 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Visual Enumeration Abilities of Specialized Counting Architectures and Vision-Language Models
Dec 17, 2025Counting the number of items in a visual scene remains a fundamental yet challenging task in computer vision. Traditional approaches to solving this problem rely on domain-specific counting architectures, which are trained using datasets annotated with a predefined set of object categories. However, recent progress in creating large-scale multimodal vision-language models (VLMs) suggests that these domain-general architectures may offer a flexible alternative for open-set object counting. In this study, we therefore systematically compare the performance of state-of-the-art specialized counting architectures against VLMs on two popular counting datasets, as well as on a novel benchmark specifically created to have a finer-grained control over the visual properties of test images. Our findings show that most VLMs can approximately enumerate the number of items in a visual scene, matching or even surpassing the performance of specialized computer vision architectures. Notably, enumeration accuracy significantly improves when VLMs are prompted to generate intermediate representations (i.e., locations and verbal labels) of each object to be counted. Nevertheless, none of the models can reliably count the number of objects in complex visual scenes, showing that further research is still needed to create AI systems that can reliably deploy counting procedures in realistic environments.
Estimating the distribution of numerosity and non-numerical visual magnitudes in natural scenes using computer vision
Sep 17, 2024



Humans share with many animal species the ability to perceive and approximately represent the number of objects in visual scenes. This ability improves throughout childhood, suggesting that learning and development play a key role in shaping our number sense. This hypothesis is further supported by computational investigations based on deep learning, which have shown that numerosity perception can spontaneously emerge in neural networks that learn the statistical structure of images with a varying number of items. However, neural network models are usually trained using synthetic datasets that might not faithfully reflect the statistical structure of natural environments. In this work, we exploit recent advances in computer vision algorithms to design and implement an original pipeline that can be used to estimate the distribution of numerosity and non-numerical magnitudes in large-scale datasets containing thousands of real images depicting objects in daily life situations. We show that in natural visual scenes the frequency of appearance of different numerosities follows a power law distribution and that numerosity is strongly correlated with many continuous magnitudes, such as cumulative areas and convex hull, which might explain why numerosity judgements are often influenced by these non-numerical cues.
Investigating the generative dynamics of energy-based neural networks
May 11, 2023


Generative neural networks can produce data samples according to the statistical properties of their training distribution. This feature can be used to test modern computational neuroscience hypotheses suggesting that spontaneous brain activity is partially supported by top-down generative processing. A widely studied class of generative models is that of Restricted Boltzmann Machines (RBMs), which can be used as building blocks for unsupervised deep learning architectures. In this work, we systematically explore the generative dynamics of RBMs, characterizing the number of states visited during top-down sampling and investigating whether the heterogeneity of visited attractors could be increased by starting the generation process from biased hidden states. By considering an RBM trained on a classic dataset of handwritten digits, we show that the capacity to produce diverse data prototypes can be increased by initiating top-down sampling from chimera states, which encode high-level visual features of multiple digits. We also found that the model is not capable of transitioning between all possible digit states within a single generation trajectory, suggesting that the top-down dynamics is heavily constrained by the shape of the energy function.
A developmental approach for training deep belief networks
Jul 12, 2022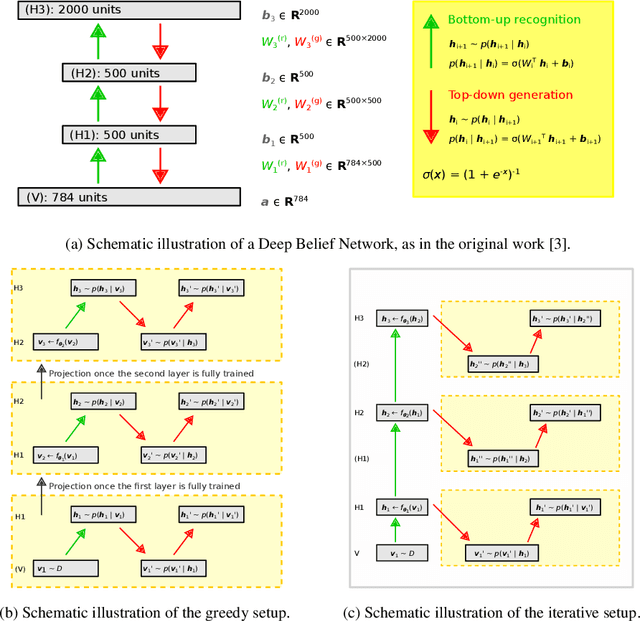
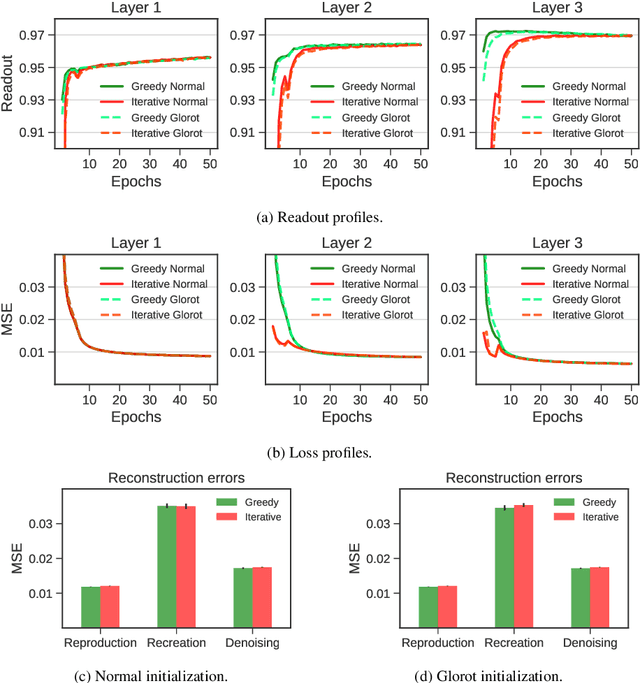
Deep belief networks (DBNs) are stochastic neural networks that can extract rich internal representations of the environment from the sensory data. DBNs had a catalytic effect in triggering the deep learning revolution, demonstrating for the very first time the feasibility of unsupervised learning in networks with many layers of hidden neurons. Thanks to their biological and cognitive plausibility, these hierarchical architectures have been also successfully exploited to build computational models of human perception and cognition in a variety of domains. However, learning in DBNs is usually carried out in a greedy, layer-wise fashion, which does not allow to simulate the holistic development of cortical circuits. Here we present iDBN, an iterative learning algorithm for DBNs that allows to jointly update the connection weights across all layers of the hierarchy. We test our algorithm on two different sets of visual stimuli, and we show that network development can also be tracked in terms of graph theoretical properties. DBNs trained using our iterative approach achieve a final performance comparable to that of the greedy counterparts, at the same time allowing to accurately analyze the gradual development of internal representations in the generative model. Our work paves the way to the use of iDBN for modeling neurocognitive development.
On the difficulty of learning and predicting the long-term dynamics of bouncing objects
Jul 31, 2019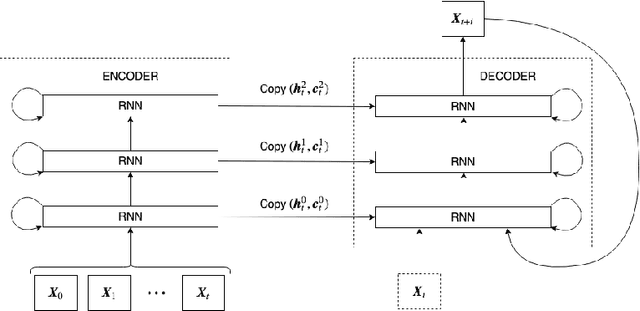
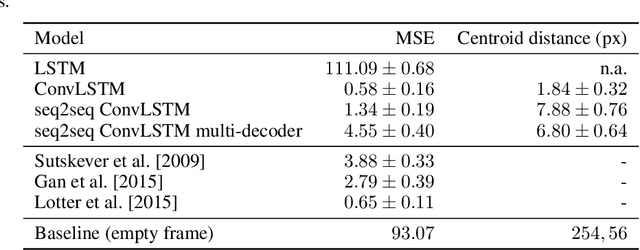

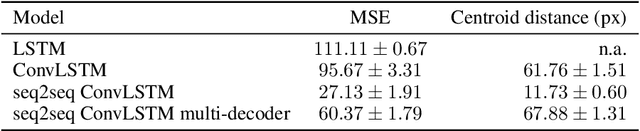
The ability to accurately predict the surrounding environment is a foundational principle of intelligence in biological and artificial agents. In recent years, a variety of approaches have been proposed for learning to predict the physical dynamics of objects interacting in a visual scene. Here we conduct a systematic empirical evaluation of several state-of-the-art unsupervised deep learning models that are considered capable of learning the spatio-temporal structure of a popular dataset composed by synthetic videos of bouncing objects. We show that most of the models indeed obtain high accuracy on the standard benchmark of predicting the next frame of a sequence, and one of them even achieves state-of-the-art performance. However, all models fall short when probed with the more challenging task of generating multiple successive frames. Our results show that the ability to perform short-term predictions does not imply that the model has captured the underlying structure and dynamics of the visual environment, thereby calling for a careful rethinking of the metrics commonly adopted for evaluating temporal models. We also investigate whether the learning outcome could be affected by the use of curriculum-based teaching.
Perception of visual numerosity in humans and machines
Jul 16, 2019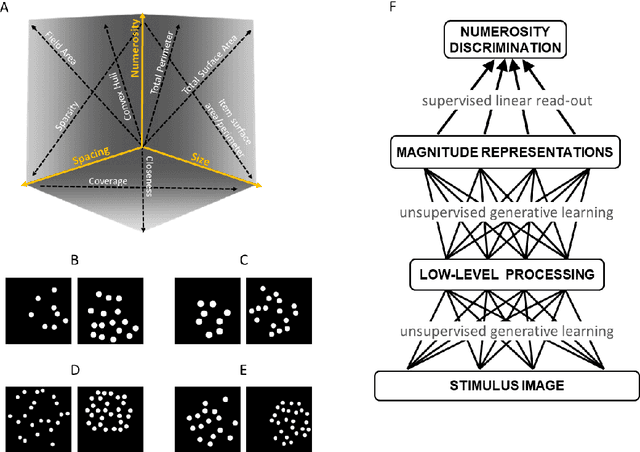
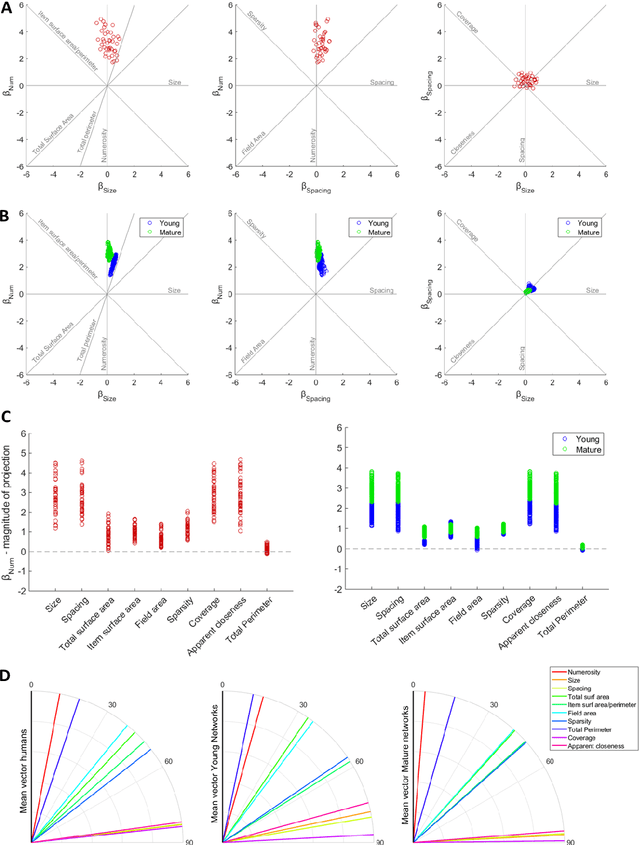
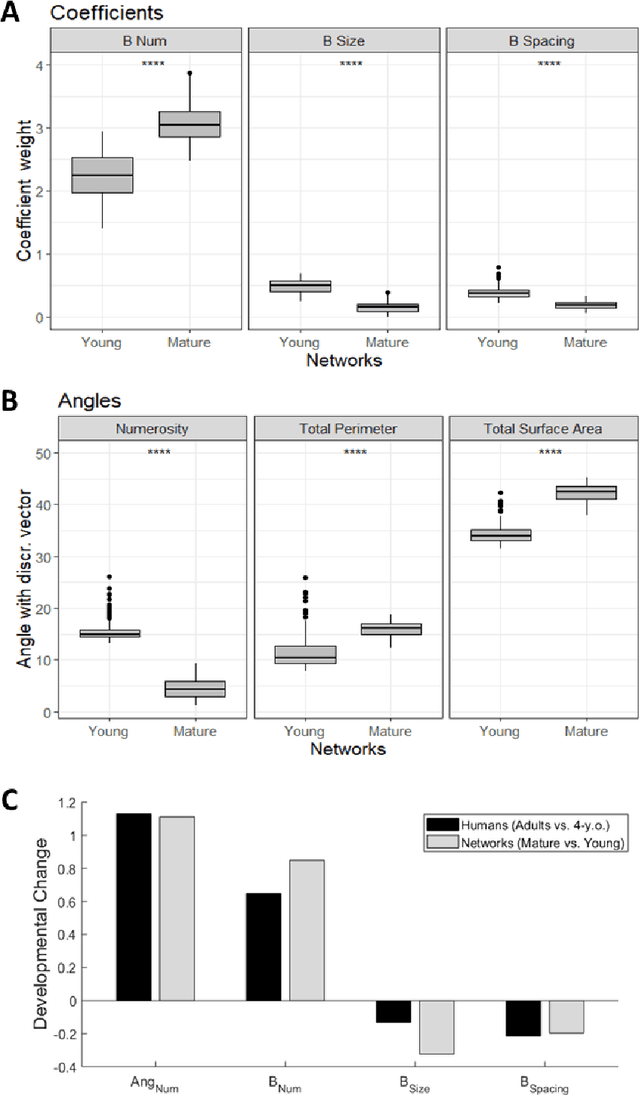
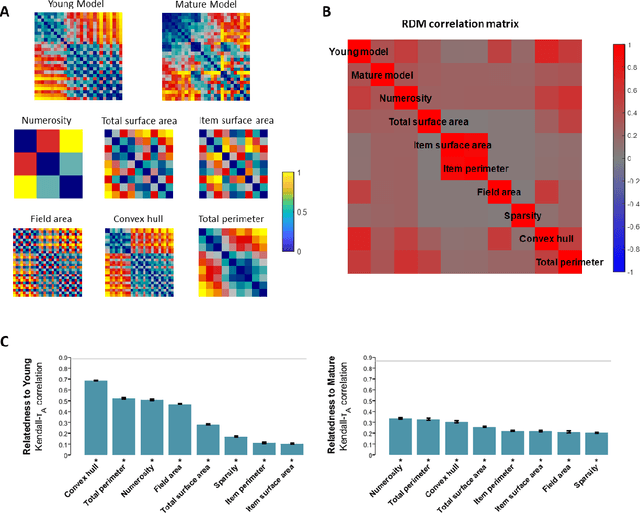
Numerosity perception is foundational to mathematical learning, but its computational bases are strongly debated. Some investigators argue that humans are endowed with a specialized system supporting numerical representation; others argue that visual numerosity is estimated using continuous magnitudes, such as density or area, which usually co-vary with number. Here we reconcile these contrasting perspectives by testing deep networks on the same numerosity comparison task that was administered to humans, using a stimulus space that allows to measure the contribution of non-numerical features. Our model accurately simulated the psychophysics of numerosity perception and the associated developmental changes: discrimination was driven by numerosity information, but non-numerical features had a significant impact, especially early during development. Representational similarity analysis further highlighted that both numerosity and continuous magnitudes were spontaneously encoded even when no task had to be carried out, demonstrating that numerosity is a major, salient property of our visual environment.
Robust Large-Scale Localization in 3D Point Clouds Revisited
Nov 03, 2015

We tackle the problem of getting a full 6-DOF pose estimation of a query image inside a given point cloud. This technical report re-evaluates the algorithms proposed by Y. Li et al. "Worldwide Pose Estimation using 3D Point Cloud". Our code computes poses from 3 or 4 points, with both known and unknown focal length. The results can easily be displayed and analyzed with Meshlab. We found both advantages and shortcomings of the methods proposed. Furthermore, additional priors and parameters for point selection, RANSAC and pose quality estimate (inlier test) are proposed and applied.