 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Analysis of Speech Self-Supervised Learning at Multiple Resolutions
Oct 31, 2024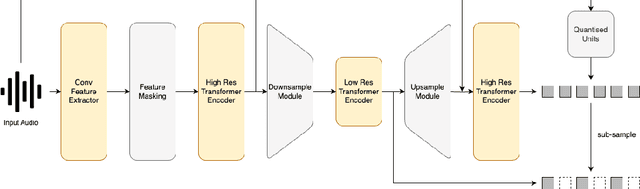
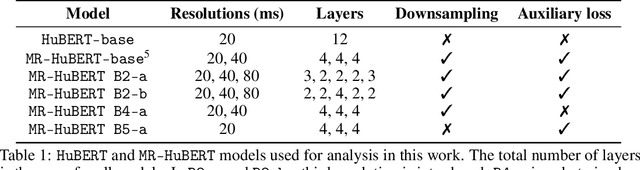
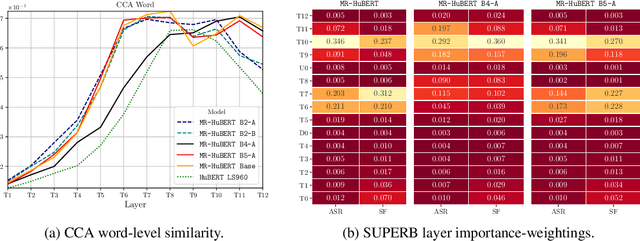

Self-supervised learning (SSL) models have become crucial in speech processing, with recent advancements concentrating on developing architectures that capture representations across multiple timescales. The primary goal of these multi-scale architectures is to exploit the hierarchical nature of speech, where lower-resolution components aim to capture representations that align with increasingly abstract concepts (e.g., from phones to words to sentences). Although multi-scale approaches have demonstrated some improvements over single-scale models, the precise reasons for these enhancements have poor empirical support. In this study, we present an initial analysis of layer-wise representations in multi-scale architectures, with a focus on Canonical Correlation Analysis (CCA) and Mutual Information (MI). We apply this analysis to Multi-Resolution HuBERT (MR-HuBERT) and find that (1) the improved performance on SUPERB tasks is primarily due to the auxiliary low-resolution loss rather than the downsampling itself, and (2) downsampling to lower resolutions neither improves downstream performance nor correlates with higher-level information (e.g., words), though it does improve computational efficiency. These findings challenge assumptions about the multi-scale nature of MR-HuBERT and motivate the importance of disentangling computational efficiency from learning better representations.
Hierarchical Quantized Autoencoders
Feb 19, 2020
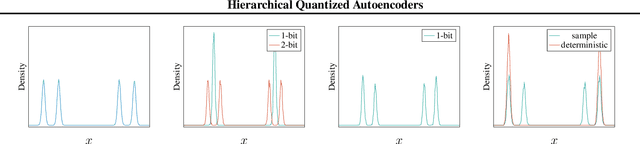
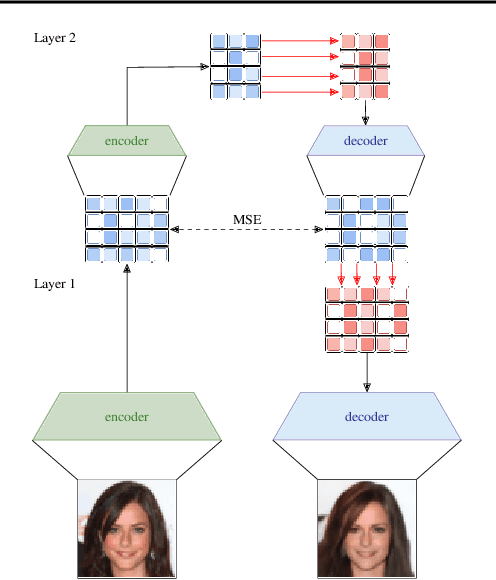
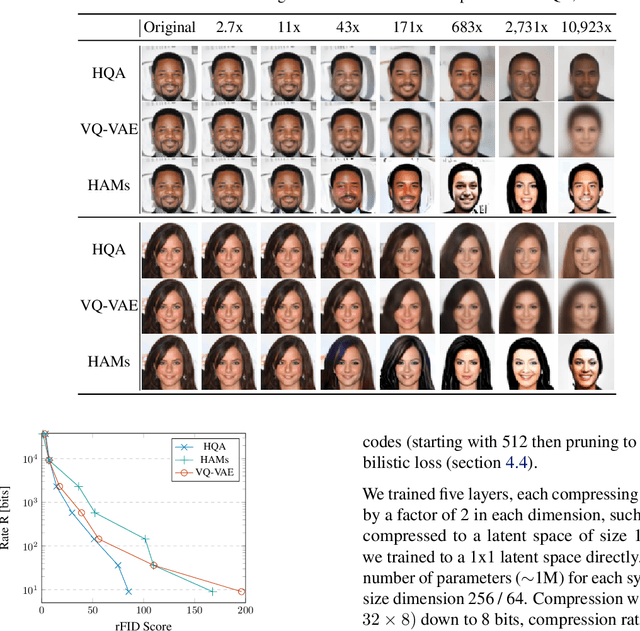
Despite progress in training neural networks for lossy image compression, current approaches fail to maintain both perceptual quality and high-level features at very low bitrates. Encouraged by recent success in learning discrete representations with Vector Quantized Variational AutoEncoders (VQ-VAEs), we motivate the use of a hierarchy of VQ-VAEs to attain high factors of compression. We show that the combination of quantization and hierarchical latent structure aids likelihood-based image compression. This leads us to introduce a more probabilistic framing of the VQ-VAE, of which previous work is a limiting case. Our hierarchy produces a Markovian series of latent variables that reconstruct high-quality images which retain semantically meaningful features. These latents can then be further used to generate realistic samples. We provide qualitative and quantitative evaluations of reconstructions and samples on the CelebA and MNIST datasets.