 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Prompting for Arabic Essay Proficiency: A Trait-Centric Evaluation Approach
Mar 20, 2026This paper presents a novel prompt engineering framework for trait specific Automatic Essay Scoring (AES) in Arabic, leveraging large language models (LLMs) under zero-shot and few-shot configurations. Addressing the scarcity of scalable, linguistically informed AES tools for Arabic, we introduce a three-tier prompting strategy (standard, hybrid, and rubric-guided) that guides LLMs in evaluating distinct language proficiency traits such as organization, vocabulary, development, and style. The hybrid approach simulates multi-agent evaluation with trait specialist raters, while the rubric-guided method incorporates scored exemplars to enhance model alignment. In zero and few-shot settings, we evaluate eight LLMs on the QAES dataset, the first publicly available Arabic AES resource with trait level annotations. Experimental results using Quadratic Weighted Kappa (QWK) and Confidence Intervals show that Fanar-1-9B-Instruct achieves the highest trait level agreement in both zero and few-shot prompting (QWK = 0.28 and CI = 0.41), with rubric-guided prompting yielding consistent gains across all traits and models. Discourse-level traits such as Development and Style showed the greatest improvements. These findings confirm that structured prompting, not model scale alone, enables effective AES in Arabic. Our study presents the first comprehensive framework for proficiency oriented Arabic AES and sets the foundation for scalable assessment in low resource educational contexts.
* 13 pages
Creating a Hybrid Rule and Neural Network Based Semantic Tagger using Silver Standard Data: the PyMUSAS framework for Multilingual Semantic Annotation
Jan 14, 2026Word Sense Disambiguation (WSD) has been widely evaluated using the semantic frameworks of WordNet, BabelNet, and the Oxford Dictionary of English. However, for the UCREL Semantic Analysis System (USAS) framework, no open extensive evaluation has been performed beyond lexical coverage or single language evaluation. In this work, we perform the largest semantic tagging evaluation of the rule based system that uses the lexical resources in the USAS framework covering five different languages using four existing datasets and one novel Chinese dataset. We create a new silver labelled English dataset, to overcome the lack of manually tagged training data, that we train and evaluate various mono and multilingual neural models in both mono and cross-lingual evaluation setups with comparisons to their rule based counterparts, and show how a rule based system can be enhanced with a neural network model. The resulting neural network models, including the data they were trained on, the Chinese evaluation dataset, and all of the code have been released as open resources.
HealthcareNLP: where are we and what is next?
Dec 09, 2025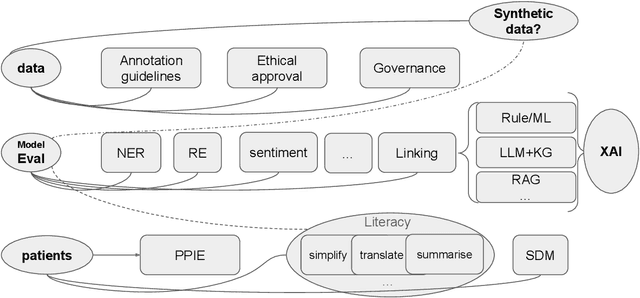
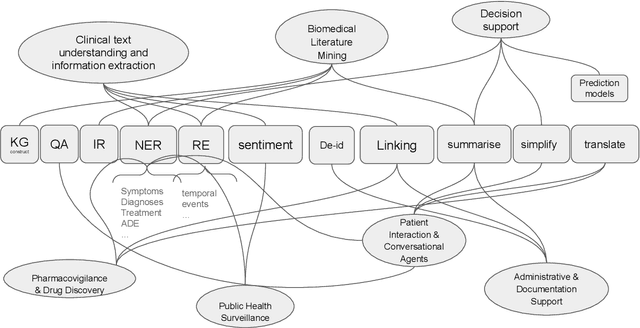
This proposed tutorial focuses on Healthcare Domain Applications of NLP, what we have achieved around HealthcareNLP, and the challenges that lie ahead for the future. Existing reviews in this domain either overlook some important tasks, such as synthetic data generation for addressing privacy concerns, or explainable clinical NLP for improved integration and implementation, or fail to mention important methodologies, including retrieval augmented generation and the neural symbolic integration of LLMs and KGs. In light of this, the goal of this tutorial is to provide an introductory overview of the most important sub-areas of a patient- and resource-oriented HealthcareNLP, with three layers of hierarchy: data/resource layer: annotation guidelines, ethical approvals, governance, synthetic data; NLP-Eval layer: NLP tasks such as NER, RE, sentiment analysis, and linking/coding with categorised methods, leading to explainable HealthAI; patients layer: Patient Public Involvement and Engagement (PPIE), health literacy, translation, simplification, and summarisation (also NLP tasks), and shared decision-making support. A hands-on session will be included in the tutorial for the audience to use HealthcareNLP applications. The target audience includes NLP practitioners in the healthcare application domain, NLP researchers who are interested in domain applications, healthcare researchers, and students from NLP fields. The type of tutorial is "Introductory to CL/NLP topics (HealthcareNLP)" and the audience does not need prior knowledge to attend this. Tutorial materials: https://github.com/4dpicture/HealthNLP
Overview of the First Workshop on Language Models for Low-Resource Languages (LoResLM 2025)
Dec 20, 2024


The first Workshop on Language Models for Low-Resource Languages (LoResLM 2025) was held in conjunction with the 31st International Conference on Computational Linguistics (COLING 2025) in Abu Dhabi, United Arab Emirates. This workshop mainly aimed to provide a forum for researchers to share and discuss their ongoing work on language models (LMs) focusing on low-resource languages, following the recent advancements in neural language models and their linguistic biases towards high-resource languages. LoResLM 2025 attracted notable interest from the natural language processing (NLP) community, resulting in 35 accepted papers from 52 submissions. These contributions cover a broad range of low-resource languages from eight language families and 13 diverse research areas, paving the way for future possibilities and promoting linguistic inclusivity in NLP.
A Comparative Study on Automatic Coding of Medical Letters with Explainability
Jul 18, 2024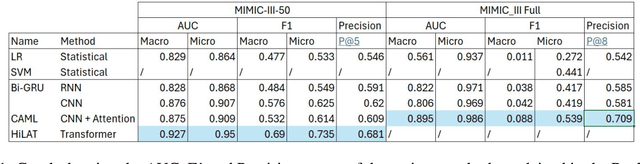
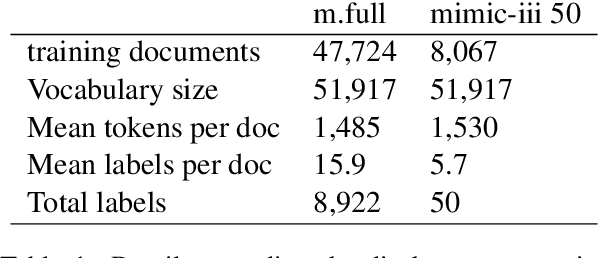
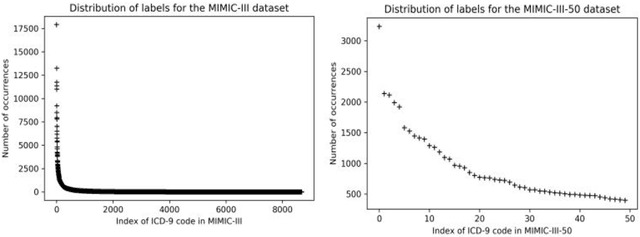

This study aims to explore the implementation of Natural Language Processing (NLP) and machine learning (ML) techniques to automate the coding of medical letters with visualised explainability and light-weighted local computer settings. Currently in clinical settings, coding is a manual process that involves assigning codes to each condition, procedure, and medication in a patient's paperwork (e.g., 56265001 heart disease using SNOMED CT code). There are preliminary research on automatic coding in this field using state-of-the-art ML models; however, due to the complexity and size of the models, the real-world deployment is not achieved. To further facilitate the possibility of automatic coding practice, we explore some solutions in a local computer setting; in addition, we explore the function of explainability for transparency of AI models. We used the publicly available MIMIC-III database and the HAN/HLAN network models for ICD code prediction purposes. We also experimented with the mapping between ICD and SNOMED CT knowledge bases. In our experiments, the models provided useful information for 97.98\% of codes. The result of this investigation can shed some light on implementing automatic clinical coding in practice, such as in hospital settings, on the local computers used by clinicians , project page \url{https://github.com/Glenj01/Medical-Coding}.
The IgboAPI Dataset: Empowering Igbo Language Technologies through Multi-dialectal Enrichment
May 02, 2024

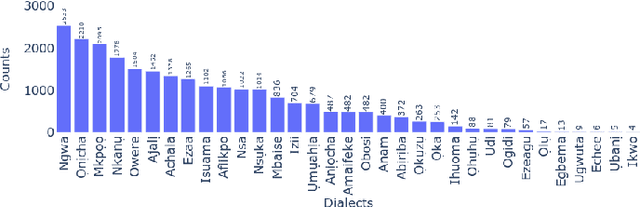
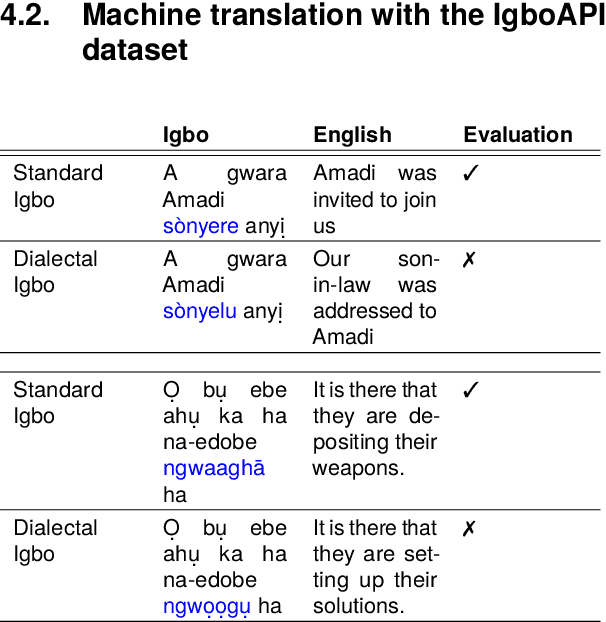
The Igbo language is facing a risk of becoming endangered, as indicated by a 2025 UNESCO study. This highlights the need to develop language technologies for Igbo to foster communication, learning and preservation. To create robust, impactful, and widely adopted language technologies for Igbo, it is essential to incorporate the multi-dialectal nature of the language. The primary obstacle in achieving dialectal-aware language technologies is the lack of comprehensive dialectal datasets. In response, we present the IgboAPI dataset, a multi-dialectal Igbo-English dictionary dataset, developed with the aim of enhancing the representation of Igbo dialects. Furthermore, we illustrate the practicality of the IgboAPI dataset through two distinct studies: one focusing on Igbo semantic lexicon and the other on machine translation. In the semantic lexicon project, we successfully establish an initial Igbo semantic lexicon for the Igbo semantic tagger, while in the machine translation study, we demonstrate that by finetuning existing machine translation systems using the IgboAPI dataset, we significantly improve their ability to handle dialectal variations in sentences.
Understanding who uses Reddit: Profiling individuals with a self-reported bipolar disorder diagnosis
Apr 23, 2021
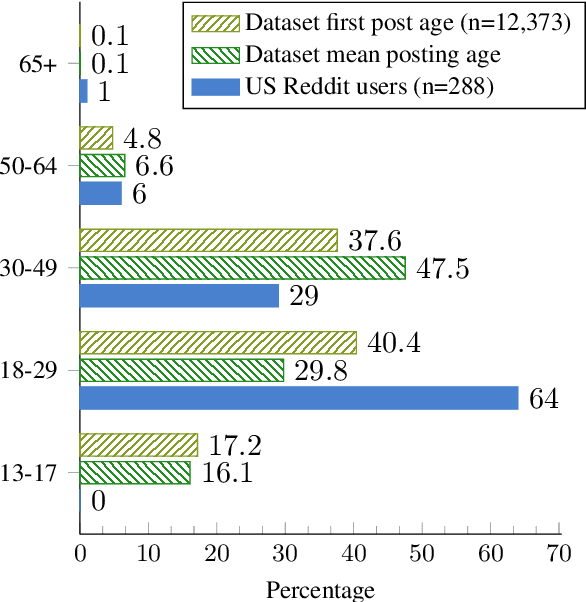
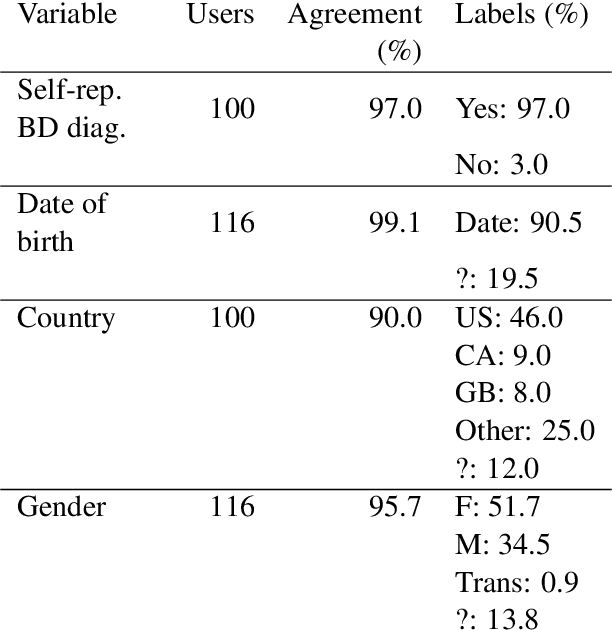
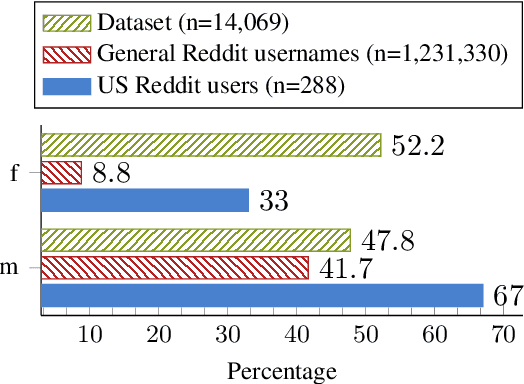
Recently, research on mental health conditions using public online data, including Reddit, has surged in NLP and health research but has not reported user characteristics, which are important to judge generalisability of findings. This paper shows how existing NLP methods can yield information on clinical, demographic, and identity characteristics of almost 20K Reddit users who self-report a bipolar disorder diagnosis. This population consists of slightly more feminine- than masculine-gendered mainly young or middle-aged US-based adults who often report additional mental health diagnoses, which is compared with general Reddit statistics and epidemiological studies. Additionally, this paper carefully evaluates all methods and discusses ethical issues.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021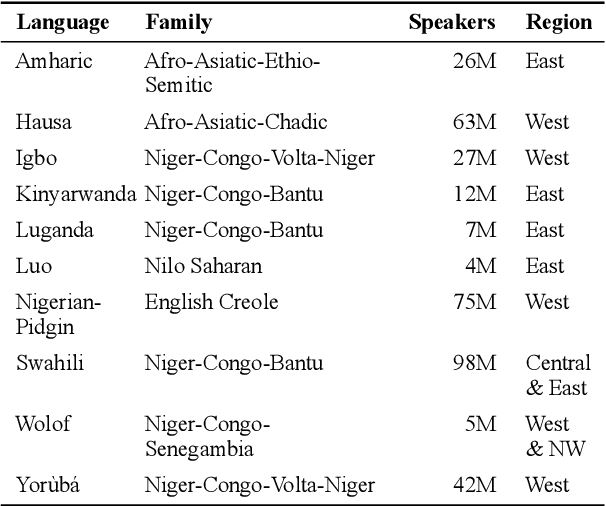

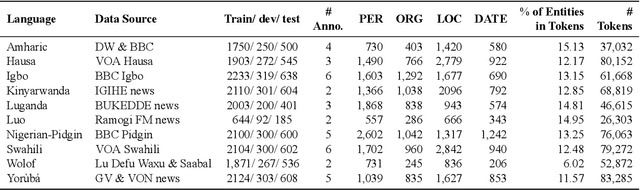
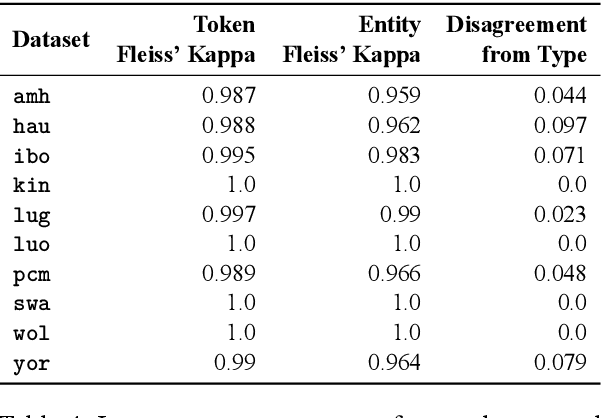
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.
GIBBON: General-purpose Information-Based Bayesian OptimisatioN
Feb 05, 2021

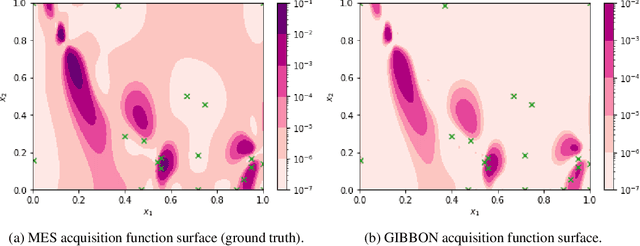
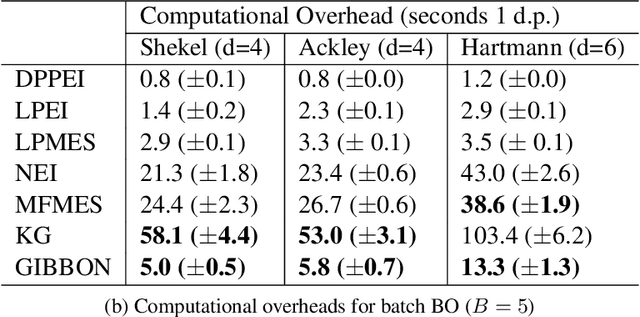
This paper describes a general-purpose extension of max-value entropy search, a popular approach for Bayesian Optimisation (BO). A novel approximation is proposed for the information gain -- an information-theoretic quantity central to solving a range of BO problems, including noisy, multi-fidelity and batch optimisations across both continuous and highly-structured discrete spaces. Previously, these problems have been tackled separately within information-theoretic BO, each requiring a different sophisticated approximation scheme, except for batch BO, for which no computationally-lightweight information-theoretic approach has previously been proposed. GIBBON (General-purpose Information-Based Bayesian OptimisatioN) provides a single principled framework suitable for all the above, out-performing existing approaches whilst incurring substantially lower computational overheads. In addition, GIBBON does not require the problem's search space to be Euclidean and so is the first high-performance yet computationally light-weight acquisition function that supports batch BO over general highly structured input spaces like molecular search and gene design. Moreover, our principled derivation of GIBBON yields a natural interpretation of a popular batch BO heuristic based on determinantal point processes. Finally, we analyse GIBBON across a suite of synthetic benchmark tasks, a molecular search loop, and as part of a challenging batch multi-fidelity framework for problems with controllable experimental noise.
The National Corpus of Contemporary Welsh: Project Report | Y Corpws Cenedlaethol Cymraeg Cyfoes: Adroddiad y Prosiect
Oct 12, 2020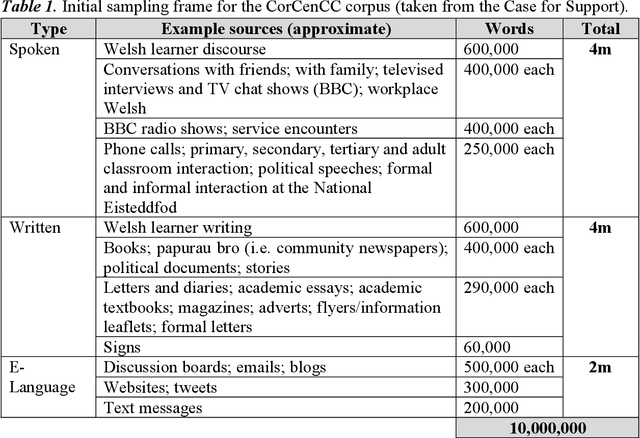
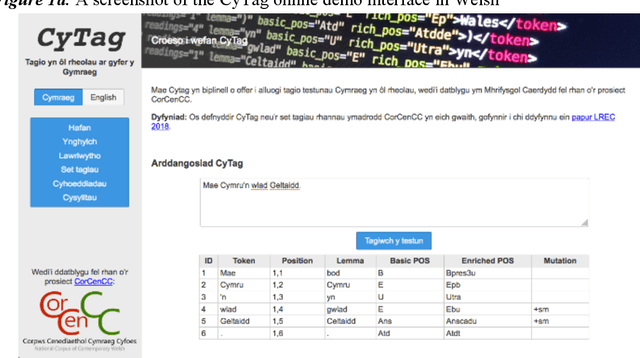
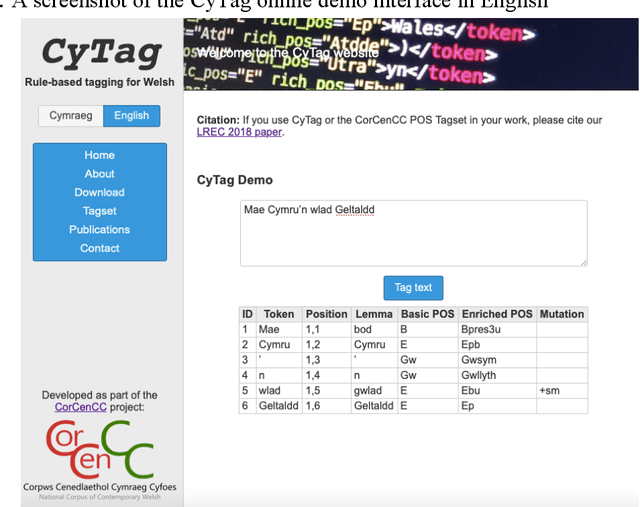
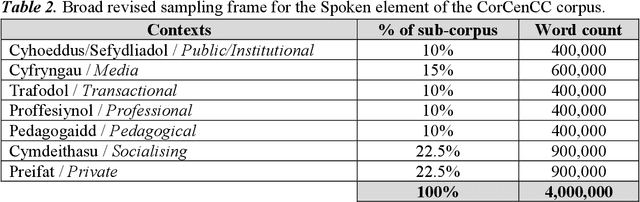
This report provides an overview of the CorCenCC project and the online corpus resource that was developed as a result of work on the project. The report lays out the theoretical underpinnings of the research, demonstrating how the project has built on and extended this theory. We also raise and discuss some of the key operational questions that arose during the course of the project, outlining the ways in which they were answered, the impact of these decisions on the resource that has been produced and the longer-term contribution they will make to practices in corpus-building. Finally, we discuss some of the applications and the utility of the work, outlining the impact that CorCenCC is set to have on a range of different individuals and user groups.