 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning of Mixture-of-Experts Mixed-Precision Neural Networks
Paper and Code
Sep 29, 2022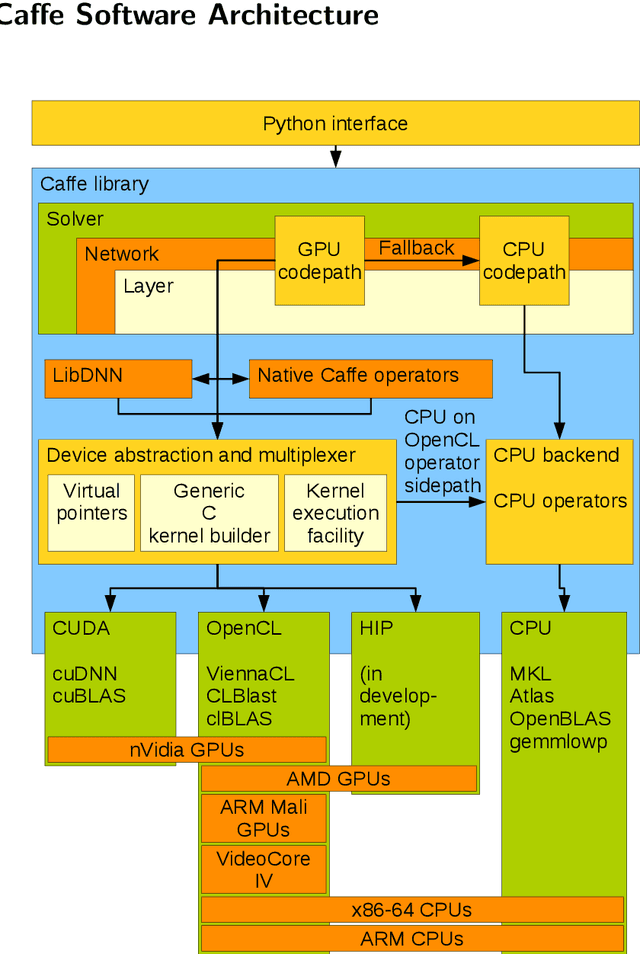
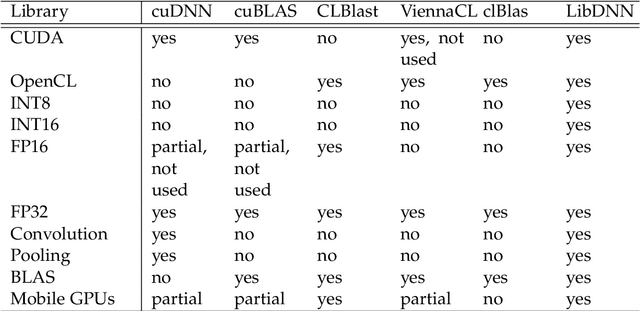
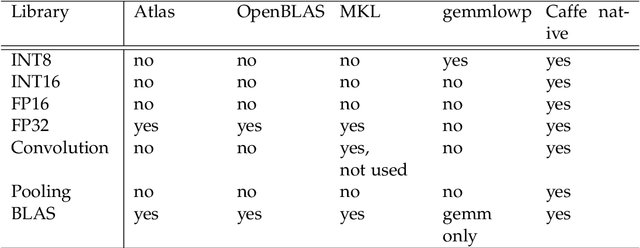
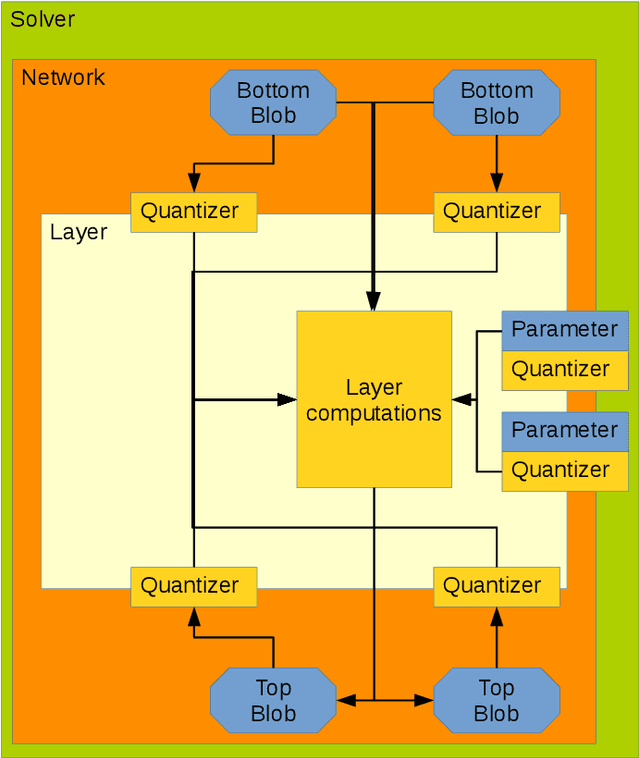
Deep learning has become a useful data analysis method, however mainstream adaption in distributed computer software and embedded devices has been low so far. Often, adding deep learning inference in mainstream applications and devices requires new hardware with signal processors suited for convolutional neural networks. This work adds new data types (quantized 16-bit and 8-bit integer, 16-bit floating point) to Caffe in order to save memory and increase inference speed on existing commodity graphics processors with OpenCL, common in everyday devices. Existing models can be executed effortlessly in mixed-precision mode. Additionally, we propose a variation of mixture-of-experts to increase inference speed on AlexNet for image classification. We managed to decrease memory usage up to 3.29x while increasing inference speed up to 3.01x on certain devices. We demonstrate with five simple examples how the presented techniques can easily be applied to different machine learning problems. The whole pipeline, consisting of models, example python scripts and modified Caffe library, is available as Open Source software.