 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-driven Latent Semantic Analysis for Automatic Text Summarization using LDA Topic Modelling
Aug 02, 2022



With the advent and popularity of big data mining and huge text analysis in modern times, automated text summarization became prominent for extracting and retrieving important information from documents. This research investigates aspects of automatic text summarization from the perspectives of single and multiple documents. Summarization is a task of condensing huge text articles into short, summarized versions. The text is reduced in size for summarization purpose but preserving key vital information and retaining the meaning of the original document. This study presents the Latent Dirichlet Allocation (LDA) approach used to perform topic modelling from summarised medical science journal articles with topics related to genes and diseases. In this study, PyLDAvis web-based interactive visualization tool was used to visualise the selected topics. The visualisation provides an overarching view of the main topics while allowing and attributing deep meaning to the prevalence individual topic. This study presents a novel approach to summarization of single and multiple documents. The results suggest the terms ranked purely by considering their probability of the topic prevalence within the processed document using extractive summarization technique. PyLDAvis visualization describes the flexibility of exploring the terms of the topics' association to the fitted LDA model. The topic modelling result shows prevalence within topics 1 and 2. This association reveals that there is similarity between the terms in topic 1 and 2 in this study. The efficacy of the LDA and the extractive summarization methods were measured using Latent Semantic Analysis (LSA) and Recall-Oriented Understudy for Gisting Evaluation (ROUGE) metrics to evaluate the reliability and validity of the model.
Introducing the Welsh Text Summarisation Dataset and Baseline Systems
May 05, 2022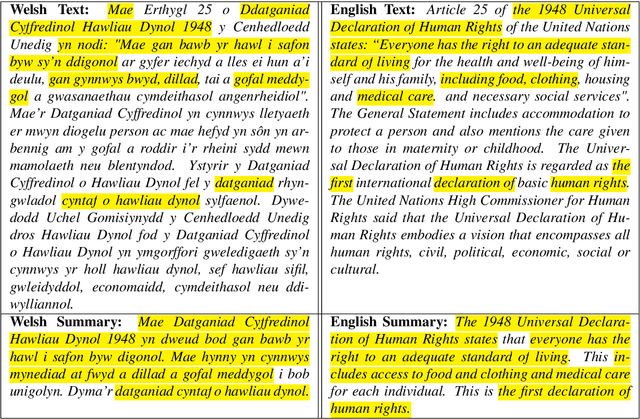
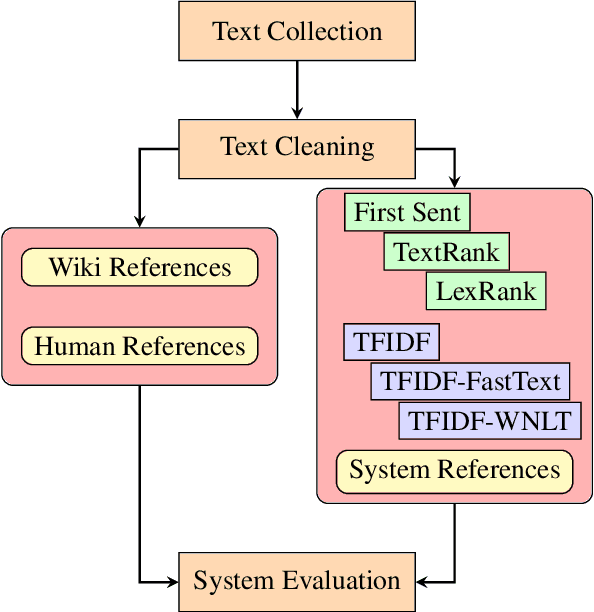
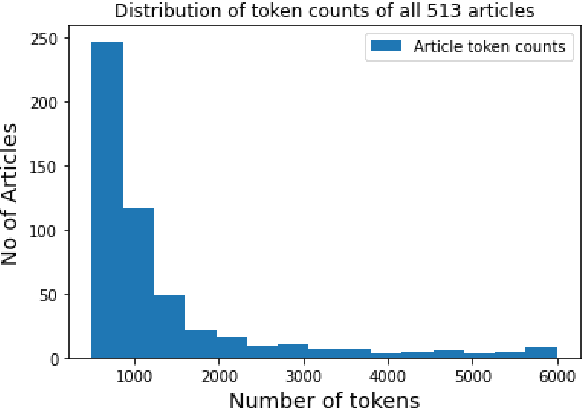

Welsh is an official language in Wales and is spoken by an estimated 884,300 people (29.2% of the population of Wales). Despite this status and estimated increase in speaker numbers since the last (2011) census, Welsh remains a minority language undergoing revitalization and promotion by Welsh Government and relevant stakeholders. As part of the effort to increase the availability of Welsh digital technology, this paper introduces the first Welsh summarisation dataset, which we provide freely for research purposes to help advance the work on Welsh text summarization. The dataset was created by Welsh speakers by manually summarising Welsh Wikipedia articles. In addition, the paper discusses the implementation and evaluation of different summarisation systems for Welsh. The summarization systems and results will serve as benchmarks for the development of summarises in other minority language contexts.
Financial Document Causality Detection Shared Task (FinCausal 2020)
Dec 04, 2020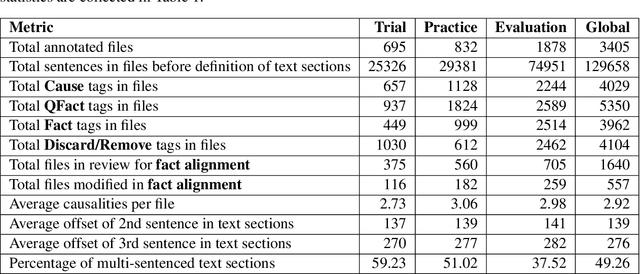



We present the FinCausal 2020 Shared Task on Causality Detection in Financial Documents and the associated FinCausal dataset, and discuss the participating systems and results. Two sub-tasks are proposed: a binary classification task (Task 1) and a relation extraction task (Task 2). A total of 16 teams submitted runs across the two Tasks and 13 of them contributed with a system description paper. This workshop is associated to the Joint Workshop on Financial Narrative Processing and MultiLing Financial Summarisation (FNP-FNS 2020), held at The 28th International Conference on Computational Linguistics (COLING'2020), Barcelona, Spain on September 12, 2020.
In Search of Meaning: Lessons, Resources and Next Steps for Computational Analysis of Financial Discourse
Mar 28, 2019
We critically assess mainstream accounting and finance research applying methods from computational linguistics (CL) to study financial discourse. We also review common themes and innovations in the literature and assess the incremental contributions of work applying CL methods over manual content analysis. Key conclusions emerging from our analysis are: (a) accounting and finance research is behind the curve in terms of CL methods generally and word sense disambiguation in particular; (b) implementation issues mean the proposed benefits of CL are often less pronounced than proponents suggest; (c) structural issues limit practical relevance; and (d) CL methods and high quality manual analysis represent complementary approaches to analyzing financial discourse. We describe four CL tools that have yet to gain traction in mainstream AF research but which we believe offer promising ways to enhance the study of meaning in financial discourse. The four tools are named entity recognition (NER), summarization, semantics and corpus linguistics.