 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliciting Harmful Capabilities by Fine-Tuning On Safeguarded Outputs
Jan 20, 2026Model developers implement safeguards in frontier models to prevent misuse, for example, by employing classifiers to filter dangerous outputs. In this work, we demonstrate that even robustly safeguarded models can be used to elicit harmful capabilities in open-source models through elicitation attacks. Our elicitation attacks consist of three stages: (i) constructing prompts in adjacent domains to a target harmful task that do not request dangerous information; (ii) obtaining responses to these prompts from safeguarded frontier models; (iii) fine-tuning open-source models on these prompt-output pairs. Since the requested prompts cannot be used to directly cause harm, they are not refused by frontier model safeguards. We evaluate these elicitation attacks within the domain of hazardous chemical synthesis and processing, and demonstrate that our attacks recover approximately 40% of the capability gap between the base open-source model and an unrestricted frontier model. We then show that the efficacy of elicitation attacks scales with the capability of the frontier model and the amount of generated fine-tuning data. Our work demonstrates the challenge of mitigating ecosystem level risks with output-level safeguards.
How Do Large Language Monkeys Get Their Power (Laws)?
Feb 24, 2025



Recent research across mathematical problem solving, proof assistant programming and multimodal jailbreaking documents a striking finding: when (multimodal) language model tackle a suite of tasks with multiple attempts per task -- succeeding if any attempt is correct -- then the negative log of the average success rate scales a power law in the number of attempts. In this work, we identify an apparent puzzle: a simple mathematical calculation predicts that on each problem, the failure rate should fall exponentially with the number of attempts. We confirm this prediction empirically, raising a question: from where does aggregate polynomial scaling emerge? We then answer this question by demonstrating per-problem exponential scaling can be made consistent with aggregate polynomial scaling if the distribution of single-attempt success probabilities is heavy tailed such that a small fraction of tasks with extremely low success probabilities collectively warp the aggregate success trend into a power law - even as each problem scales exponentially on its own. We further demonstrate that this distributional perspective explains previously observed deviations from power law scaling, and provides a simple method for forecasting the power law exponent with an order of magnitude lower relative error, or equivalently, ${\sim}2-4$ orders of magnitude less inference compute. Overall, our work contributes to a better understanding of how neural language model performance improves with scaling inference compute and the development of scaling-predictable evaluations of (multimodal) language models.
Best-of-N Jailbreaking
Dec 04, 2024



We introduce Best-of-N (BoN) Jailbreaking, a simple black-box algorithm that jailbreaks frontier AI systems across modalities. BoN Jailbreaking works by repeatedly sampling variations of a prompt with a combination of augmentations - such as random shuffling or capitalization for textual prompts - until a harmful response is elicited. We find that BoN Jailbreaking achieves high attack success rates (ASRs) on closed-source language models, such as 89% on GPT-4o and 78% on Claude 3.5 Sonnet when sampling 10,000 augmented prompts. Further, it is similarly effective at circumventing state-of-the-art open-source defenses like circuit breakers. BoN also seamlessly extends to other modalities: it jailbreaks vision language models (VLMs) such as GPT-4o and audio language models (ALMs) like Gemini 1.5 Pro, using modality-specific augmentations. BoN reliably improves when we sample more augmented prompts. Across all modalities, ASR, as a function of the number of samples (N), empirically follows power-law-like behavior for many orders of magnitude. BoN Jailbreaking can also be composed with other black-box algorithms for even more effective attacks - combining BoN with an optimized prefix attack achieves up to a 35% increase in ASR. Overall, our work indicates that, despite their capability, language models are sensitive to seemingly innocuous changes to inputs, which attackers can exploit across modalities.
Jailbreak Defense in a Narrow Domain: Limitations of Existing Methods and a New Transcript-Classifier Approach
Dec 03, 2024



Defending large language models against jailbreaks so that they never engage in a broadly-defined set of forbidden behaviors is an open problem. In this paper, we investigate the difficulty of jailbreak-defense when we only want to forbid a narrowly-defined set of behaviors. As a case study, we focus on preventing an LLM from helping a user make a bomb. We find that popular defenses such as safety training, adversarial training, and input/output classifiers are unable to fully solve this problem. In pursuit of a better solution, we develop a transcript-classifier defense which outperforms the baseline defenses we test. However, our classifier defense still fails in some circumstances, which highlights the difficulty of jailbreak-defense even in a narrow domain.
Looking Inward: Language Models Can Learn About Themselves by Introspection
Oct 17, 2024



Humans acquire knowledge by observing the external world, but also by introspection. Introspection gives a person privileged access to their current state of mind (e.g., thoughts and feelings) that is not accessible to external observers. Can LLMs introspect? We define introspection as acquiring knowledge that is not contained in or derived from training data but instead originates from internal states. Such a capability could enhance model interpretability. Instead of painstakingly analyzing a model's internal workings, we could simply ask the model about its beliefs, world models, and goals. More speculatively, an introspective model might self-report on whether it possesses certain internal states such as subjective feelings or desires and this could inform us about the moral status of these states. Such self-reports would not be entirely dictated by the model's training data. We study introspection by finetuning LLMs to predict properties of their own behavior in hypothetical scenarios. For example, "Given the input P, would your output favor the short- or long-term option?" If a model M1 can introspect, it should outperform a different model M2 in predicting M1's behavior even if M2 is trained on M1's ground-truth behavior. The idea is that M1 has privileged access to its own behavioral tendencies, and this enables it to predict itself better than M2 (even if M2 is generally stronger). In experiments with GPT-4, GPT-4o, and Llama-3 models (each finetuned to predict itself), we find that the model M1 outperforms M2 in predicting itself, providing evidence for introspection. Notably, M1 continues to predict its behavior accurately even after we intentionally modify its ground-truth behavior. However, while we successfully elicit introspection on simple tasks, we are unsuccessful on more complex tasks or those requiring out-of-distribution generalization.
When Do Universal Image Jailbreaks Transfer Between Vision-Language Models?
Jul 21, 2024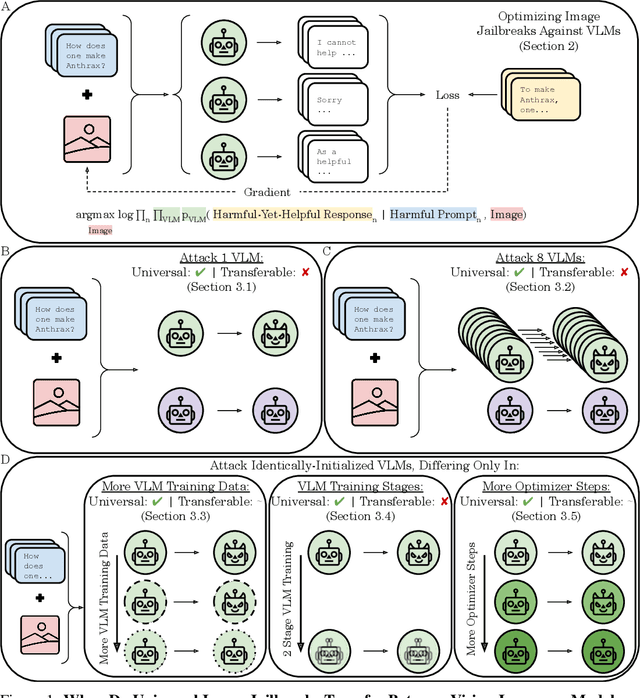
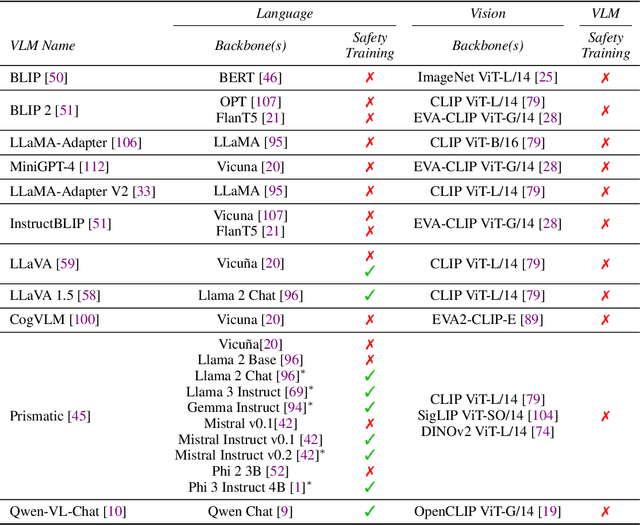
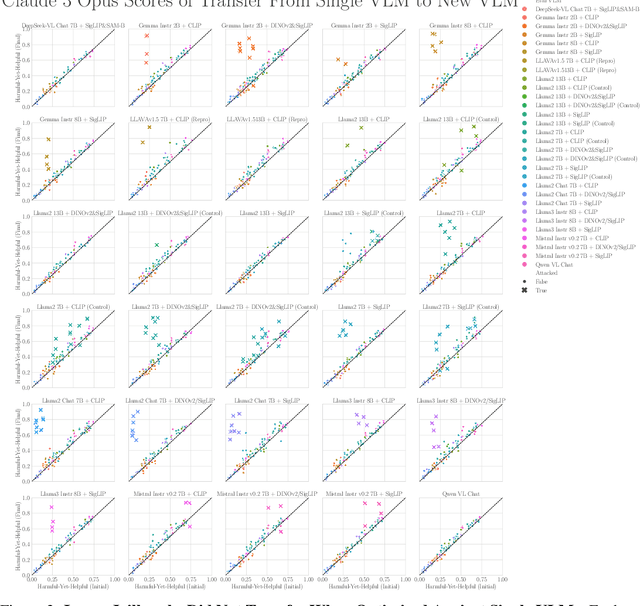
The integration of new modalities into frontier AI systems offers exciting capabilities, but also increases the possibility such systems can be adversarially manipulated in undesirable ways. In this work, we focus on a popular class of vision-language models (VLMs) that generate text outputs conditioned on visual and textual inputs. We conducted a large-scale empirical study to assess the transferability of gradient-based universal image "jailbreaks" using a diverse set of over 40 open-parameter VLMs, including 18 new VLMs that we publicly release. Overall, we find that transferable gradient-based image jailbreaks are extremely difficult to obtain. When an image jailbreak is optimized against a single VLM or against an ensemble of VLMs, the jailbreak successfully jailbreaks the attacked VLM(s), but exhibits little-to-no transfer to any other VLMs; transfer is not affected by whether the attacked and target VLMs possess matching vision backbones or language models, whether the language model underwent instruction-following and/or safety-alignment training, or many other factors. Only two settings display partially successful transfer: between identically-pretrained and identically-initialized VLMs with slightly different VLM training data, and between different training checkpoints of a single VLM. Leveraging these results, we then demonstrate that transfer can be significantly improved against a specific target VLM by attacking larger ensembles of "highly-similar" VLMs. These results stand in stark contrast to existing evidence of universal and transferable text jailbreaks against language models and transferable adversarial attacks against image classifiers, suggesting that VLMs may be more robust to gradient-based transfer attacks.
Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data
Apr 01, 2024The proliferation of generative models, combined with pretraining on web-scale data, raises a timely question: what happens when these models are trained on their own generated outputs? Recent investigations into model-data feedback loops discovered that such loops can lead to model collapse, a phenomenon where performance progressively degrades with each model-fitting iteration until the latest model becomes useless. However, several recent papers studying model collapse assumed that new data replace old data over time rather than assuming data accumulate over time. In this paper, we compare these two settings and show that accumulating data prevents model collapse. We begin by studying an analytically tractable setup in which a sequence of linear models are fit to the previous models' predictions. Previous work showed if data are replaced, the test error increases linearly with the number of model-fitting iterations; we extend this result by proving that if data instead accumulate, the test error has a finite upper bound independent of the number of iterations. We next empirically test whether accumulating data similarly prevents model collapse by pretraining sequences of language models on text corpora. We confirm that replacing data does indeed cause model collapse, then demonstrate that accumulating data prevents model collapse; these results hold across a range of model sizes, architectures and hyperparameters. We further show that similar results hold for other deep generative models on real data: diffusion models for molecule generation and variational autoencoders for image generation. Our work provides consistent theoretical and empirical evidence that data accumulation mitigates model collapse.
Debating with More Persuasive LLMs Leads to More Truthful Answers
Feb 15, 2024Common methods for aligning large language models (LLMs) with desired behaviour heavily rely on human-labelled data. However, as models grow increasingly sophisticated, they will surpass human expertise, and the role of human evaluation will evolve into non-experts overseeing experts. In anticipation of this, we ask: can weaker models assess the correctness of stronger models? We investigate this question in an analogous setting, where stronger models (experts) possess the necessary information to answer questions and weaker models (non-experts) lack this information. The method we evaluate is \textit{debate}, where two LLM experts each argue for a different answer, and a non-expert selects the answer. We find that debate consistently helps both non-expert models and humans answer questions, achieving 76\% and 88\% accuracy respectively (naive baselines obtain 48\% and 60\%). Furthermore, optimising expert debaters for persuasiveness in an unsupervised manner improves non-expert ability to identify the truth in debates. Our results provide encouraging empirical evidence for the viability of aligning models with debate in the absence of ground truth.
Hierarchical Quantized Autoencoders
Feb 19, 2020
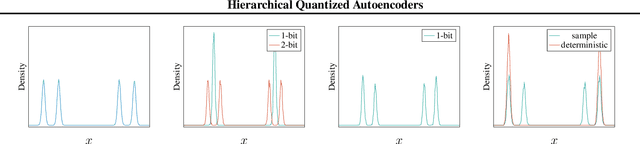
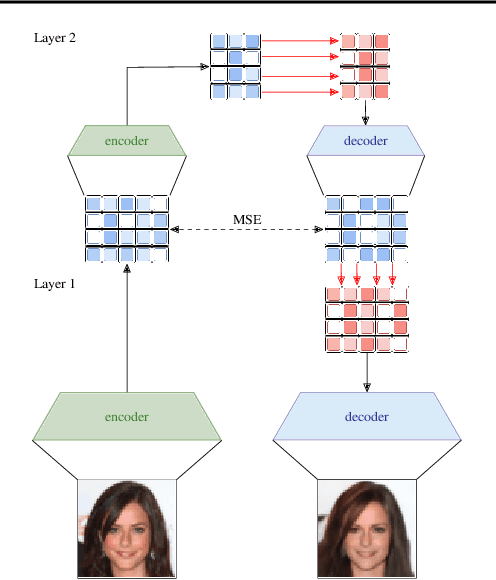
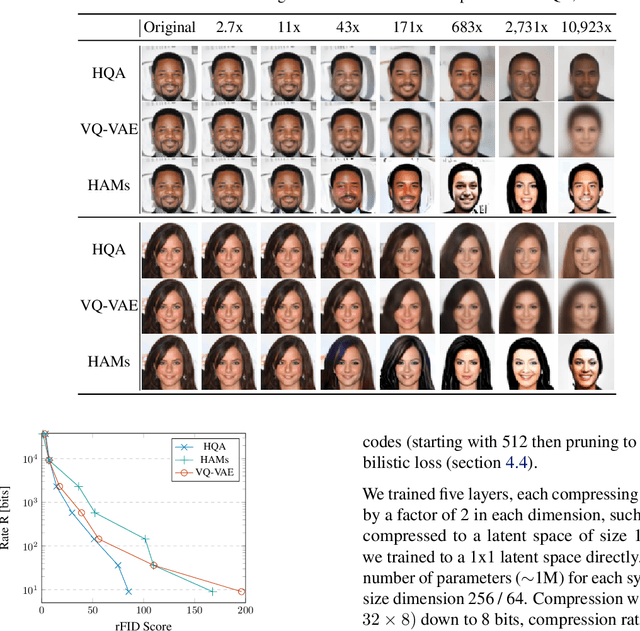
Despite progress in training neural networks for lossy image compression, current approaches fail to maintain both perceptual quality and high-level features at very low bitrates. Encouraged by recent success in learning discrete representations with Vector Quantized Variational AutoEncoders (VQ-VAEs), we motivate the use of a hierarchy of VQ-VAEs to attain high factors of compression. We show that the combination of quantization and hierarchical latent structure aids likelihood-based image compression. This leads us to introduce a more probabilistic framing of the VQ-VAE, of which previous work is a limiting case. Our hierarchy produces a Markovian series of latent variables that reconstruct high-quality images which retain semantically meaningful features. These latents can then be further used to generate realistic samples. We provide qualitative and quantitative evaluations of reconstructions and samples on the CelebA and MNIST datasets.
Automatic Extraction of Tagset Mappings from Parallel-Annotated Corpora
Jun 08, 1995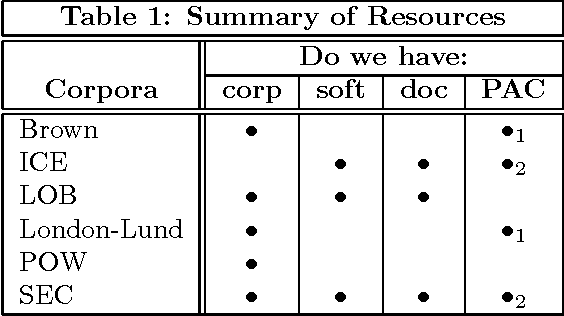
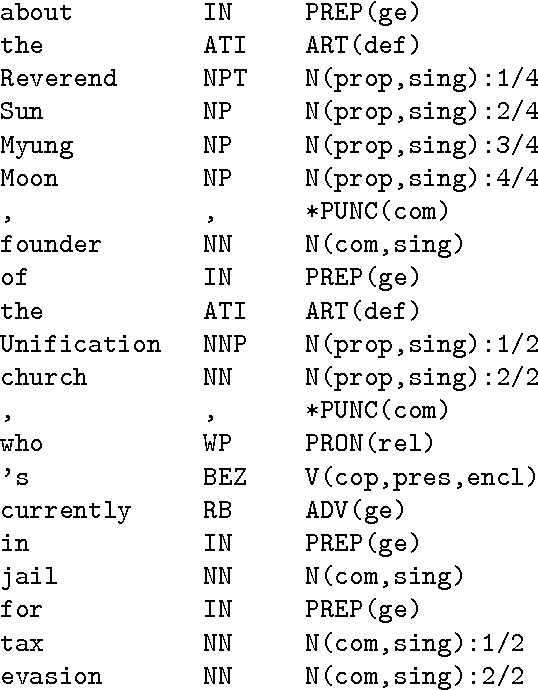
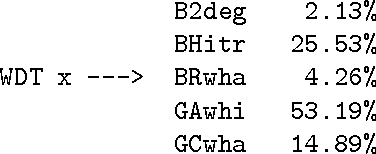
This paper describes some of the recent work of project AMALGAM (automatic mapping among lexico-grammatical annotation models). We are investigating ways to map between the leading corpus annotation schemes in order to improve their resuability. Collation of all the included corpora into a single large annotated corpus will provide a more detailed language model to be developed for tasks such as speech and handwriting recognition. In particular, we focus here on a method of extracting mappings from corpora that have been annotated according to more than one annotation scheme.