 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the difficulty of learning and predicting the long-term dynamics of bouncing objects
Paper and Code
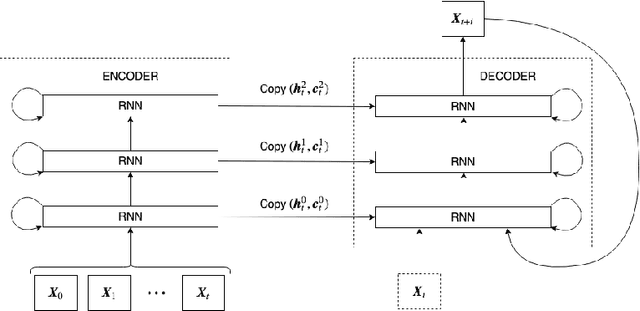
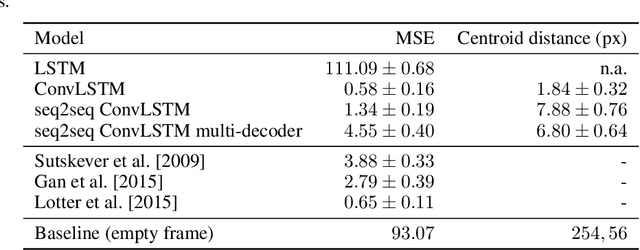

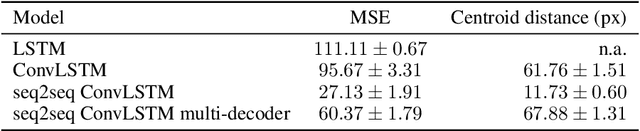
The ability to accurately predict the surrounding environment is a foundational principle of intelligence in biological and artificial agents. In recent years, a variety of approaches have been proposed for learning to predict the physical dynamics of objects interacting in a visual scene. Here we conduct a systematic empirical evaluation of several state-of-the-art unsupervised deep learning models that are considered capable of learning the spatio-temporal structure of a popular dataset composed by synthetic videos of bouncing objects. We show that most of the models indeed obtain high accuracy on the standard benchmark of predicting the next frame of a sequence, and one of them even achieves state-of-the-art performance. However, all models fall short when probed with the more challenging task of generating multiple successive frames. Our results show that the ability to perform short-term predictions does not imply that the model has captured the underlying structure and dynamics of the visual environment, thereby calling for a careful rethinking of the metrics commonly adopted for evaluating temporal models. We also investigate whether the learning outcome could be affected by the use of curriculum-based teaching.