 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interdisciplinary Perspective on Evaluation and Experimental Design for Visual Text Analytics: Position Paper
Sep 23, 2022
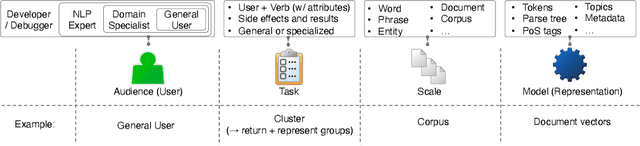
Appropriate evaluation and experimental design are fundamental for empirical sciences, particularly in data-driven fields. Due to the successes in computational modeling of languages, for instance, research outcomes are having an increasingly immediate impact on end users. As the gap in adoption by end users decreases, the need increases to ensure that tools and models developed by the research communities and practitioners are reliable, trustworthy, and supportive of the users in their goals. In this position paper, we focus on the issues of evaluating visual text analytics approaches. We take an interdisciplinary perspective from the visualization and natural language processing communities, as we argue that the design and validation of visual text analytics include concerns beyond computational or visual/interactive methods on their own. We identify four key groups of challenges for evaluating visual text analytics approaches (data ambiguity, experimental design, user trust, and "big picture'' concerns) and provide suggestions for research opportunities from an interdisciplinary perspective.
Characterizing Uncertainty in the Visual Text Analysis Pipeline
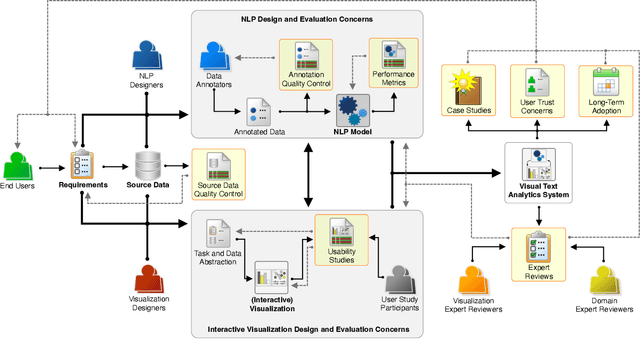
Sep 22, 2022Current visual text analysis approaches rely on sophisticated processing pipelines. Each step of such a pipeline potentially amplifies any uncertainties from the previous step. To ensure the comprehensibility and interoperability of the results, it is of paramount importance to clearly communicate the uncertainty not only of the output but also within the pipeline. In this paper, we characterize the sources of uncertainty along the visual text analysis pipeline. Within its three phases of labeling, modeling, and analysis, we identify six sources, discuss the type of uncertainty they create, and how they propagate.
Investigating the Effect of Emoji in Opinion Classification of Uzbek Movie Review Comments
Aug 02, 2020
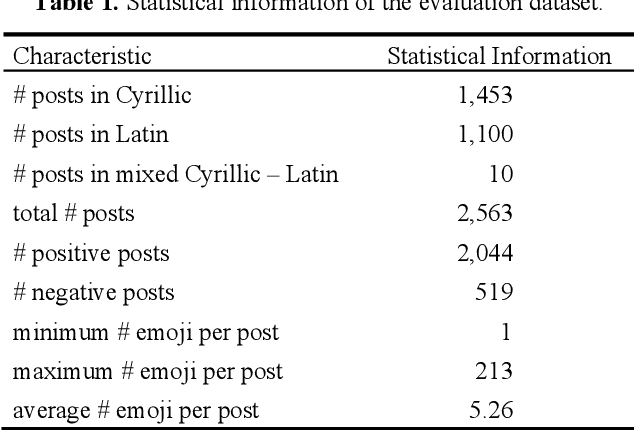
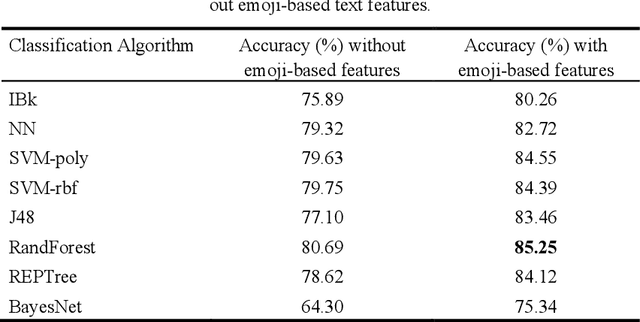

Opinion mining on social media posts has become more and more popular. Users often express their opinion on a topic not only with words but they also use image symbols such as emoticons and emoji. In this paper, we investigate the effect of emoji-based features in opinion classification of Uzbek texts, and more specifically movie review comments from YouTube. Several classification algorithms are tested, and feature ranking is performed to evaluate the discriminative ability of the emoji-based features.
In Search of Meaning: Lessons, Resources and Next Steps for Computational Analysis of Financial Discourse
Mar 28, 2019
We critically assess mainstream accounting and finance research applying methods from computational linguistics (CL) to study financial discourse. We also review common themes and innovations in the literature and assess the incremental contributions of work applying CL methods over manual content analysis. Key conclusions emerging from our analysis are: (a) accounting and finance research is behind the curve in terms of CL methods generally and word sense disambiguation in particular; (b) implementation issues mean the proposed benefits of CL are often less pronounced than proponents suggest; (c) structural issues limit practical relevance; and (d) CL methods and high quality manual analysis represent complementary approaches to analyzing financial discourse. We describe four CL tools that have yet to gain traction in mainstream AF research but which we believe offer promising ways to enhance the study of meaning in financial discourse. The four tools are named entity recognition (NER), summarization, semantics and corpus linguistics.