 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDealing with Abbreviations in the Slovenian Biographical Lexicon
Nov 04, 2022Abbreviations present a significant challenge for NLP systems because they cause tokenization and out-of-vocabulary errors. They can also make the text less readable, especially in reference printed books, where they are extensively used. Abbreviations are especially problematic in low-resource settings, where systems are less robust to begin with. In this paper, we propose a new method for addressing the problems caused by a high density of domain-specific abbreviations in a text. We apply this method to the case of a Slovenian biographical lexicon and evaluate it on a newly developed gold-standard dataset of 51 Slovenian biographies. Our abbreviation identification method performs significantly better than commonly used ad-hoc solutions, especially at identifying unseen abbreviations. We also propose and present the results of a method for expanding the identified abbreviations in context.
An Interdisciplinary Perspective on Evaluation and Experimental Design for Visual Text Analytics: Position Paper
Sep 23, 2022
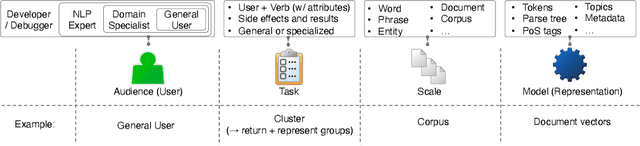
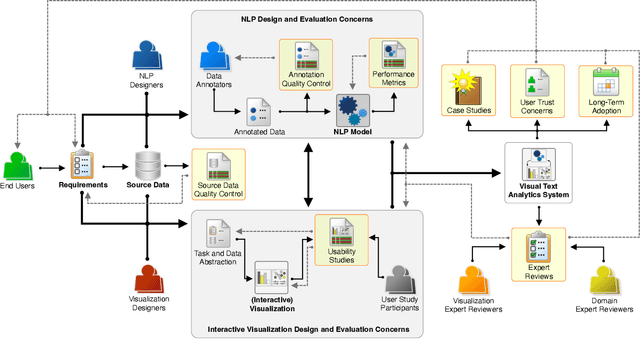
Appropriate evaluation and experimental design are fundamental for empirical sciences, particularly in data-driven fields. Due to the successes in computational modeling of languages, for instance, research outcomes are having an increasingly immediate impact on end users. As the gap in adoption by end users decreases, the need increases to ensure that tools and models developed by the research communities and practitioners are reliable, trustworthy, and supportive of the users in their goals. In this position paper, we focus on the issues of evaluating visual text analytics approaches. We take an interdisciplinary perspective from the visualization and natural language processing communities, as we argue that the design and validation of visual text analytics include concerns beyond computational or visual/interactive methods on their own. We identify four key groups of challenges for evaluating visual text analytics approaches (data ambiguity, experimental design, user trust, and "big picture'' concerns) and provide suggestions for research opportunities from an interdisciplinary perspective.
Weisfeiler-Leman in the BAMBOO: Novel AMR Graph Metrics and a Benchmark for AMR Graph Similarity
Aug 26, 2021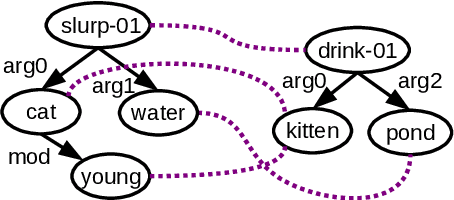
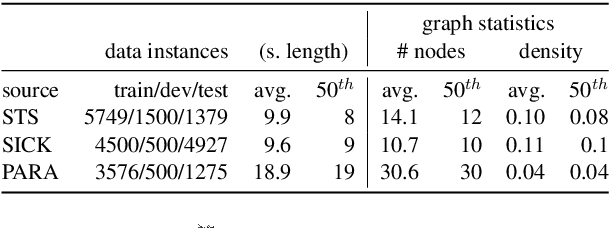
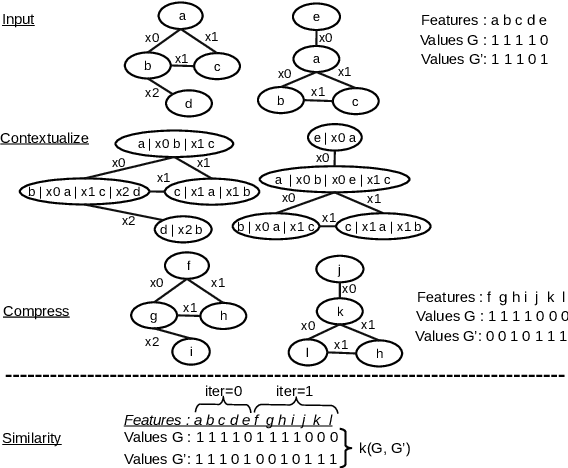

Several metrics have been proposed for assessing the similarity of (abstract) meaning representations (AMRs), but little is known about how they relate to human similarity ratings. Moreover, the current metrics have complementary strengths and weaknesses: some emphasize speed, while others make the alignment of graph structures explicit, at the price of a costly alignment step. In this work we propose new Weisfeiler-Leman AMR similarity metrics that unify the strengths of previous metrics, while mitigating their weaknesses. Specifically, our new metrics are able to match contextualized substructures and induce n:m alignments between their nodes. Furthermore, we introduce a Benchmark for AMR Metrics based on Overt Objectives (BAMBOO), the first benchmark to support empirical assessment of graph-based MR similarity metrics. BAMBOO maximizes the interpretability of results by defining multiple overt objectives that range from sentence similarity objectives to stress tests that probe a metric's robustness against meaning-altering and meaning-preserving graph transformations. We show the benefits of BAMBOO by profiling previous metrics and our own metrics. Results indicate that our novel metrics may serve as a strong baseline for future work.
X-SRL: A Parallel Cross-Lingual Semantic Role Labeling Dataset
Oct 05, 2020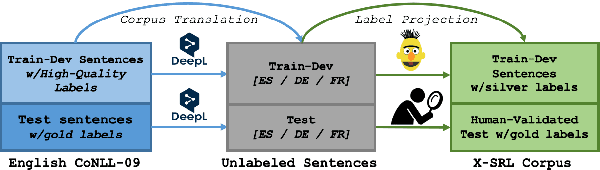

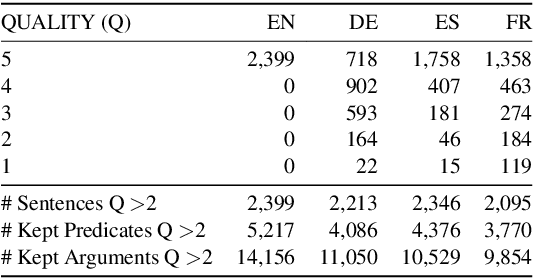
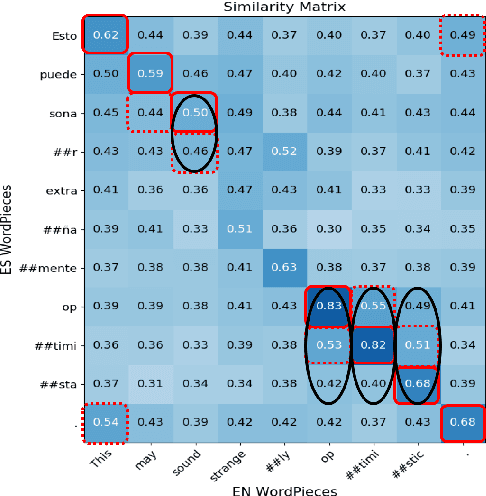
Even though SRL is researched for many languages, major improvements have mostly been obtained for English, for which more resources are available. In fact, existing multilingual SRL datasets contain disparate annotation styles or come from different domains, hampering generalization in multilingual learning. In this work, we propose a method to automatically construct an SRL corpus that is parallel in four languages: English, French, German, Spanish, with unified predicate and role annotations that are fully comparable across languages. We apply high-quality machine translation to the English CoNLL-09 dataset and use multilingual BERT to project its high-quality annotations to the target languages. We include human-validated test sets that we use to measure the projection quality, and show that projection is denser and more precise than a strong baseline. Finally, we train different SOTA models on our novel corpus for mono- and multilingual SRL, showing that the multilingual annotations improve performance especially for the weaker languages.
Translate and Label! An Encoder-Decoder Approach for Cross-lingual Semantic Role Labeling
Aug 29, 2019



We propose a Cross-lingual Encoder-Decoder model that simultaneously translates and generates sentences with Semantic Role Labeling annotations in a resource-poor target language. Unlike annotation projection techniques, our model does not need parallel data during inference time. Our approach can be applied in monolingual, multilingual and cross-lingual settings and is able to produce dependency-based and span-based SRL annotations. We benchmark the labeling performance of our model in different monolingual and multilingual settings using well-known SRL datasets. We then train our model in a cross-lingual setting to generate new SRL labeled data. Finally, we measure the effectiveness of our method by using the generated data to augment the training basis for resource-poor languages and perform manual evaluation to show that it produces high-quality sentences and assigns accurate semantic role annotations. Our proposed architecture offers a flexible method for leveraging SRL data in multiple languages.
A Sequence-to-Sequence Model for Semantic Role Labeling
Jul 09, 2018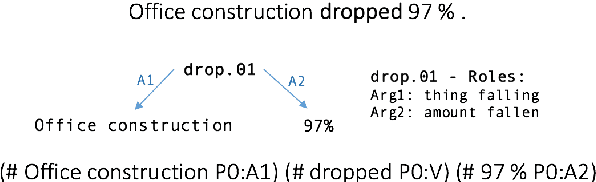



We explore a novel approach for Semantic Role Labeling (SRL) by casting it as a sequence-to-sequence process. We employ an attention-based model enriched with a copying mechanism to ensure faithful regeneration of the input sequence, while enabling interleaved generation of argument role labels. Here, we apply this model in a monolingual setting, performing PropBank SRL on English language data. The constrained sequence generation set-up enforced with the copying mechanism allows us to analyze the performance and special properties of the model on manually labeled data and benchmarking against state-of-the-art sequence labeling models. We show that our model is able to solve the SRL argument labeling task on English data, yet further structural decoding constraints will need to be added to make the model truly competitive. Our work represents a first step towards more advanced, generative SRL labeling setups.