 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating a Hybrid Rule and Neural Network Based Semantic Tagger using Silver Standard Data: the PyMUSAS framework for Multilingual Semantic Annotation
Jan 14, 2026Word Sense Disambiguation (WSD) has been widely evaluated using the semantic frameworks of WordNet, BabelNet, and the Oxford Dictionary of English. However, for the UCREL Semantic Analysis System (USAS) framework, no open extensive evaluation has been performed beyond lexical coverage or single language evaluation. In this work, we perform the largest semantic tagging evaluation of the rule based system that uses the lexical resources in the USAS framework covering five different languages using four existing datasets and one novel Chinese dataset. We create a new silver labelled English dataset, to overcome the lack of manually tagged training data, that we train and evaluate various mono and multilingual neural models in both mono and cross-lingual evaluation setups with comparisons to their rule based counterparts, and show how a rule based system can be enhanced with a neural network model. The resulting neural network models, including the data they were trained on, the Chinese evaluation dataset, and all of the code have been released as open resources.
Introducing the Welsh Text Summarisation Dataset and Baseline Systems
May 05, 2022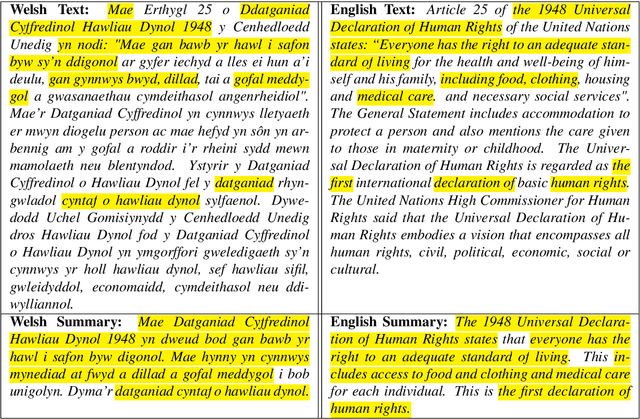
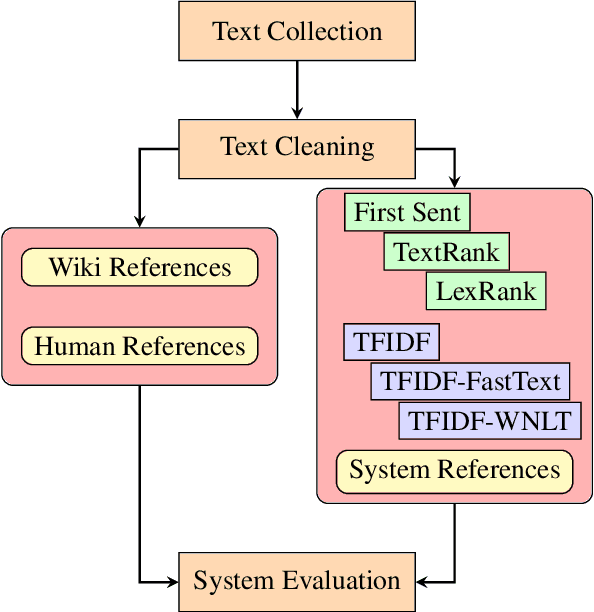
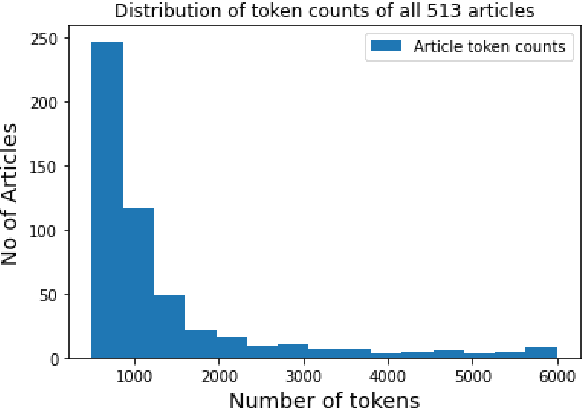

Welsh is an official language in Wales and is spoken by an estimated 884,300 people (29.2% of the population of Wales). Despite this status and estimated increase in speaker numbers since the last (2011) census, Welsh remains a minority language undergoing revitalization and promotion by Welsh Government and relevant stakeholders. As part of the effort to increase the availability of Welsh digital technology, this paper introduces the first Welsh summarisation dataset, which we provide freely for research purposes to help advance the work on Welsh text summarization. The dataset was created by Welsh speakers by manually summarising Welsh Wikipedia articles. In addition, the paper discusses the implementation and evaluation of different summarisation systems for Welsh. The summarization systems and results will serve as benchmarks for the development of summarises in other minority language contexts.
The National Corpus of Contemporary Welsh: Project Report | Y Corpws Cenedlaethol Cymraeg Cyfoes: Adroddiad y Prosiect
Oct 12, 2020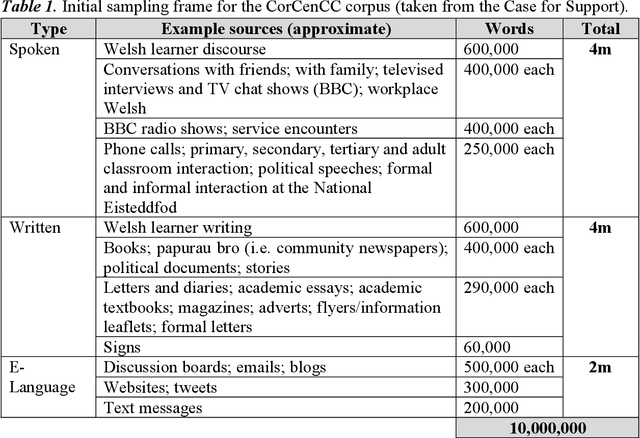
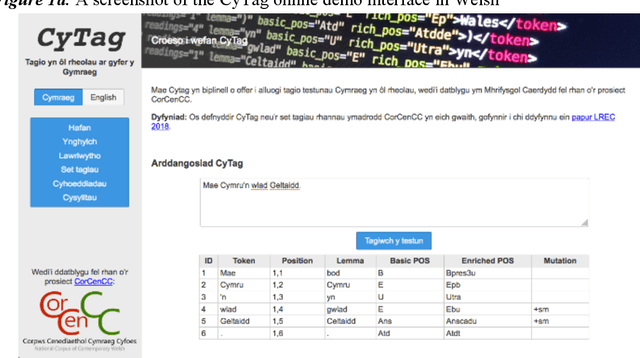
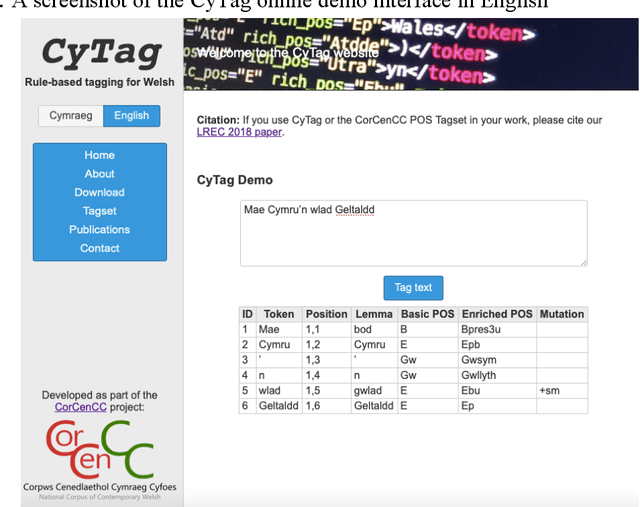
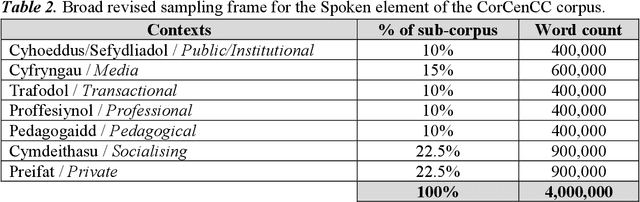
This report provides an overview of the CorCenCC project and the online corpus resource that was developed as a result of work on the project. The report lays out the theoretical underpinnings of the research, demonstrating how the project has built on and extended this theory. We also raise and discuss some of the key operational questions that arose during the course of the project, outlining the ways in which they were answered, the impact of these decisions on the resource that has been produced and the longer-term contribution they will make to practices in corpus-building. Finally, we discuss some of the applications and the utility of the work, outlining the impact that CorCenCC is set to have on a range of different individuals and user groups.