 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interpretable Latency Model for Speculative Decoding in LLM Serving
May 14, 2026Speculative decoding (SD) accelerates large language model (LLM) inference by using a smaller draft model to propose multiple tokens that are verified by a larger target model in parallel. While prior work demonstrates substantial speedups in isolated or fixed-batch settings, the behavior of SD in production serving systems remains poorly understood: request load varies over time, and effective batch size emerges from the serving system rather than being directly controlled or observed. In this work, we develop a simple and interpretable latency model for SD in LLM serving. We infer effective batch size from request rate using Little's Law and decompose per-request demand into load-independent and load-dependent components for prefill, drafting, and verification. We validate our model using extensive measurements from vLLM across verifier and drafter model sizes, prefill and decode lengths, request rates, draft lengths, and acceptance probabilities. The model accurately describes observed latency, explains why speedups often diminish as server load increases, and characterizes how draft length, acceptance rate, and verifier-drafter size shape latency across serving conditions, with implications for configuring SD in deployed systems. We further show how the framework extends to mixture of experts models, where sparse expert activation changes the effective service costs across load regimes. Together, our results provide a structured framework for understanding SD in real LLM serving systems.
Understanding Empirical Unlearning with Combinatorial Interpretability
Feb 22, 2026While many recent methods aim to unlearn or remove knowledge from pretrained models, seemingly erased knowledge often persists and can be recovered in various ways. Because large foundation models are far from interpretable, understanding whether and how such knowledge persists remains a significant challenge. To address this, we turn to the recently developed framework of combinatorial interpretability. This framework, designed for two-layer neural networks, enables direct inspection of the knowledge encoded in the model weights. We reproduce baseline unlearning methods within the combinatorial interpretability setting and examine their behavior along two dimensions: (i) whether they truly remove knowledge of a target concept (the concept we wish to remove) or merely inhibit its expression while retaining the underlying information, and (ii) how easily the supposedly erased knowledge can be recovered through various fine-tuning operations. Our results shed light within a fully interpretable setting on how knowledge can persist despite unlearning and when it might resurface.
Learning to Interpret Weight Differences in Language Models
Oct 06, 2025Finetuning (pretrained) language models is a standard approach for updating their internal parametric knowledge and specializing them to new tasks and domains. However, the corresponding model weight changes ("weight diffs") are not generally interpretable. While inspecting the finetuning dataset can give a sense of how the model might have changed, these datasets are often not publicly available or are too large to work with directly. Towards the goal of comprehensively understanding weight diffs in natural language, we introduce Diff Interpretation Tuning (DIT), a method that trains models to describe their own finetuning-induced modifications. Our approach uses synthetic, labeled weight diffs to train a DIT adapter, which can be applied to a compatible finetuned model to make it describe how it has changed. We demonstrate in two proof-of-concept settings (reporting hidden behaviors and summarizing finetuned knowledge) that our method enables models to describe their finetuning-induced modifications using accurate natural language descriptions.
Expand Neurons, Not Parameters
Oct 06, 2025
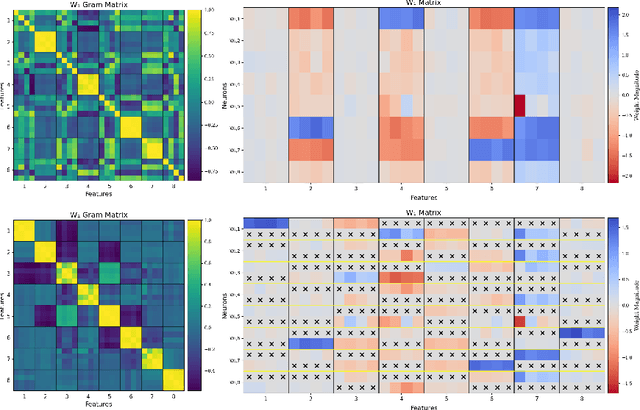
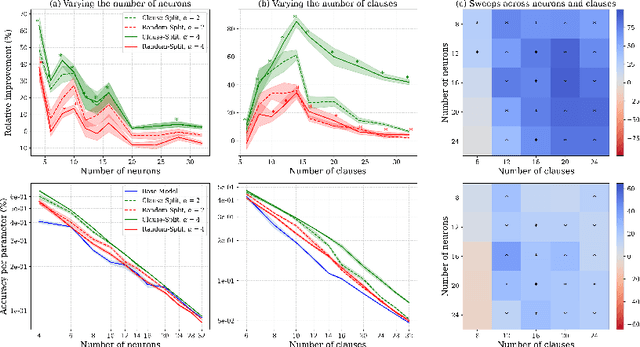
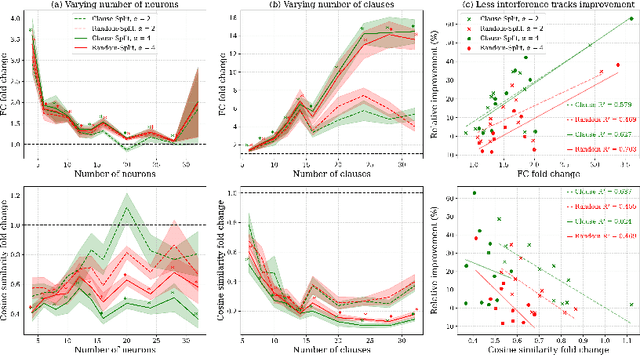
This work demonstrates how increasing the number of neurons in a network without increasing its number of non-zero parameters improves performance. We show that this gain corresponds with a decrease in interference between multiple features that would otherwise share the same neurons. To reduce such entanglement at a fixed non-zero parameter count, we introduce Fixed Parameter Expansion (FPE): replace a neuron with multiple children and partition the parent's weights disjointly across them, so that each child inherits a non-overlapping subset of connections. On symbolic tasks, specifically Boolean code problems, clause-aligned FPE systematically reduces polysemanticity metrics and yields higher task accuracy. Notably, random splits of neuron weights approximate these gains, indicating that reduced collisions, not precise assignment, are a primary driver. Consistent with the superposition hypothesis, the benefits of FPE grow with increasing interference: when polysemantic load is high, accuracy improvements are the largest. Transferring these insights to real models (classifiers over CLIP embeddings and deeper multilayer networks) we find that widening networks while maintaining a constant non-zero parameter count consistently increases accuracy. These results identify an interpretability-grounded mechanism to leverage width against superposition, improving performance without increasing the number of non-zero parameters. Such a direction is well matched to modern accelerators, where memory movement of non-zero parameters, rather than raw compute, is the dominant bottleneck.
The Birth of Knowledge: Emergent Features across Time, Space, and Scale in Large Language Models
May 26, 2025
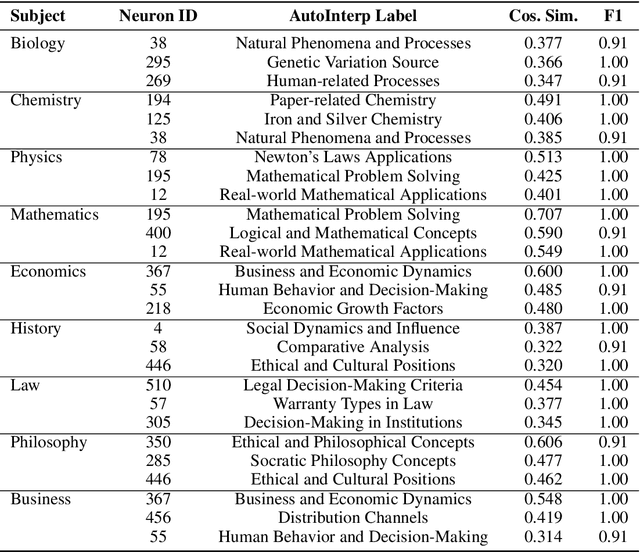

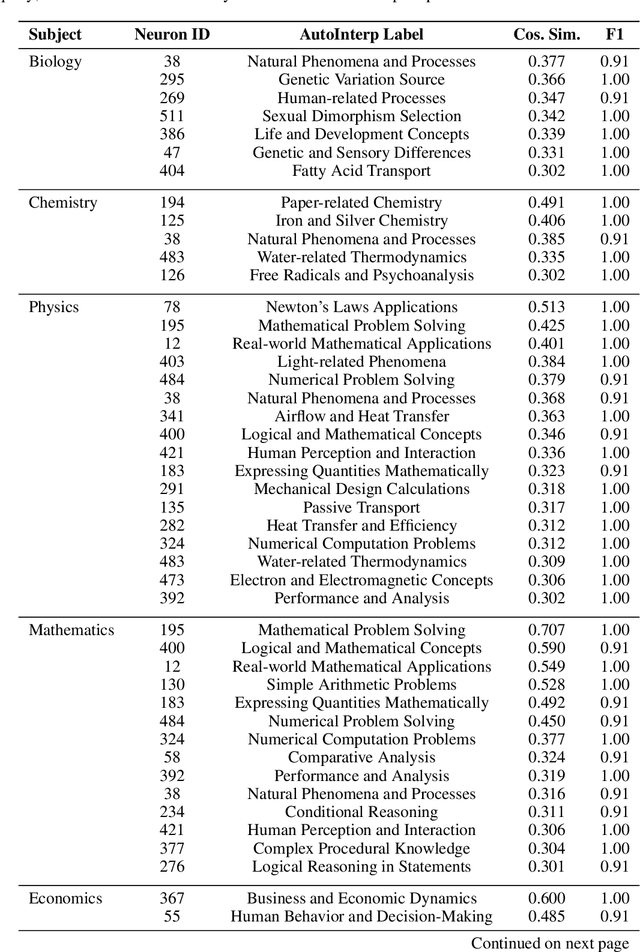
This paper studies the emergence of interpretable categorical features within large language models (LLMs), analyzing their behavior across training checkpoints (time), transformer layers (space), and varying model sizes (scale). Using sparse autoencoders for mechanistic interpretability, we identify when and where specific semantic concepts emerge within neural activations. Results indicate clear temporal and scale-specific thresholds for feature emergence across multiple domains. Notably, spatial analysis reveals unexpected semantic reactivation, with early-layer features re-emerging at later layers, challenging standard assumptions about representational dynamics in transformer models.
Cascade Detector Analysis and Application to Biomedical Microscopy
Apr 30, 2025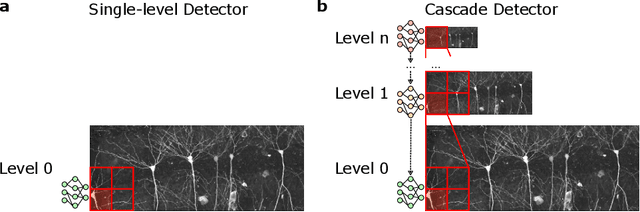
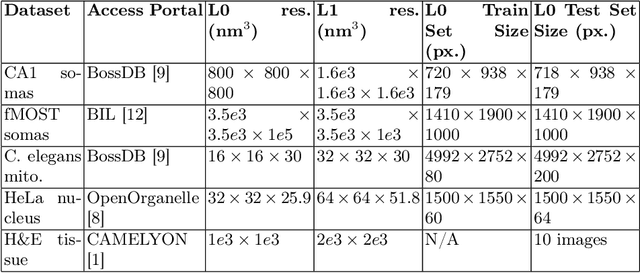
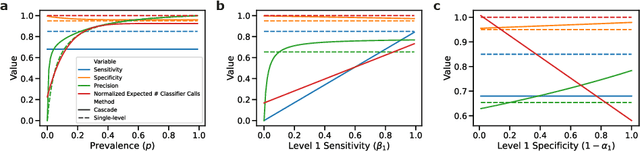

As both computer vision models and biomedical datasets grow in size, there is an increasing need for efficient inference algorithms. We utilize cascade detectors to efficiently identify sparse objects in multiresolution images. Given an object's prevalence and a set of detectors at different resolutions with known accuracies, we derive the accuracy, and expected number of classifier calls by a cascade detector. These results generalize across number of dimensions and number of cascade levels. Finally, we compare one- and two-level detectors in fluorescent cell detection, organelle segmentation, and tissue segmentation across various microscopy modalities. We show that the multi-level detector achieves comparable performance in 30-75% less time. Our work is compatible with a variety of computer vision models and data domains.
Towards Combinatorial Interpretability of Neural Computation
Apr 10, 2025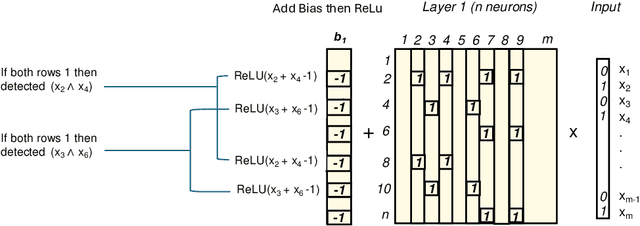

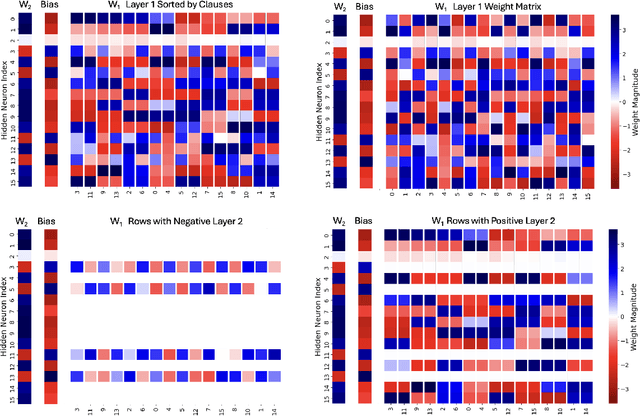
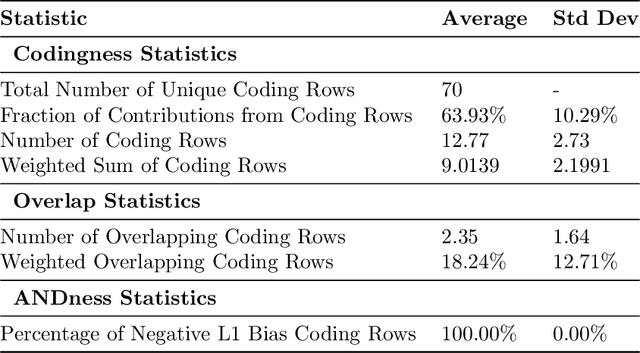
We introduce combinatorial interpretability, a methodology for understanding neural computation by analyzing the combinatorial structures in the sign-based categorization of a network's weights and biases. We demonstrate its power through feature channel coding, a theory that explains how neural networks compute Boolean expressions and potentially underlies other categories of neural network computation. According to this theory, features are computed via feature channels: unique cross-neuron encodings shared among the inputs the feature operates on. Because different feature channels share neurons, the neurons are polysemantic and the channels interfere with one another, making the computation appear inscrutable. We show how to decipher these computations by analyzing a network's feature channel coding, offering complete mechanistic interpretations of several small neural networks that were trained with gradient descent. Crucially, this is achieved via static combinatorial analysis of the weight matrices, without examining activations or training new autoencoding networks. Feature channel coding reframes the superposition hypothesis, shifting the focus from neuron activation directionality in high-dimensional space to the combinatorial structure of codes. It also allows us for the first time to exactly quantify and explain the relationship between a network's parameter size and its computational capacity (i.e. the set of features it can compute with low error), a relationship that is implicitly at the core of many modern scaling laws. Though our initial studies of feature channel coding are restricted to Boolean functions, we believe they provide a rich, controlled, and informative research space, and that the path we propose for combinatorial interpretation of neural computation can provide a basis for understanding both artificial and biological neural circuits.
NeuroADDA: Active Discriminative Domain Adaptation in Connectomic
Mar 08, 2025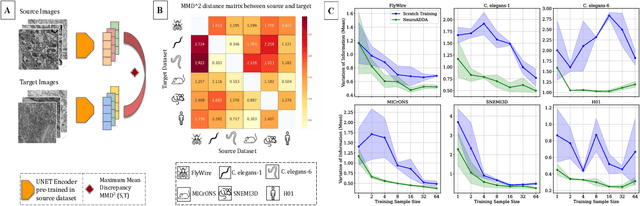


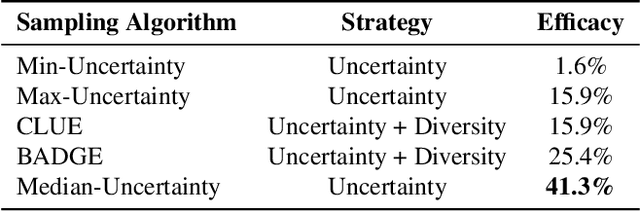
Training segmentation models from scratch has been the standard approach for new electron microscopy connectomics datasets. However, leveraging pretrained models from existing datasets could improve efficiency and performance in constrained annotation budget. In this study, we investigate domain adaptation in connectomics by analyzing six major datasets spanning different organisms. We show that, Maximum Mean Discrepancy (MMD) between neuron image distributions serves as a reliable indicator of transferability, and identifies the optimal source domain for transfer learning. Building on this, we introduce NeuroADDA, a method that combines optimal domain selection with source-free active learning to effectively adapt pretrained backbones to a new dataset. NeuroADDA consistently outperforms training from scratch across diverse datasets and fine-tuning sample sizes, with the largest gain observed at $n=4$ samples with a 25-67\% reduction in Variation of Information. Finally, we show that our analysis of distributional differences among neuron images from multiple species in a learned feature space reveals that these domain "distances" correlate with phylogenetic distance among those species.
Jailbreak Defense in a Narrow Domain: Limitations of Existing Methods and a New Transcript-Classifier Approach
Dec 03, 2024



Defending large language models against jailbreaks so that they never engage in a broadly-defined set of forbidden behaviors is an open problem. In this paper, we investigate the difficulty of jailbreak-defense when we only want to forbid a narrowly-defined set of behaviors. As a case study, we focus on preventing an LLM from helping a user make a bomb. We find that popular defenses such as safety training, adversarial training, and input/output classifiers are unable to fully solve this problem. In pursuit of a better solution, we develop a transcript-classifier defense which outperforms the baseline defenses we test. However, our classifier defense still fails in some circumstances, which highlights the difficulty of jailbreak-defense even in a narrow domain.
Sparse Expansion and Neuronal Disentanglement
May 24, 2024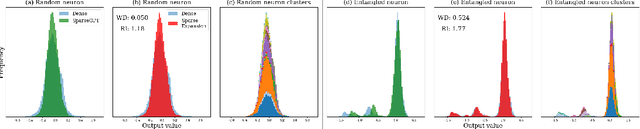
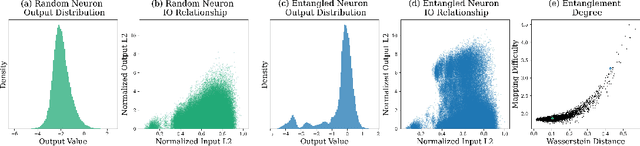
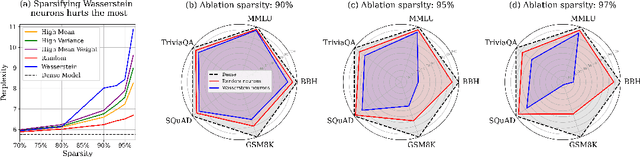
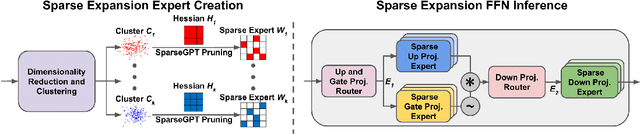
We show how to improve the inference efficiency of an LLM by expanding it into a mixture of sparse experts, where each expert is a copy of the original weights, one-shot pruned for a specific cluster of input values. We call this approach $\textit{Sparse Expansion}$. We show that, for models such as Llama 2 70B, as we increase the number of sparse experts, Sparse Expansion outperforms all other one-shot sparsification approaches for the same inference FLOP budget per token, and that this gap grows as sparsity increases, leading to inference speedups. But why? To answer this, we provide strong evidence that the mixture of sparse experts is effectively $\textit{disentangling}$ the input-output relationship of every individual neuron across clusters of inputs. Specifically, sparse experts approximate the dense neuron output distribution with fewer weights by decomposing the distribution into a collection of simpler ones, each with a separate sparse dot product covering it. Interestingly, we show that the Wasserstein distance between a neuron's output distribution and a Gaussian distribution is an indicator of its entanglement level and contribution to the accuracy of the model. Every layer of an LLM has a fraction of highly entangled Wasserstein neurons, and model performance suffers more when these are sparsified as opposed to others.