 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Think Thrice: Learning to Reason Causally with Double Counterfactual Consistency
Feb 18, 2026Despite their strong performance on reasoning benchmarks, large language models (LLMs) have proven brittle when presented with counterfactual questions, suggesting weaknesses in their causal reasoning ability. While recent work has demonstrated that labeled counterfactual tasks can be useful benchmarks of LLMs' causal reasoning, producing such data at the scale required to cover the vast potential space of counterfactuals is limited. In this work, we introduce double counterfactual consistency (DCC), a lightweight inference-time method for measuring and guiding the ability of LLMs to reason causally. Without requiring labeled counterfactual data, DCC verifies a model's ability to execute two important elements of causal reasoning: causal intervention and counterfactual prediction. Using DCC, we evaluate the causal reasoning abilities of various leading LLMs across a range of reasoning tasks and interventions. Moreover, we demonstrate the effectiveness of DCC as a training-free test-time rejection sampling criterion and show that it can directly improve performance on reasoning tasks across multiple model families.
Reasoning Beyond Labels: Measuring LLM Sentiment in Low-Resource, Culturally Nuanced Contexts
Aug 06, 2025Sentiment analysis in low-resource, culturally nuanced contexts challenges conventional NLP approaches that assume fixed labels and universal affective expressions. We present a diagnostic framework that treats sentiment as a context-dependent, culturally embedded construct, and evaluate how large language models (LLMs) reason about sentiment in informal, code-mixed WhatsApp messages from Nairobi youth health groups. Using a combination of human-annotated data, sentiment-flipped counterfactuals, and rubric-based explanation evaluation, we probe LLM interpretability, robustness, and alignment with human reasoning. Framing our evaluation through a social-science measurement lens, we operationalize and interrogate LLMs outputs as an instrument for measuring the abstract concept of sentiment. Our findings reveal significant variation in model reasoning quality, with top-tier LLMs demonstrating interpretive stability, while open models often falter under ambiguity or sentiment shifts. This work highlights the need for culturally sensitive, reasoning-aware AI evaluation in complex, real-world communication.
RE-IMAGINE: Symbolic Benchmark Synthesis for Reasoning Evaluation
Jun 18, 2025Recent Large Language Models (LLMs) have reported high accuracy on reasoning benchmarks. However, it is still unclear whether the observed results arise from true reasoning or from statistical recall of the training set. Inspired by the ladder of causation (Pearl, 2009) and its three levels (associations, interventions and counterfactuals), this paper introduces RE-IMAGINE, a framework to characterize a hierarchy of reasoning ability in LLMs, alongside an automated pipeline to generate problem variations at different levels of the hierarchy. By altering problems in an intermediate symbolic representation, RE-IMAGINE generates arbitrarily many problems that are not solvable using memorization alone. Moreover, the framework is general and can work across reasoning domains, including math, code, and logic. We demonstrate our framework on four widely-used benchmarks to evaluate several families of LLMs, and observe reductions in performance when the models are queried with problem variations. These assessments indicate a degree of reliance on statistical recall for past performance, and open the door to further research targeting skills across the reasoning hierarchy.
Compositional Causal Reasoning Evaluation in Language Models
Mar 06, 2025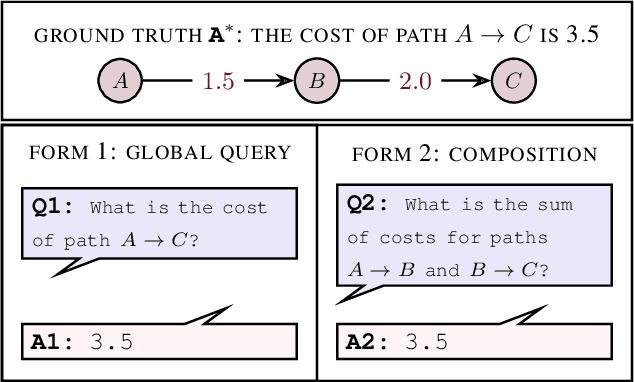

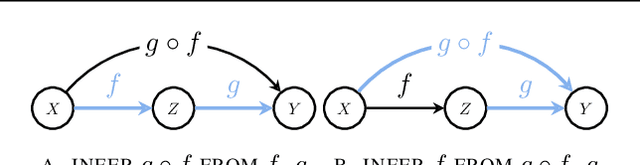

Causal reasoning and compositional reasoning are two core aspirations in generative AI. Measuring the extent of these behaviors requires principled evaluation methods. We explore a unified perspective that considers both behaviors simultaneously, termed compositional causal reasoning (CCR): the ability to infer how causal measures compose and, equivalently, how causal quantities propagate through graphs. We instantiate a framework for the systematic evaluation of CCR for the average treatment effect and the probability of necessity and sufficiency. As proof of concept, we demonstrate the design of CCR tasks for language models in the LLama, Phi, and GPT families. On a math word problem, our framework revealed a range of taxonomically distinct error patterns. Additionally, CCR errors increased with the complexity of causal paths for all models except o1.
JoLT: Joint Probabilistic Predictions on Tabular Data Using LLMs
Feb 17, 2025We introduce a simple method for probabilistic predictions on tabular data based on Large Language Models (LLMs) called JoLT (Joint LLM Process for Tabular data). JoLT uses the in-context learning capabilities of LLMs to define joint distributions over tabular data conditioned on user-specified side information about the problem, exploiting the vast repository of latent problem-relevant knowledge encoded in LLMs. JoLT defines joint distributions for multiple target variables with potentially heterogeneous data types without any data conversion, data preprocessing, special handling of missing data, or model training, making it accessible and efficient for practitioners. Our experiments show that JoLT outperforms competitive methods on low-shot single-target and multi-target tabular classification and regression tasks. Furthermore, we show that JoLT can automatically handle missing data and perform data imputation by leveraging textual side information. We argue that due to its simplicity and generality, JoLT is an effective approach for a wide variety of real prediction problems.
AIRIVA: A Deep Generative Model of Adaptive Immune Repertoires
Apr 26, 2023



Recent advances in immunomics have shown that T-cell receptor (TCR) signatures can accurately predict active or recent infection by leveraging the high specificity of TCR binding to disease antigens. However, the extreme diversity of the adaptive immune repertoire presents challenges in reliably identifying disease-specific TCRs. Population genetics and sequencing depth can also have strong systematic effects on repertoires, which requires careful consideration when developing diagnostic models. We present an Adaptive Immune Repertoire-Invariant Variational Autoencoder (AIRIVA), a generative model that learns a low-dimensional, interpretable, and compositional representation of TCR repertoires to disentangle such systematic effects in repertoires. We apply AIRIVA to two infectious disease case-studies: COVID-19 (natural infection and vaccination) and the Herpes Simplex Virus (HSV-1 and HSV-2), and empirically show that we can disentangle the individual disease signals. We further demonstrate AIRIVA's capability to: learn from unlabelled samples; generate in-silico TCR repertoires by intervening on the latent factors; and identify disease-associated TCRs validated using TCR annotations from external assay data.
Invariant Priors for Bayesian Quadrature
Dec 02, 2021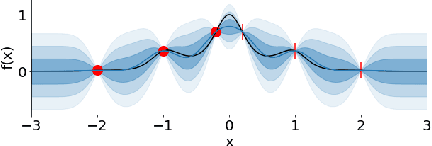
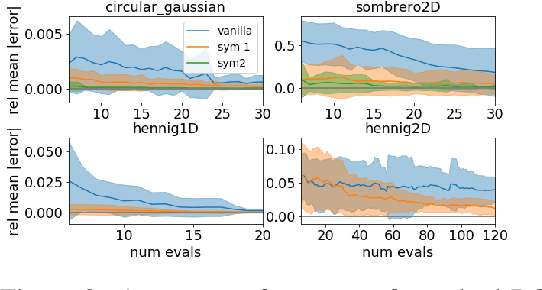
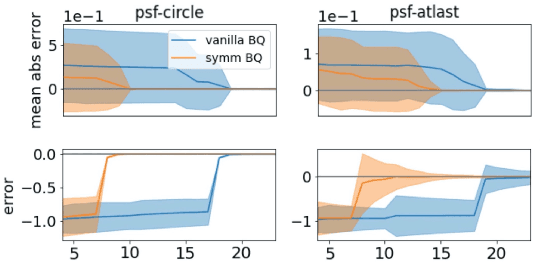
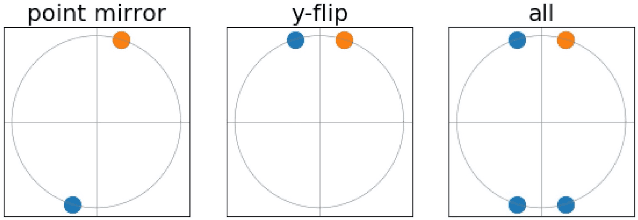
Bayesian quadrature (BQ) is a model-based numerical integration method that is able to increase sample efficiency by encoding and leveraging known structure of the integration task at hand. In this paper, we explore priors that encode invariance of the integrand under a set of bijective transformations in the input domain, in particular some unitary transformations, such as rotations, axis-flips, or point symmetries. We show initial results on superior performance in comparison to standard Bayesian quadrature on several synthetic and one real world application.
Emulation of physical processes with Emukit
Oct 25, 2021
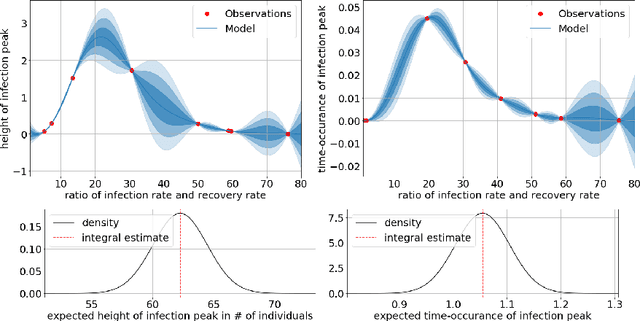
Decision making in uncertain scenarios is an ubiquitous challenge in real world systems. Tools to deal with this challenge include simulations to gather information and statistical emulation to quantify uncertainty. The machine learning community has developed a number of methods to facilitate decision making, but so far they are scattered in multiple different toolkits, and generally rely on a fixed backend. In this paper, we present Emukit, a highly adaptable Python toolkit for enriching decision making under uncertainty. Emukit allows users to: (i) use state of the art methods including Bayesian optimization, multi-fidelity emulation, experimental design, Bayesian quadrature and sensitivity analysis; (ii) easily prototype new decision making methods for new problems. Emukit is agnostic to the underlying modeling framework and enables users to use their own custom models. We show how Emukit can be used on three exemplary case studies.
RKHS-SHAP: Shapley Values for Kernel Methods
Oct 18, 2021
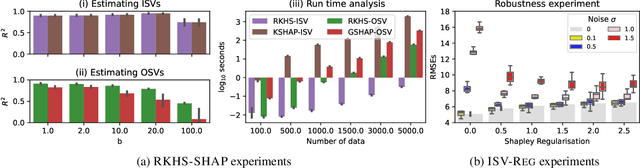

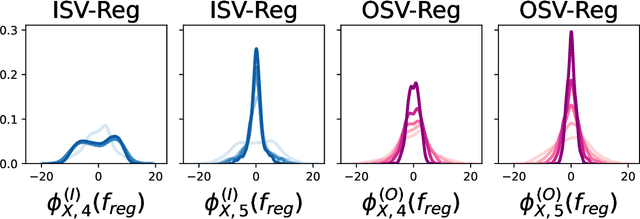
Feature attribution for kernel methods is often heuristic and not individualised for each prediction. To address this, we turn to the concept of Shapley values, a coalition game theoretical framework that has previously been applied to different machine learning model interpretation tasks, such as linear models, tree ensembles and deep networks. By analysing Shapley values from a functional perspective, we propose \textsc{RKHS-SHAP}, an attribution method for kernel machines that can efficiently compute both \emph{Interventional} and \emph{Observational Shapley values} using kernel mean embeddings of distributions. We show theoretically that our method is robust with respect to local perturbations - a key yet often overlooked desideratum for interpretability. Further, we propose \emph{Shapley regulariser}, applicable to a general empirical risk minimisation framework, allowing learning while controlling the level of specific feature's contributions to the model. We demonstrate that the Shapley regulariser enables learning which is robust to covariate shift of a given feature and fair learning which controls the Shapley values of sensitive features.
GIBBON: General-purpose Information-Based Bayesian OptimisatioN
Feb 05, 2021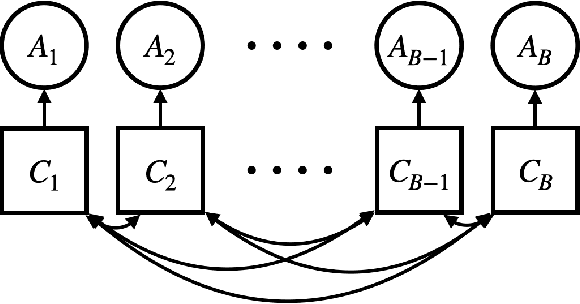

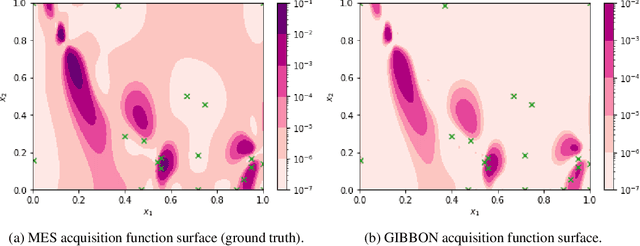
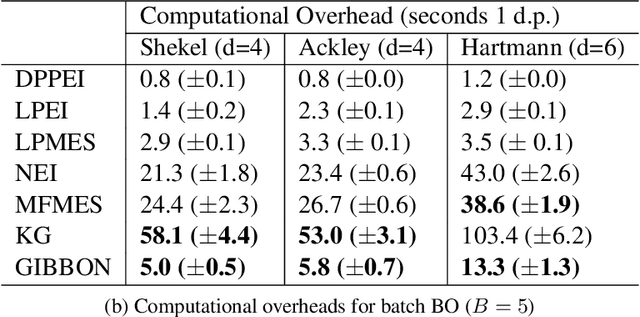
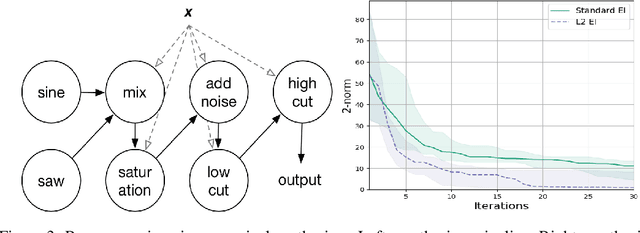
This paper describes a general-purpose extension of max-value entropy search, a popular approach for Bayesian Optimisation (BO). A novel approximation is proposed for the information gain -- an information-theoretic quantity central to solving a range of BO problems, including noisy, multi-fidelity and batch optimisations across both continuous and highly-structured discrete spaces. Previously, these problems have been tackled separately within information-theoretic BO, each requiring a different sophisticated approximation scheme, except for batch BO, for which no computationally-lightweight information-theoretic approach has previously been proposed. GIBBON (General-purpose Information-Based Bayesian OptimisatioN) provides a single principled framework suitable for all the above, out-performing existing approaches whilst incurring substantially lower computational overheads. In addition, GIBBON does not require the problem's search space to be Euclidean and so is the first high-performance yet computationally light-weight acquisition function that supports batch BO over general highly structured input spaces like molecular search and gene design. Moreover, our principled derivation of GIBBON yields a natural interpretation of a popular batch BO heuristic based on determinantal point processes. Finally, we analyse GIBBON across a suite of synthetic benchmark tasks, a molecular search loop, and as part of a challenging batch multi-fidelity framework for problems with controllable experimental noise.