 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Quantized Autoencoders
Feb 19, 2020
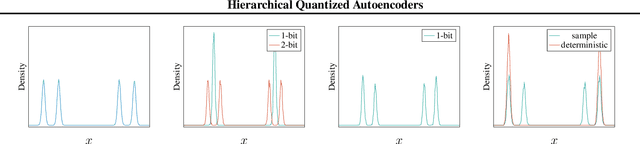
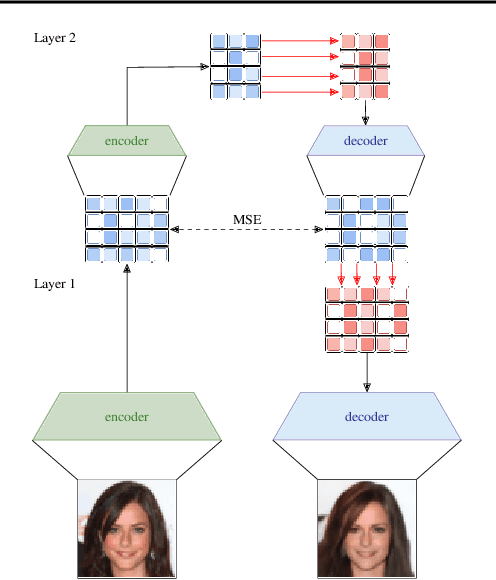
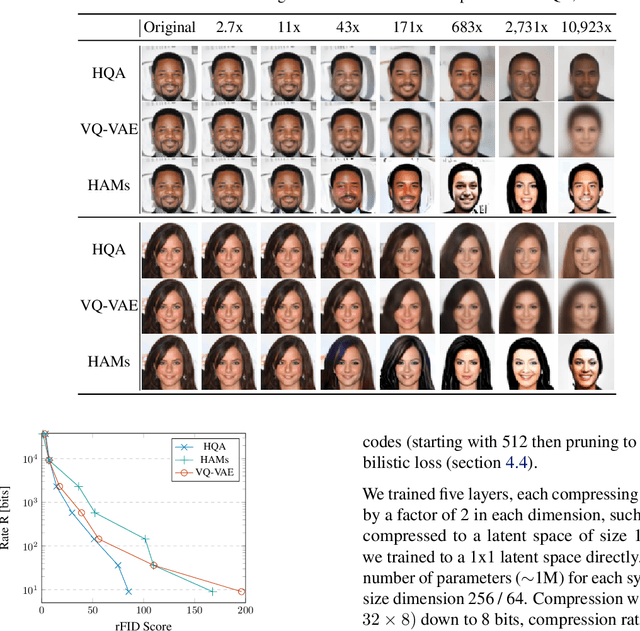
Despite progress in training neural networks for lossy image compression, current approaches fail to maintain both perceptual quality and high-level features at very low bitrates. Encouraged by recent success in learning discrete representations with Vector Quantized Variational AutoEncoders (VQ-VAEs), we motivate the use of a hierarchy of VQ-VAEs to attain high factors of compression. We show that the combination of quantization and hierarchical latent structure aids likelihood-based image compression. This leads us to introduce a more probabilistic framing of the VQ-VAE, of which previous work is a limiting case. Our hierarchy produces a Markovian series of latent variables that reconstruct high-quality images which retain semantically meaningful features. These latents can then be further used to generate realistic samples. We provide qualitative and quantitative evaluations of reconstructions and samples on the CelebA and MNIST datasets.
Texture Bias Of CNNs Limits Few-Shot Classification Performance
Oct 18, 2019
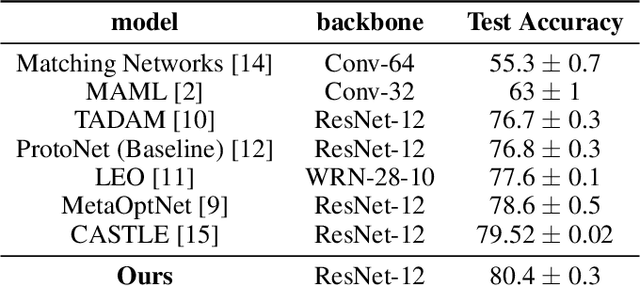

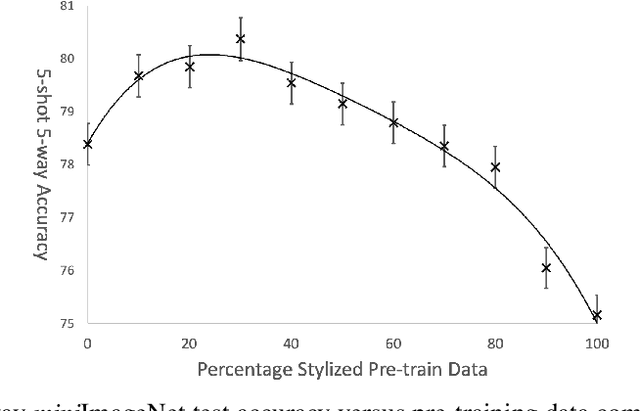
Accurate image classification given small amounts of labelled data (few-shot classification) remains an open problem in computer vision. In this work we examine how the known texture bias of Convolutional Neural Networks (CNNs) affects few-shot classification performance. Although texture bias can help in standard image classification, in this work we show it significantly harms few-shot classification performance. After correcting this bias we demonstrate state-of-the-art performance on the competitive miniImageNet task using a method far simpler than the current best performing few-shot learning approaches.
Discriminative training of RNNLMs with the average word error criterion
Nov 08, 2018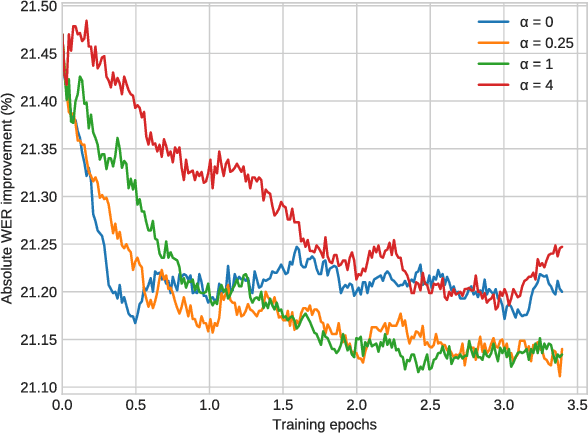
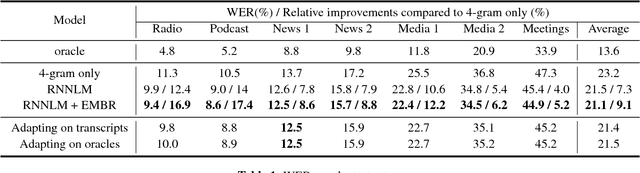
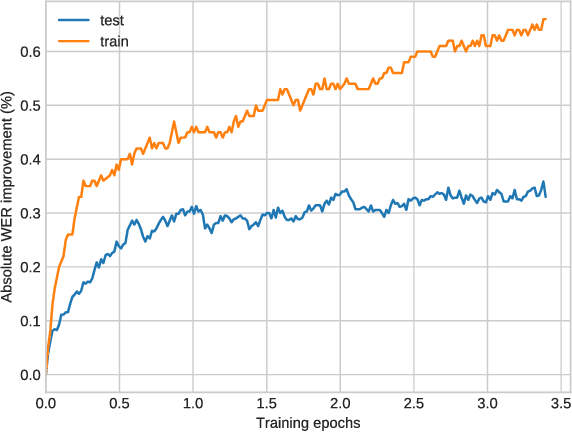
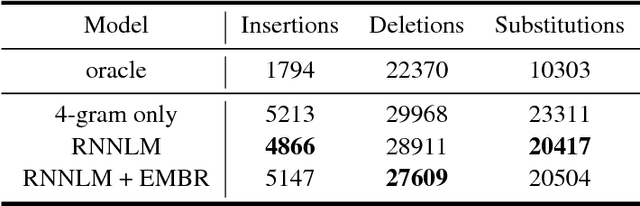
In automatic speech recognition (ASR), recurrent neural language models (RNNLM) are typically used to refine hypotheses in the form of lattices or n-best lists, which are generated by a beam search decoder with a weaker language model. The RNNLMs are usually trained generatively using the perplexity (PPL) criterion on large corpora of grammatically correct text. However, the hypotheses are noisy, and the RNNLM doesn't always make the choices that minimise the metric we optimise for, the word error rate (WER). To address this mismatch we propose to use a task specific loss to train an RNNLM to discriminate between multiple hypotheses within lattice rescoring scenario. By fine-tuning the RNNLM on lattices with the average edit distance loss, we show that we obtain a 1.9% relative improvement in word error rate over a purely generatively trained model.
Scaling Recurrent Neural Network Language Models
Feb 02, 2015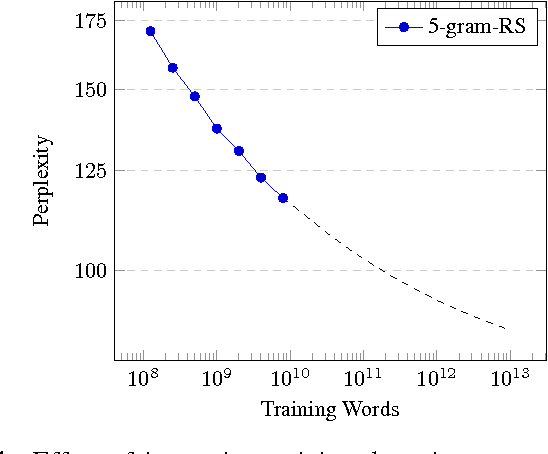
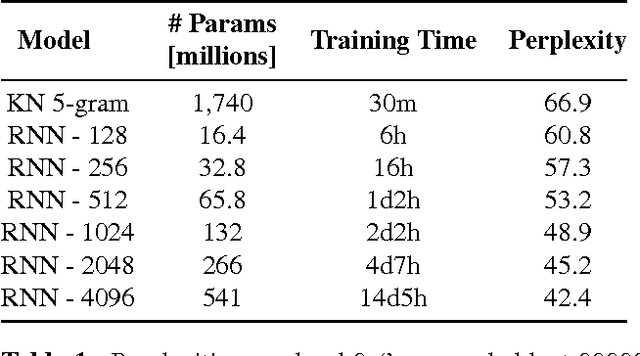
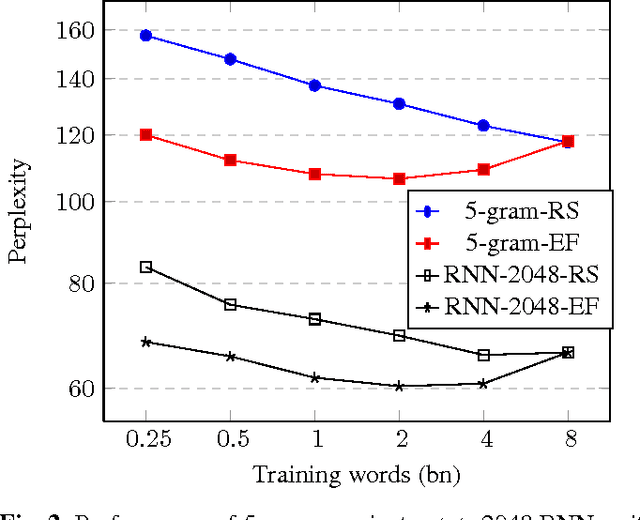
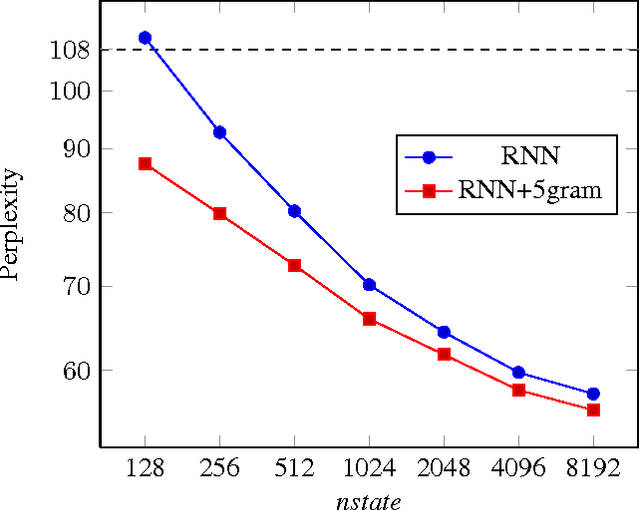
This paper investigates the scaling properties of Recurrent Neural Network Language Models (RNNLMs). We discuss how to train very large RNNs on GPUs and address the questions of how RNNLMs scale with respect to model size, training-set size, computational costs and memory. Our analysis shows that despite being more costly to train, RNNLMs obtain much lower perplexities on standard benchmarks than n-gram models. We train the largest known RNNs and present relative word error rates gains of 18% on an ASR task. We also present the new lowest perplexities on the recently released billion word language modelling benchmark, 1 BLEU point gain on machine translation and a 17% relative hit rate gain in word prediction.