 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Transformers Use their Depth Adaptively? Evidence from a Relational Reasoning Task
Apr 14, 2026We investigate whether transformers use their depth adaptively across tasks of increasing difficulty. Using a controlled multi-hop relational reasoning task based on family stories, where difficulty is determined by the number of relationship hops that must be composed, we monitor (i) how predictions evolve across layers via early readouts (the logit lens) and (ii) how task-relevant information is integrated across tokens via causal patching. For pretrained models, we find some limited evidence for adaptive depth use: some larger models need fewer layers to arrive at plausible answers for easier tasks, and models generally use more layers to integrate information across tokens as chain length increases. For models finetuned on the task, we find clearer and more consistent evidence of adaptive depth use, with the effect being stronger for less constrained finetuning regimes that do not preserve general language modeling abilities.
Better Think Thrice: Learning to Reason Causally with Double Counterfactual Consistency
Feb 18, 2026Despite their strong performance on reasoning benchmarks, large language models (LLMs) have proven brittle when presented with counterfactual questions, suggesting weaknesses in their causal reasoning ability. While recent work has demonstrated that labeled counterfactual tasks can be useful benchmarks of LLMs' causal reasoning, producing such data at the scale required to cover the vast potential space of counterfactuals is limited. In this work, we introduce double counterfactual consistency (DCC), a lightweight inference-time method for measuring and guiding the ability of LLMs to reason causally. Without requiring labeled counterfactual data, DCC verifies a model's ability to execute two important elements of causal reasoning: causal intervention and counterfactual prediction. Using DCC, we evaluate the causal reasoning abilities of various leading LLMs across a range of reasoning tasks and interventions. Moreover, we demonstrate the effectiveness of DCC as a training-free test-time rejection sampling criterion and show that it can directly improve performance on reasoning tasks across multiple model families.
AIRIVA: A Deep Generative Model of Adaptive Immune Repertoires
Apr 26, 2023



Recent advances in immunomics have shown that T-cell receptor (TCR) signatures can accurately predict active or recent infection by leveraging the high specificity of TCR binding to disease antigens. However, the extreme diversity of the adaptive immune repertoire presents challenges in reliably identifying disease-specific TCRs. Population genetics and sequencing depth can also have strong systematic effects on repertoires, which requires careful consideration when developing diagnostic models. We present an Adaptive Immune Repertoire-Invariant Variational Autoencoder (AIRIVA), a generative model that learns a low-dimensional, interpretable, and compositional representation of TCR repertoires to disentangle such systematic effects in repertoires. We apply AIRIVA to two infectious disease case-studies: COVID-19 (natural infection and vaccination) and the Herpes Simplex Virus (HSV-1 and HSV-2), and empirically show that we can disentangle the individual disease signals. We further demonstrate AIRIVA's capability to: learn from unlabelled samples; generate in-silico TCR repertoires by intervening on the latent factors; and identify disease-associated TCRs validated using TCR annotations from external assay data.
Defining Admissible Rewards for High Confidence Policy Evaluation
May 30, 2019

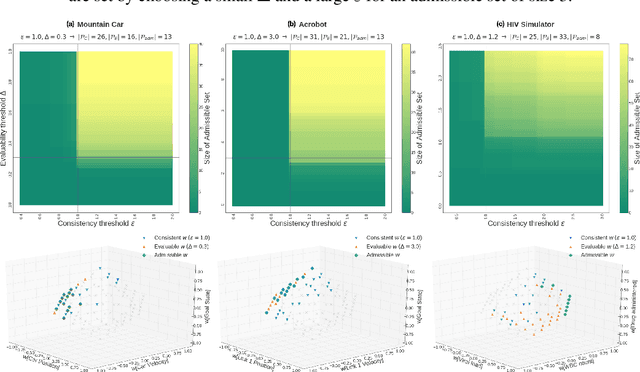

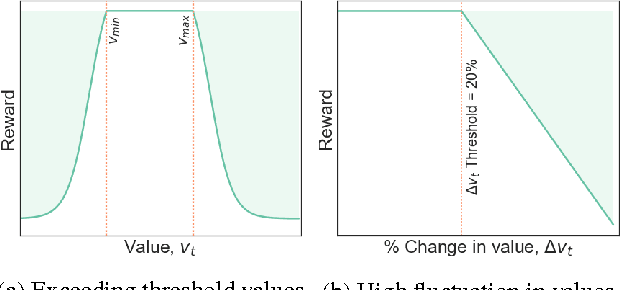
A key impediment to reinforcement learning (RL) in real applications with limited, batch data is defining a reward function that reflects what we implicitly know about reasonable behaviour for a task and allows for robust off-policy evaluation. In this work, we develop a method to identify an admissible set of reward functions for policies that (a) do not diverge too far from past behaviour, and (b) can be evaluated with high confidence, given only a collection of past trajectories. Together, these ensure that we propose policies that we trust to be implemented in high-risk settings. We demonstrate our approach to reward design on synthetic domains as well as in a critical care context, for a reward that consolidates clinical objectives to learn a policy for weaning patients from mechanical ventilation.
An Optimal Policy for Patient Laboratory Tests in Intensive Care Units
Aug 14, 2018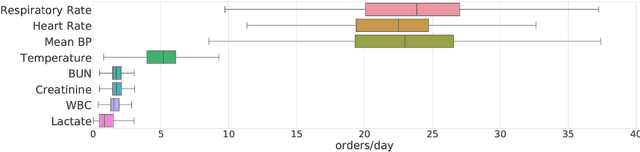
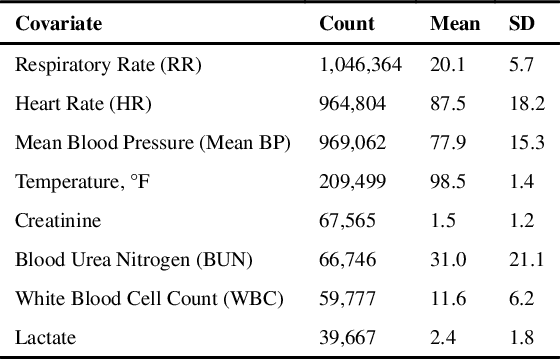
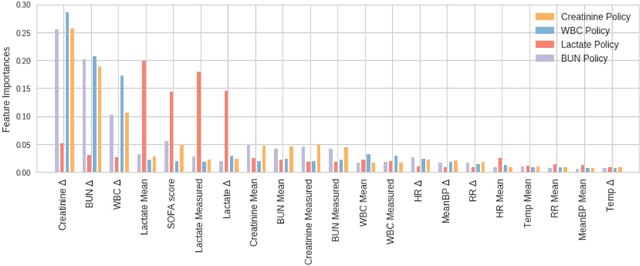
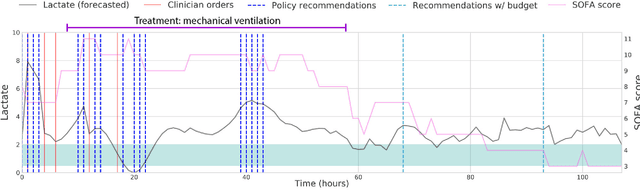
Laboratory testing is an integral tool in the management of patient care in hospitals, particularly in intensive care units (ICUs). There exists an inherent trade-off in the selection and timing of lab tests between considerations of the expected utility in clinical decision-making of a given test at a specific time, and the associated cost or risk it poses to the patient. In this work, we introduce a framework that learns policies for ordering lab tests which optimizes for this trade-off. Our approach uses batch off-policy reinforcement learning with a composite reward function based on clinical imperatives, applied to data that include examples of clinicians ordering labs for patients. To this end, we develop and extend principles of Pareto optimality to improve the selection of actions based on multiple reward function components while respecting typical procedural considerations and prioritization of clinical goals in the ICU. Our experiments show that we can estimate a policy that reduces the frequency of lab tests and optimizes timing to minimize information redundancy. We also find that the estimated policies typically suggest ordering lab tests well ahead of critical onsets--such as mechanical ventilation or dialysis--that depend on the lab results. We evaluate our approach by quantifying how these policies may initiate earlier onset of treatment.
A Reinforcement Learning Approach to Weaning of Mechanical Ventilation in Intensive Care Units
Apr 20, 2017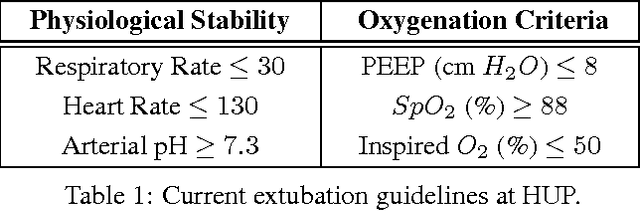
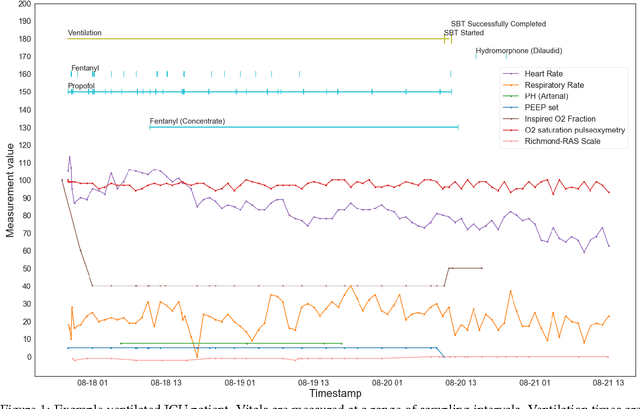
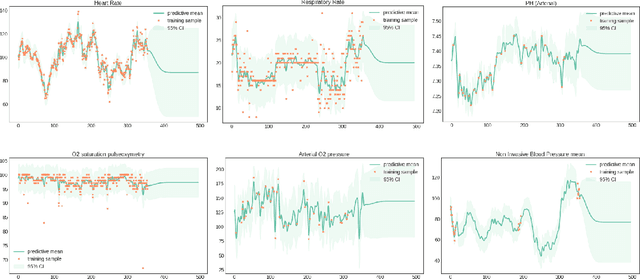
The management of invasive mechanical ventilation, and the regulation of sedation and analgesia during ventilation, constitutes a major part of the care of patients admitted to intensive care units. Both prolonged dependence on mechanical ventilation and premature extubation are associated with increased risk of complications and higher hospital costs, but clinical opinion on the best protocol for weaning patients off of a ventilator varies. This work aims to develop a decision support tool that uses available patient information to predict time-to-extubation readiness and to recommend a personalized regime of sedation dosage and ventilator support. To this end, we use off-policy reinforcement learning algorithms to determine the best action at a given patient state from sub-optimal historical ICU data. We compare treatment policies from fitted Q-iteration with extremely randomized trees and with feedforward neural networks, and demonstrate that the policies learnt show promise in recommending weaning protocols with improved outcomes, in terms of minimizing rates of reintubation and regulating physiological stability.
Scaling Recurrent Neural Network Language Models
Feb 02, 2015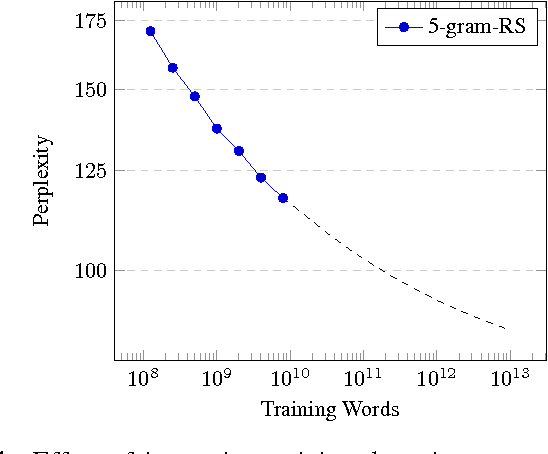
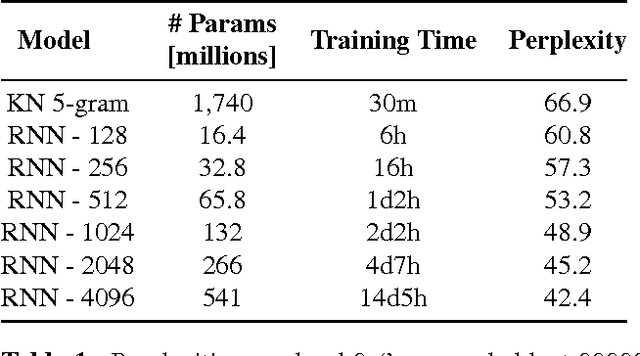
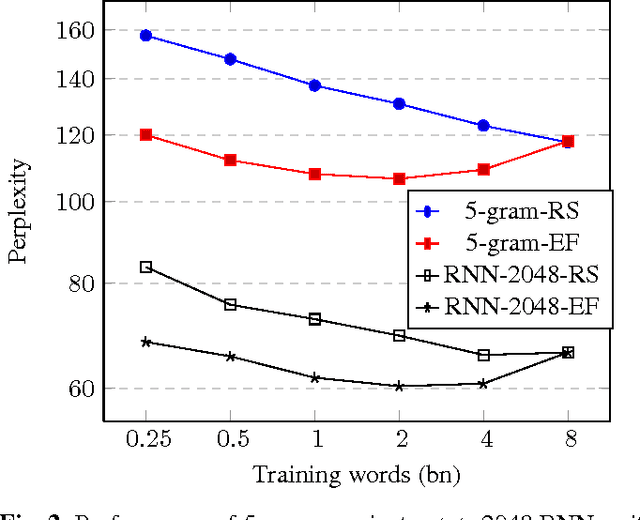
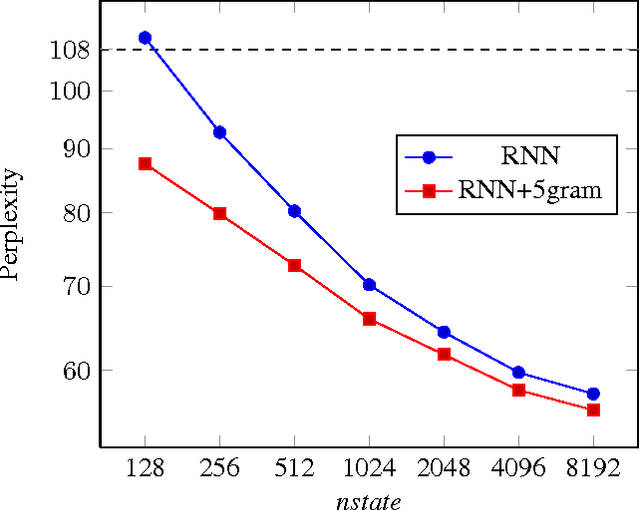
This paper investigates the scaling properties of Recurrent Neural Network Language Models (RNNLMs). We discuss how to train very large RNNs on GPUs and address the questions of how RNNLMs scale with respect to model size, training-set size, computational costs and memory. Our analysis shows that despite being more costly to train, RNNLMs obtain much lower perplexities on standard benchmarks than n-gram models. We train the largest known RNNs and present relative word error rates gains of 18% on an ASR task. We also present the new lowest perplexities on the recently released billion word language modelling benchmark, 1 BLEU point gain on machine translation and a 17% relative hit rate gain in word prediction.