by new layers and a new backend for availability on a wider range of hardware such as CPUs and GPUs through OpenCL. On AMD GPUs, speedups of $54\times$ (SK-Net), $437\times$ (U-Net) and $320\times$ (USK-Net) have been observed, taking the SK equivalent SW (sliding window) network as the baseline. The label throughput is up to one megapixel per second. The analyzed neural networks have distinctive characteristics that apply during training or processing, and not every data set is suitable to every architecture. The quality of the predictions is assessed on two neural tissue data sets, of which one is the ISBI 2012 challenge data set. Two different loss functions, Malis loss and Softmax loss, were used during training. The whole pipeline, consisting of models, interface and modified Caffe library, is available as Open Source software under the working title Project Greentea.